4 Tärkeitä tuloksia (teoreemia)
Tässä kappaleessa todistamme pari tilastotieteessä hyvin tärkeää tulosta, rajoitetummassa muodossaan. Ensimmäisellä lukukerralla voit ohittaa todistukset ja katsoa pelkät teoreemalauseet, mutta itse todistuksetkin saattavat ajan myötä alkaa kiinnostamaan. Olen pyrkinyt tarjoamaan välineet niiden ymmärtämiseen edeltävässä tekstissä, mutta tulokset ovat syvällisiä ja saattavat edellyttää huomattavaakin pohdintaa yli yksittäistä kurssia pidempien ajanjaksojen. Toisinaan kuultu väittämä “tärkeät tulokset ovat yksinkertaisia” ei yksinkertaisesti pidä paikkaansa vaan on ennemmin toiveajattelua. Ihmiset toki tekevät paljon työtä yksinkertaistaakseen tärkeinä pitämiään tuloksia, kuten kirjoittaja tässäkin pyrkii tekemään. Tuloksista on olemassa vahvempia versioita, joiden todistaminen vaatisi kuitenkin huomattivasti enemmän matemaattista taustakoneistoa, eikä siten ole mielekästä tällä kurssilla. Teoreemien rajatumpienkin versioiden todistaminen antanee syvyyttä soveltajan osaamiseen.
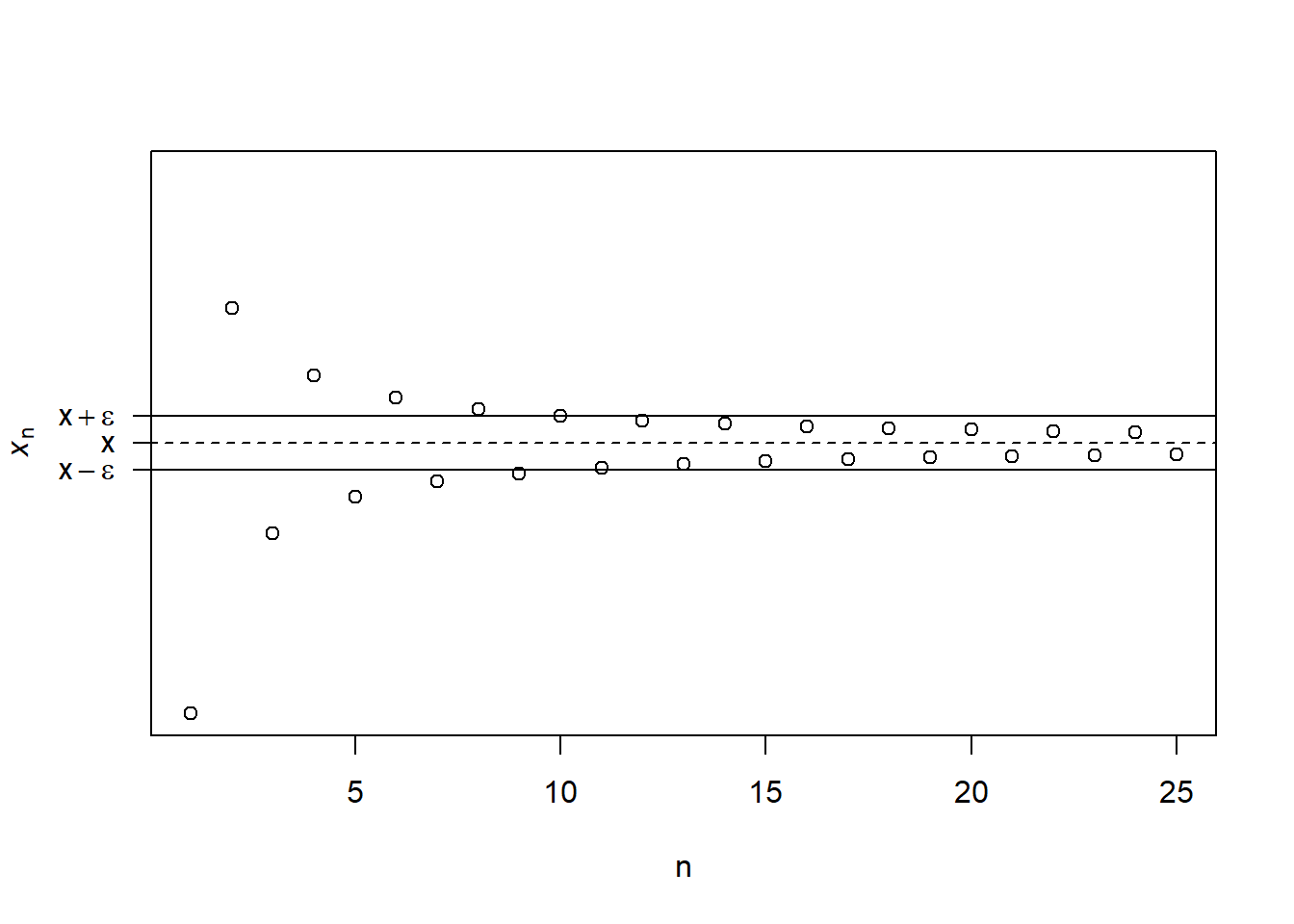
Koska asia on seuraavassa hyvin keskeinen, tarkastellaan esitiedoiksi ensin tarkemmin jonon raja-arvon määritelmää. Merkintä \(\lim_{n \to \infty} x_n = x\) tarkoittaa, että seuraava pätee äärettömän pitkälle, mutta tarkasti määritellylle, lukujonolle \(x_1, x_2, \ldots\): jokaiselle mielivaltaiselle luvulle \(\epsilon > 0\) on osoitettavissa toinen mielivaltainen luku \(\delta > 0\), jolla \(|x_n - x| < \epsilon\) aina, kun \(n > \delta\). Toisin sanoen, \(x_n\):n ja raja-arvon \(x\) erotus voidaan tehdä mitä tahansa positiivista lukua pienemmäksi, jolloin erotuksen raja-arvon on siis oltava nolla. Havainnollistetaan asiaa jonolla \(-1, 1/2, -1/3, 1/4, \ldots\), joka voidaan määritellä \(\{(-1)^n \cdot \frac{1}{n} \}_{n=1}^{\infty}\). Riittävän suurella \(\delta\):n arvolla, loput koko nollan ympärillä pyörivästä jonosta saadaan minkä hyvänsä \(2 \epsilon\)-kokoisen “putken” sisään (vrt. ao. kuva). Koska tämä pätee mille tahansa nollaa suuremmalle arvolle \(\epsilon\), raja-erotuksen on pakko olla nolla, jottei synny loogista ristiriitaa. Todennäköisyysteoriassa muutamme eri tavoin yllä annettua määritelmää keventämällä joko “putken” rajojen tiukkuutta tai “y-akselia” johon putkea sovitetaan, mutta rajankäynnin periaate on muutoin sama.
4.1 Suurten lukujen laki
Suurten lukujen laki on tärkeä, koska se osoittaa keskiarvon olevan hyvä arvio taustalla vaikuttavan jakauman odotusarvoparametrille, sekä takaa ennustettavan keskiarvolopputuleman joillekin mahdollisesti hyvinkin satunnaisille tapahtumille. Esimerkiksi laskimme aiemmin, että nopanheiton odotusarvoinen silmäluku on \(3.5\), mutta yksittäistä noppaa heitettäessä jokainen silmäluku yhdestä kuuteen on aivan yhtä mahdollinen, todennäköisyyden ollessa 1/6. Kahden nopan heiton odotusarvoksi saimme \(3.5 + 3.5 = 7\), mutta silmäluvun 7 todennäköisyys kerran heitettäessä oli edelleen vain 1/6. Keskiarvon varianssi on kuitenkin pienentynyt. Koska \(\text{Cov}[X_{\text{noppa 1}}, X_{\text{noppa 2}}] = 0\), se on vain \(\text{Var}[\frac{1}{2}(X_{\text{noppa 1}} + X_{\text{noppa 2}})] = \frac{1}{2^2} \big\{ \text{Var}[X_{\text{noppa 1}}] + \text{Var}[X_{\text{noppa 2}}] \big\} = \frac{\sigma^2}{2}\), siinä missä \(\text{Var}[X_{\text{noppa 1}}] = \text{Var}[X_{\text{noppa 2}}] = \sigma^2\). Tätä ilmiötä ja sen variantteja on helppoa tietokoneella simuloida, esimerkiksi alla olevan kuvan tapaan. Simulaatiosta nähdään kuinka keskiarvo tarkentuu kohden teoreettista odotusarvoa otoskoon kasvaessa. Yksittäiset heittosarjat (värit) toki eroavat toisistaan, mutta enimmäkseen pienillä otoskoilla. Kun otoskoko lähestyy ääretöntä, kaikki kovergoituvat samaan lukuun \(3.5\).
set.seed(12358) # poista, jos haluat eri satunnaisluvut
n_max <- 1000 # viimeinen tarkasteltava otoskoko
# Luodaan nopan silmalukuja tasajakaumasta
dice_throw_indexes <- rmultinom(n = n_max, size = 1, prob = rep(1/6, 6))
dice_throws <- apply(dice_throw_indexes==1, 2, which)
# Lasketaan kaikki silmalukukeskiarvot kerralla ja piirretaan sarja
Xbars <- cumsum(dice_throws)/(1:n_max)
plot(Xbars, type = "l", lwd = 2, xlab = "n", ylab = "Keskiarvo", ylim = c(1, 6))
lines(c(-10, n_max+10), c(3.5, 3.5), lty = 2)
# Toistetaan samaa muutama kerta
for (i in 1:3){
dice_throw_indexes <- rmultinom(n = n_max, size = 1, prob = rep(1/6, 6))
dice_throws <- apply(dice_throw_indexes==1, 2, which)
Xbars <- cumsum(dice_throws)/(1:n_max)
lines(Xbars, lwd = 2, col = i+1)
}
legend("topright", legend = 1:4, title = "Heittosarja", col = 1:4, lwd = 2,
bty = "n")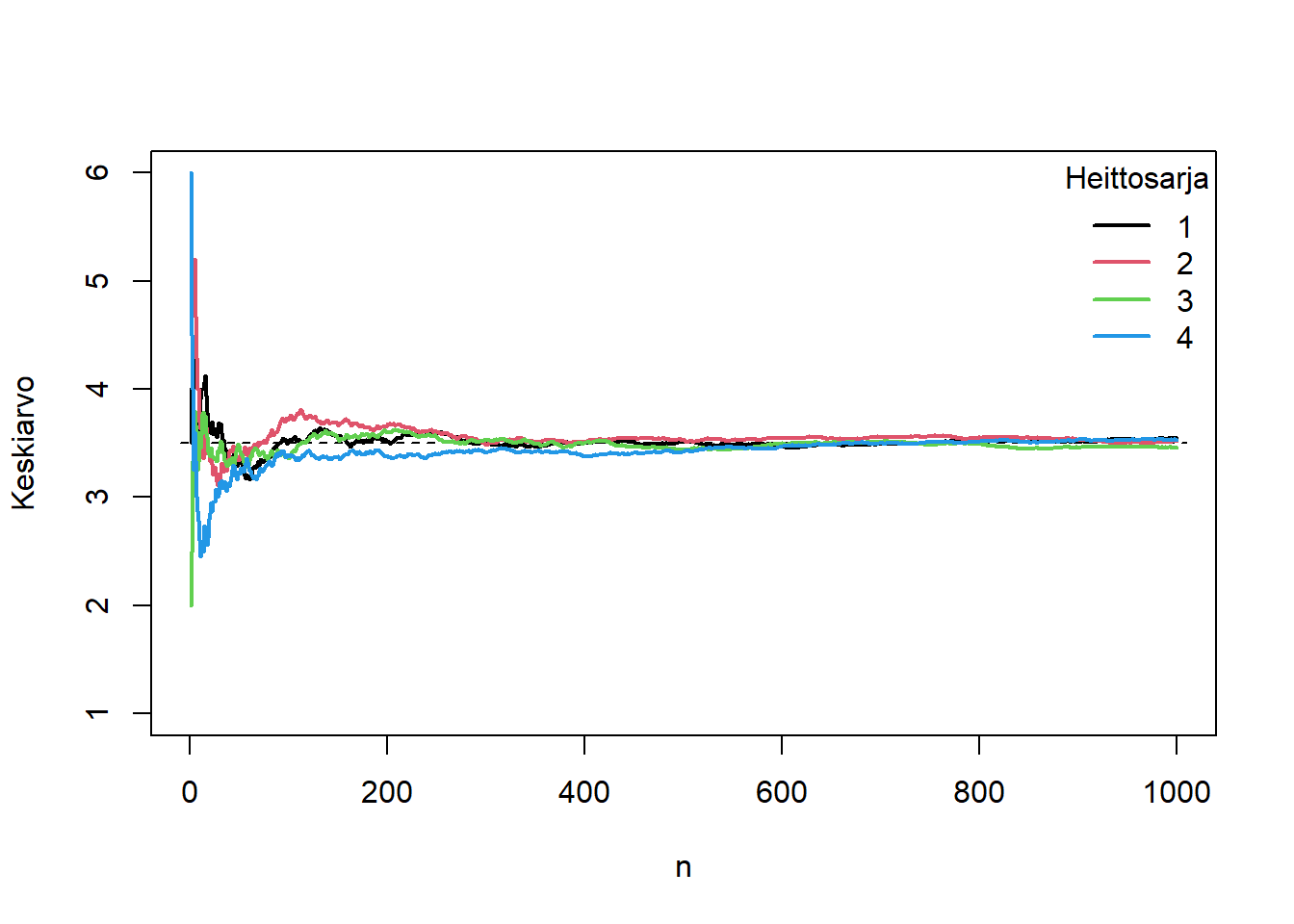
Yllä olevan simulaation voi tietysti tehdä myös oikeaa noppaa heittämällä, joskin siitä syntyy melkoisesti rutiininomaista summalaskentaa. Hedelmällisempää on todistaa taustalla olevan ilmiön yleinen periaate, jolloin kyseinen ymmärrys on ns. “kiveen kirjoitettu”. Teemme sen seuraavaksi.
Suurten lukujen laki (“heikko” versio). Kun \(X_1, X_2, \ldots, X_n\) ovat kokoelma identtisiä samalla tavoin jakautuneita toisistaan riippumattomia satunnaismuuttujia ja \(\text{E}[X_1]=\mu\), keskiarvomuuttujalle \(\bar{X}_n = \frac{1}{n} \sum_{i=1}^n X_i\), eli muuttujalle \(\bar{X}_n = \frac{1}{n}(X_1 + X_2 + \cdots + X_n)\), pätee \(\bar{X}_n \overset{P}{\to} \mu\), kun \(n \to \infty\). Toisin sanoen, keskiarvo \(\bar{X}_n\) lähestyy odotusarvoa otoksen kasvaessa siten, että mille tahansa positiiviselle luvulle \(\epsilon > 0\) pätee
\[ \lim_{n \to \infty} P(|\bar{X}_n - \mu| > \epsilon) = 0. \]
Todistus. Olkoon luku \(a > 0\) ja \(X\) satunnaismuuttuja, joka ei voi saada negatiivisia arvoja. Tällöin ns. Markovin epäyhtälö, \(P(X \ge a) \le \text{E}[X]/a\), osoitetaan toteen häikäilemättä kokonaistodennäköisyyttä alaspäin arvioimalla:
\[ \begin{aligned} \text{E}[X] &= P(X < a) \text{E}[X|X < a] + P(X \ge a) \text{E}[X|X \ge a] \\ &\ge P(X \ge a) \text{E}[X|X \ge a] \\ &\ge P(X \ge a) \times a, \end{aligned} \]
mistä yo. Markovin epäyhtälö saadaan puolittain \(a\):lla jakamalla. Epäyhtälö antaa siis ylärajan suurten arvojen todennäköisyyksille. Kun Markovin epäyhtälöä sovelletaan satunnaismuuttujaan \((X - \text{E}[X])^2\) ja vakioon \(a^2\) ja huomataan, että \(P((X - \text{E}[X])^2 \ge a^2) = P(|X - \text{E}[X]| \ge a)\) saadaan itseisarvopoikkeamien yläraja, joka tunnetaan Chebyshevin epäyhtälönä:
\[ P(|X - \text{E}[X]| \ge a) \le \frac{\text{Var}[X]}{a^2}. \]
Varianssin ominaisuuksista ja muuttujien \(X_1, X_2, \ldots, X_n\) riippumattomuudesta seuraa, että
\[ \begin{aligned} \text{Var}[\bar{X}_n] &= \frac{1}{n^2} \text{Var}[X_1 + X_2 + \cdots + X_n] \\ &= \frac{1}{n^2} \big\{ \sum_{i=1}^n \text{Var}[X_i] + 2 \sum_{i=1}^{n-1} \sum_{j=i+1}^n \underbrace{\text{Cov}[X_i, X_j]}_{= 0 \text{ when } i \ne j } \big\} \\ &= \frac{1}{n^2} \sum_{i=1}^n \text{Var}[X_i] \\ &= \frac{n \sigma^2}{n^2} \\ &= \sigma^2/n, \end{aligned} \]
missä \(\sigma^2 = \text{Var}[X_1] = \cdots = \text{Var}[X_n]\), koska muuttujille oletettiin samat jakaumat. Kun nyt otetaan mikä hyvänsä arvo \(\epsilon > 0\) ja käytetään Chebyshevin epäyhtälöä summamuuttujaan, saadaan
\[ P(|\bar{X}_n - \mu| > \epsilon) \le \frac{\sigma^2}{n \epsilon^2}, \]
missä pätee \(\frac{\sigma^2}{n \epsilon^2} \to 0\), kun \(n\) kasvaa rajatta. Tämä todistaa alkuperäisen väitteen.
Yllä paitsi osoitimme pitävästi, että otoskeskiarvo kaikella todennäköisyydellä konvergoi odotusarvoon, myös annoimme ylärajan \(\epsilon\):n kokoisen poikkeaman todennäköisyydelle. Esimerkiksi, yhden nopanheiton varianssiksi laskemme \(\frac{1}{6} \big\{ (1 - 3.5)^2 + (2 - 3.5)^2 + \cdots + (6 - 3.5)^2 \big\} \approx 2.9\). Yllä osoitimme, että keskiarvon yli yhden silmäluvun kokoisen poikkeaman odotusarvosta on oltava todennäköisyydeltään alle \(\frac{2.9}{n \times 1^2}\). Eli sadan heiton otoksessa alle \(0.029\). Tarkemmatkin arviot olisivat mahdollisia, mutta tässä esitelty menetelmä on varsin yleinen ja verrattain ymmärrettävä. Huomaa kuitenkin, että on olemassa satunnaismuuttujia, joiden varianssi tai jopa odotusarvo ovat määrittämättömiä (äärettömiä), jolloin yllä oleva todistus ei luonnollisestikaan toimi.
4.2 Keskeinen raja-arvolause
Yllä esitelty suurten lukujen laki ei riitä vastaamaan kysymyksiin “mikä on otoskeskiarvon jakauma” ja “riippuuko keskiarvon jakauma keskiarvoistettavien satunnaismuuttujien jakaumista”. Vastauksen tähän kysymykseen antaa seuraava lause.
Keskeinen raja-arvolause. Olkoon \(X_1, X_2, \ldots, X_n\) jono satunnaismuuttujia (otos; \(n\) kappaletta), joiden odotusarvo on \(\mu\) ja varianssi \(\sigma^2\), ja \(\bar{X}_n\) näiden keskiarvo. Silloin satunnaismuuttujan \(\sqrt{n}(\bar{X}_n - \mu)\) jakauma lähestyy otoskoon \(n\) kasvaessa jakaumaa \(N(0, \sigma^2)\), eli normaalijakaumaa, jonka varianssi on \(\sigma^2\).
Tämä tulos on äärimmäisen hyödyllinen, koska sen nojalla voimme tietää hyvin paljon keskiarvon jakaumasta tietämättä juuri mitään itse havaintojen jakaumasta. Tulos on siis hyvin yleinen ja varsin käyttökelpoinen. Se annettiin yllä tarkoituksella melko epämääräisessä muodossa, sillä keskeisestä raja-arvolauseesta on olemassa useita erilaisia versioita. Perinteisesti muuttujat \(X_1, X_2, \ldots, X_n\) oletetaan toisistaan riippumattomiksi, samoin jakautuneiksi, ja odotusarvoiltaan ja variansseiltaa äärellisiksi. Oletuksista kahta ensimmäistä voidaan kuitenkin väljentää tietyin hallituin tavoin, joihin ei tässä ole tarvetta syventyä. Jopa lauseen klassinen versio on itse asiassa varsin hankala todistaa. Sen todistus sivuutetaan tässä, mutta ymmärrystä teemaan haetaan todistamalla teoreemaan (ilmeisesti) kaikkein varhaisin versio. Tätä versiota kutsutaan De Moivre-Laplace teoreemaksi ja se todistaa, että aiemmassa kuvassa Figure 3.3 näkemämme Bernoulli-jakautuneiden satunnaismuuttujien (binomijakautuneen) summan jakauma todella lähestyy keskeisen raja-arvolauseen osoittamaa normaalijakaumaa.
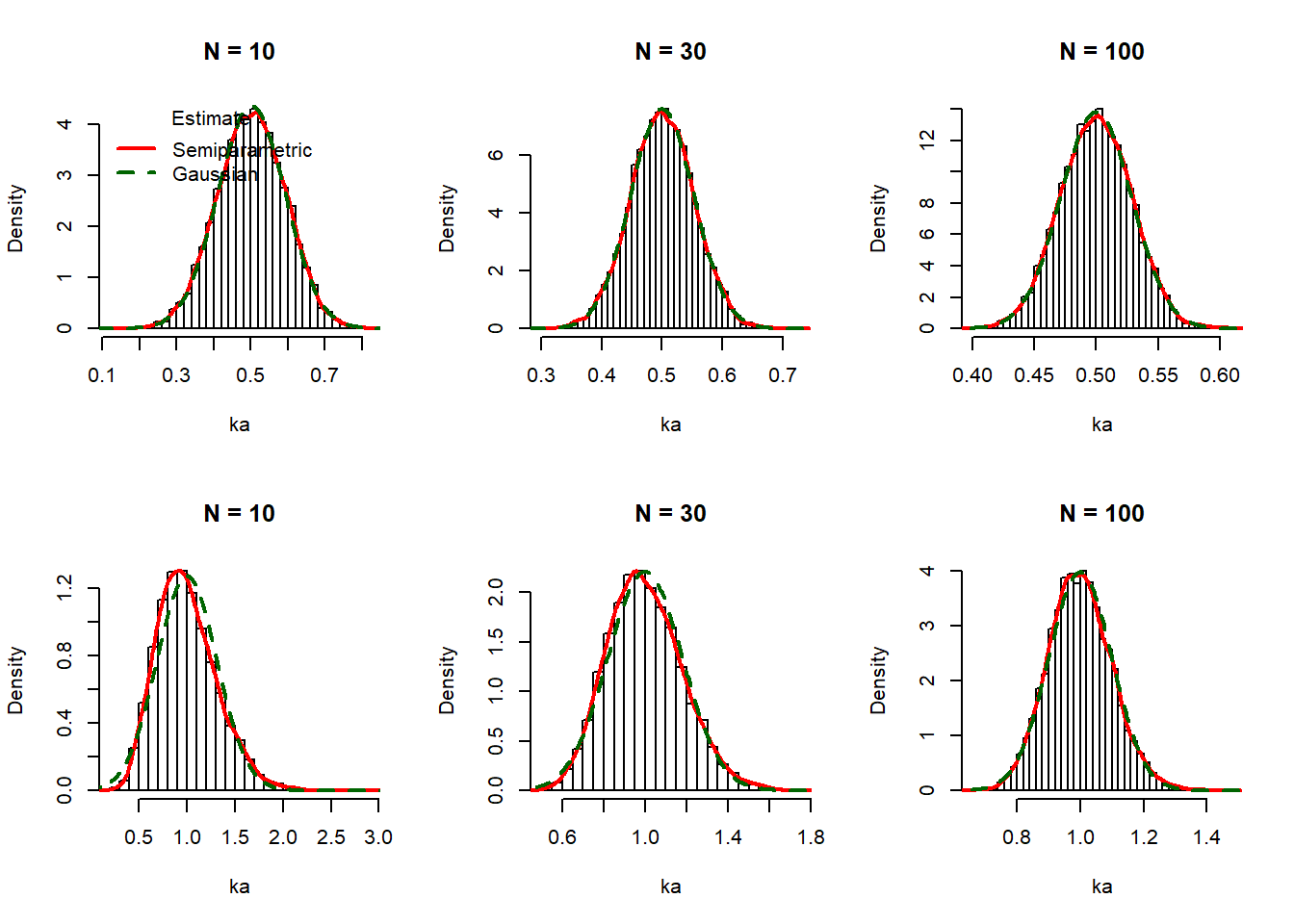
Tarkastellaan hetki keskeistä raja-arvolausetta ennen formaaleihin todisteluihin siirtymistä. Kyseessä on suurten lukujen teoriaan perustuva tulos, eli tulos toimii suurilla otoksilla, kun \(n\) on “suuri”. Se, mitä tarkoittaa “suuri”, riippuu keskiarvoistettavien satunnaismuuttujien alkuperäisistä jakaumista. Alla oleva R-simulaatio luo empiirisiä histogrammeja tasajakautuneiden (ylärivi) ja vinojen (alarivi; eksponenttijakauma) muuttujien keskiarvoille. Kuvasta nähdään, että jälkimmäisessa tapauksessa keskiarvon empiirinen jakauma (punainen viiva) lähestyy normaalista (vihreä katkoviiva) hitaammin kuin ensimmäisessä tapauksessa. Jo kymmenen tasajakautuneen havainnon keskiarvo on käytännössä normaalijakautunut, kun eksponenttijakauman kohdalla vielä sadallakin havainnolla havaitaan lievää vinoutta oikealle.
set.seed(12358) # poista tama rivi, jos haluat eri satunnaisluvut
ns <- c(10,30,100) # tarkasteltavat otoskoot (3 kpl)
nsim <- 10000 # toistojen määrä keskiarvon jakauman laskemista varten
ka_tasa <- matrix(0, nsim, length(ns)) # kootaan tasajakaumatulokset tahan
ka_expo <- matrix(0, nsim, length(ns)) # kootaan eksponenttijakaumatulokset
# simuloidaan
for (i in 1:nsim){
X_tasa <- runif(ns[length(ns)]) # tasajakautuneita havaintoja
X_expo <- rexp(ns[length(ns)]) # eksponenttijakautuneita havaintoja
ka_tasa[i, ] <- c(mean(X_tasa[1:ns[1]]), mean(X_tasa[1:ns[2]]), mean(X_tasa))
ka_expo[i, ] <- c(mean(X_expo[1:ns[1]]), mean(X_expo[1:ns[2]]), mean(X_expo))
}
# piirretaan kuvaajat
par(mfrow=c(2,3))
for (i in 1:3){ # tasajakaumien keskiarvot
hist(ka_tasa[,i], breaks = 30, freq = F, col = "white",
main = paste("N =", ns[i]), xlab = "ka")
x <- density(ka_tasa[,i]); lines(x$x, x$y, col = "red", lwd = 2)
x <- seq(-1, 4, length.out=1000)
lines(x, dnorm(x, mean = mean(ka_tasa[,i]), sd = sd(ka_tasa[,i])),
lty = 2, lwd = 2, col = "darkgreen")
if (i==1){
legend("topleft", bty = "n", lwd = 2, lty = c(1, 2),
col = c("red", "darkgreen"), title = "Estimate",
legend = c("Semiparametric", "Gaussian"))
}
}
for (i in 1:3){ # eksponenttijakaumien keskiarvot
hist(ka_expo[,i], breaks = 30, freq = F, col = "white",
main = paste("N =", ns[i]), xlab = "ka")
x <- density(ka_expo[,i]); lines(x$x, x$y, col = "red", lwd = 2)
x <- seq(-1, 4, length.out=1000)
lines(x, dnorm(x, mean = mean(ka_expo[,i]), sd = sd(ka_expo[,i])),
lty = 2, lwd = 2, col = "darkgreen")
}
Ylläolevan simulaation kaltaiset tarkastelut ovat erittäin hyödyllisiä keskiarvoa monimutkaisempian parametrien mallinnuksessa. Tuolloin voi olla huomattavasti suurempaa epävarmuutta estimaattorin jakaumasta, jos esimerkiksi osa estimointiyrityksistä epäonnistuu. Näimme kuitenkin yllä, että keskeinen raja-arvolause toimii käytönnössäkin ja melko nopeasti, eli jo melko pienin havaintomäärin.
4.2.1 DeMoivre-Laplace teoreema
Keskeisen raja-arvolauseen todistus vaatii melko paljon matemaattisia taustatietoja, mm. topologiaa ja mittateoriaa. Emme pysty tämän kurssin puitteessa mielekkäästi käymään läpi tuota todistusta. Jotta kuitenkin saavuttaisimme mahdollisimman hyvän ymmärryksen tähän hyvin keskeiseen teoriaan, todistamme sen yhdessä havainnollisessa erikoistapauksessa — edellä käsittelemämme binomijakauman tapauksessa. Tämä taitaakin olla varhaisin keskeisen raja-arvolauseen versio, joka tunnetaan mm. nimellä DeMoivre-Laplace [Central] Limit Theorem. Todistamme ensin lukio-opein, että binomijakauman tiheysfunktio rajalla lähestyy pisteittäin normaalijakauman tiheysfunktiota (Thamattoor 2018). Tämä helpohko todistus jättää kuitenkin avoimeksi sen, lähestyykö koko binomijakauma normaalijakaumaa otoskoon kasvaessa, kuten myös tilastotieteen kannalta varsin keskeisen lähestymisvauhdin (otoksethan ovat aina rajallisia käytännössä). Siksi käymme kappaleen lopuksi läpi myös pidemmän ja kattavamman todistuksen (Balázs and Tóth 2022). Varsinkin ensimmäisellä lukukerralla, voi olla mielekästä ohittaa pidempi todistus. Sen merkitys kuitenkin korostuu viimeistään luettaessa menetelmäkirjallisuuden “root-\(n\)”, eli “\(n\):n neliöjuuri” -estimaattoreista, mihin luokkaan valtaosa mielekkäistä tilastollisista estimaattoreista sijoittuu. Aloitetaan kuitenkin heuristisemmasta tarkastelusta. Geneerisen parametrisymbolin sijaan, käytämme seuraavassa binomijakauman klassisia lyhyitä parametrisymboleita, eli \(\theta = p\) ja \(1 - \theta = q\).
Pyrimme tässä lopulta osoittamaan, että binomijakauma \(f(n,k) = \binom{n}{k} p^k q^{n-k}\), missä \(n\) on yritysten lkm, \(k\) onnistumisten lkm ja \(p = 1 - q\) on onnistumisen todennäköisyys, lähestyy normaalijakaumaa \(\phi(x; \mu, \sigma) = (2 \pi \sigma^2)^{-\frac{1}{2}} e^{-\frac{(x-\mu)^2}{2 \sigma^2}}\) otoskoon \(n\) kasvaessa, missä \(\mu = np\) on keskiarvo ja \(\sigma^2 = npq\) on varianssi. Huomaamme, kun \(p=1/2\), \(f(n,k) = 2^{-n} \binom{n}{k}\) kaikilla \(k\), eli jakauman muoto syntyy täysin binomikertoimesta. Keskeisen raja-arvolauseen idea syntyy siis siitä, että \(k = n/2\) ykköstä sisältäviä kombinaatioita on valtavasti enemmän kuin muita “epätyypillisempiä” kombinaatioita. Esimerkiksi, viidelle onnistumiselle/ykköselle kymmenästä yrityksestä löytyy \(\binom{10}{5} = 252\) kombinaatiota \(2^{10}=1024\):stä mahdollisesta, kun taas nollan ykkösen kombinaatioita on vain yksi \(\binom{10}{0} = 1\). Parametri \(p\) lähinnä uudelleenpainottaa joitain \(k\) arvoja todennäköisemmäksi, mutta \(0<p<1\) väistämättä tarkoittaa äärimmäisten onnistumismäärien harvenemista otoskoon myötä. Keskeinen raja-arvolause tavallaan kuvaa kuinka nopeasti “suuren järjestyksen” mahdollisuus hupenee suhteessa “epäjärjestykseen” useita satunnaisilmiöitä havaittaessa. Esimerkiksi usean nopan heiton summassa, vain “kaikki ykkösiä” ja “kaikki kutosia” lopputulemat voivat indikoida “suurta järjestystä”, sillä esim. lopputulema “kaikki kolmosia” antaa saman summan kuin lukuisat eri silmälukuja sisältävät “epäjärjestyneemmät” tilat (vrt. Figure 2.2). Keskeisen raja-arvolauseen idea siis on, että rajalla suuri määrä alkeistapahtumia tuottaa “yleisen” keskiarvon \(\mu\) ja muita keskiarvoja tuottavat tapahtumat suhteessa harvenevat (nopealla) vauhdilla \(e^{\frac{(x-\mu)^2}{2 \sigma^2}}\). Pyrimme seuraavaksi siis osoittamaan tämän “harvenemisvauhdin” matemaattisen tarkasti binomijakaumalle ja tyydymme toteamaan saman pätevän muillekin äärellisen varianssin jakaumille.
4.2.1.1 Lyhyt lokaali todistus
Kun viemme otoskokoa kohti ääretöntä, \(n \to \infty\), myös onnistumisten odotusarvo ja varianssi kasvavat rajatta, \(\mu = np \to \infty\) ja \(\sigma^2 = npq \to \infty\). Jotta tarkastelussa olisi järkeä, tutkimme kiinnitettyä pistettä, eli vakiota \(x = \frac{(k - \mu)}{\sigma}\), kun \(n \to \infty\). Tällä oletuksella, myös \(k = x \sqrt{npq} + np\) kasvaa rajatta, kun \(n \to \infty\). Kun \(h \to 0\), lähestyy osamäärä \(\frac{\phi(x+h)-\phi(x)}{h}\) funktion \(\phi\) derivaattaa \(\phi'(x)\) pisteessä \(x\). Samoin, kun \(n,k \to \infty\), differenssifunktion \(\Delta[f](k) = f(n,k+1) - f(n,k)\) askelkoko 1 lähestyy suhteessa häviävän pientä ja differenssifunktio tavallista derivaattaa \(\Delta[f]'(k)\). Huomaamalla, että nyt \(k = x \sqrt{npq} + np\) ja arvioimalla hitaasti kasvavia termejä (aluksi karkeasti) alaspäin, näemme kuinka
\[ \begin{aligned} f(n,k+1) - f(n,k) &= \underbrace{ \frac{n!}{(k+1)!(n-(k+1))!} p^{k+1} q^{n-(k+1)} }_{=\frac{n-k}{k+1}p\frac{1}{q}f(n,k) = \frac{np-kp}{kq+q}f(n,k)} - \underbrace{ \frac{n!}{k!(n-k)!} p^k q^{n-k} }_{=f(n,k) = \frac{kq + q}{kq + q}f(n,k) } \\ &= f(n,k) \frac{np - k \overbrace{(p+q)}^{=1} - q}{kq + q} \\ &= f(n,k) \frac{np - k - q}{kq + q} \\ &= f(n,k) \frac{np - k - q}{xq\sqrt{npq} + npq + q} \\ & \approx f(n,k) \frac{np - k - q}{npq} \\ & \approx f(n,k) \frac{\mu - k}{\sigma^2}. \end{aligned} \]
Yllä johdimme approksimatiivisen yhtälön poistamalla neliöjuuressa kasvavat termit ja vakiotermit jaettavasta ja jakajasta, sillä ne kasvavat “hitaammin” kuin \(n\) ja \(p\), kun \(n \to \infty\). Sijoittamalla \(k = x \sqrt{npq} + np\) ja käyttämällä L’Hôpitalin sääntöä 2. ja viimeisen rivin jälkimmäisten tulotekijöiden vertailuun, nähdään, että ne todella lähestyvät toisiaan, kun \(n\) kasvaa. Siten yllä oleva diskreetti derivaatta myös lähestyy jatkuva-arvoista derivaattaa jollekin funktiolle \(g\), jolle pätee
\[ g'(x) = - \frac{-(x - \mu)}{\sigma^2} g(x). \]
Lukion derivointisäännöistä ns. ketjusääntöä soveltamalla, yllä olevan differentiaaliyhtälön yhdeksi ratkaisuksi nähdään funktio \(g(x) = e^{-\frac{(x-\mu)^2}{2 \sigma^2}}\). Ketjusääntö kertoo sisäkkäisten funktioiden derivaatan (\(\frac{d}{dx}\{g(h(x))\}=g'(h(x))h'(x)\)). Sama ratkaisu saadaan, kun \(g\) ja \(g'\) kerrotaan vakiolla \(M\), jolle \(g\) on todennäköisyystiheys, eli \(\int Mg(x)dx = 1\). Ratkaisemalla \(M\) esim. integroimalla \((\int e^{-x^2}dx)^2 = \int e^{-x^2}dx \int e^{-y^2}dy = \int \int e^{-(x^2 + y^2)} dxdy\) polaarikoordinaateissa, nähdään, että \(Mg(x) = \phi(x; \mu, \sigma)\). Approksimaatio siis pätee, kun \(n\) on suuri.
4.2.1.2 Konvergoitumisvauhti DeMoivre-Laplace teoreemassa
Käytämme Stirlingin kaavaa todistaessamme DeMoivre-Laplace teoreeman, joten käymme sen läpi ensin. Stirlingin kaava on tärkeä approksimaatio faktoriaalille \(n! = n \times (n-1) \times (n-2) \times \cdots \times 2 \times 1\) suurilla \(n\):n arvoilla.
Stirlingin kaava. Suurilla arvoilla \(n\), pätee
\[ \begin{align} n! \approx \frac{n^n}{e^n} \sqrt{2 \pi n}, && \text{tarkemmin, kaikilla } n > 0, && 1 < \frac{n!}{\frac{n^n}{e^n} \sqrt{2 \pi n}} < e^{\frac{1}{12n}}. \end{align} \]
Todistus. Kaavan arvo \(\pi\) ei seuraa vielä tästä todistuksesta, vaan vasta myöhemmästä DeMoivre-Laplace teoreeman todistuksesta. Kun \(n\) on suuri, eli \(1/n\) pieni, \(e^{\frac{1}{12n}} \approx 1 + \frac{1}{12n}\) (koska \(e^x = 1 + x + \frac{x^2}{2!} + \frac{x^3}{3!} + \cdots\) ja jälkimmäiset termit siksi hyvin pieniä, kun \(1/n\) lähellä nollaa); Stirlingin kaavan suhteellinen virhe siis kuristuu kohti nollaa vauhdilla \(\frac{1}{12n}\) (HUOM! Tämä tulee olemaan tärkeää DeMoivre-Laplace teoreeman konvergoitumisvauhdin kannalta). Huomaamme ensin, että faktoriaalin logaritmille pätee \(\log(n!) = \sum_{k=1}^n \log(k)\). Ao. kaavan ja kuvan mukaisesti, voimme approksimoida summaa ala- ja yläpuolelta käyrän alaista pinta-alaa mittaavilla integraaleilla
\[ \int_0^n \log(x) dx \le \sum_{k=1}^n \log(k) \le \int_1^{n+1} \log(x) dx. \]
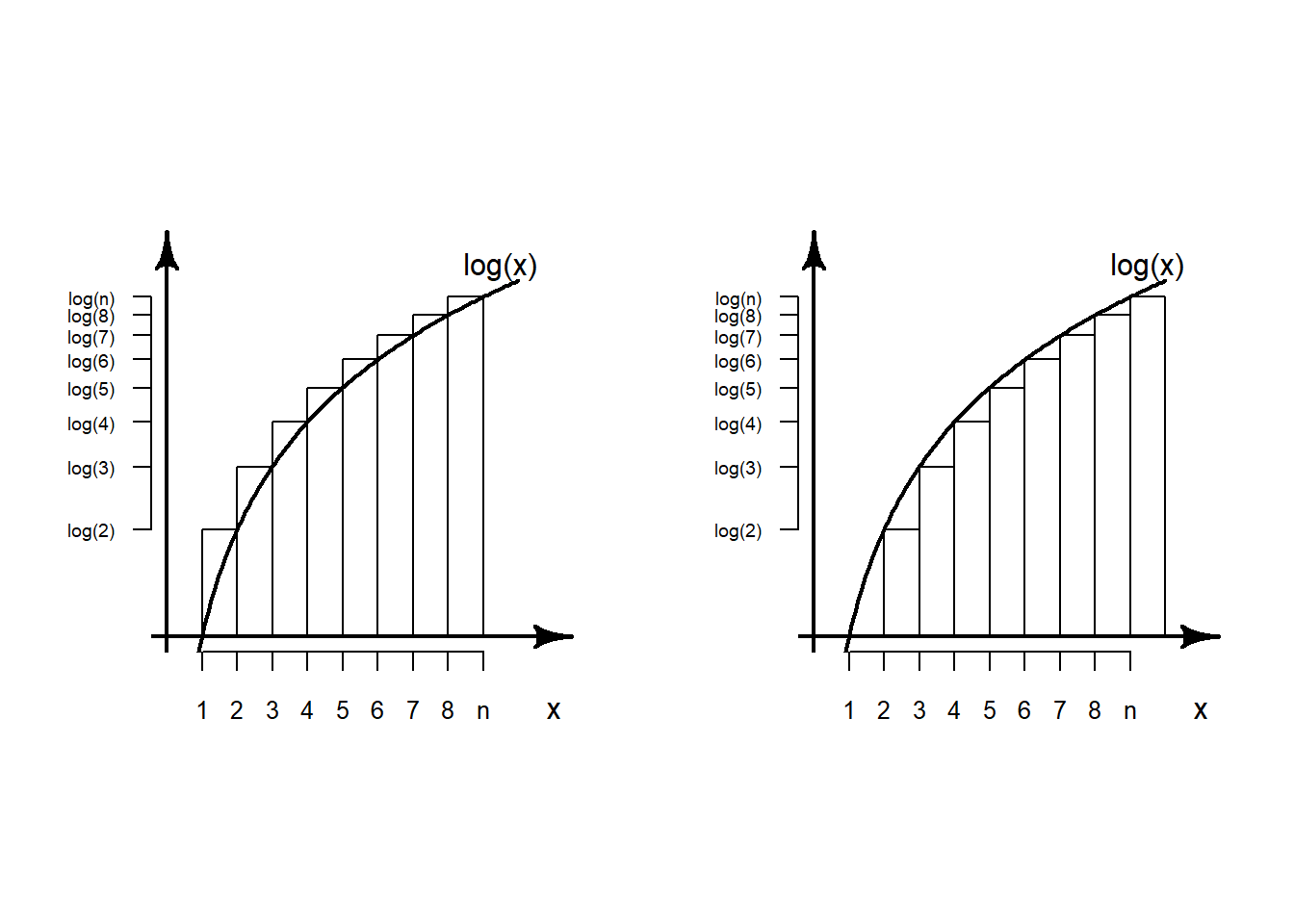
Logaritmin antiderivaatta löydetään tulon derivointisäännöllä \(\log(x) = \frac{d}{dx} \{x \log(x) - x \}\). Siten yllä oleva integraaliepäyhtälö voidaan laskea muotoon
\[ n \log(n) - n \le \log(n!) \le (n+1) \log(n+1) - n. \] Stirlingin approksimaation on löydyttävä näiden rajojen välistä. Valitsemme tutkittavaksi approksimaation \((n+\frac{1}{2}) \log(n) - n\) ja tarkastelemme sen eroa faktoriaalin logaritmiin:
\[ d_n = \log(n!) - \Big[ (n+\frac{1}{2}) \log(n) - n \Big]. \]
Osoitamme, että
- \(d_n\) on monotonisesti laskeva ja siten se konvergoituu johonkin raja-arvoon \(d\)
- jokaiselle \(n\), pätee myös \(d < d_n < d + \frac{1}{12n}\).
Näistä ominaisuuksista seuraa, että
\[ \begin{align} e^d &< e^{d_n} = \frac{n!}{n^{n + \frac{1}{2}} e^{-n} } < e^d \cdot e^{\frac{1}{12n}}, \text{ tarkoittaen,} \\ 1 &< \frac{n!}{\frac{n^n}{e^n} \cdot \sqrt{2 \hat{\pi} n}} < e^{\frac{1}{12n}}, \end{align} \]
jollain toistaiseksi tuntemattomalla vakiolla \(\hat{\pi} = \frac{1}{2} e^{2d}\), joka osoittautuu myöhemmin arvoksi \(\pi\) (eli yksikköympyrän kehän pituuden puolikkaaksi). Tämä on Stirlingin kaava ja lukija voi halutessaan ensimmäisellä lukukerralla ohittaa jonon \(\{d_n \}_{n=1}^{\infty}\) yo. ominaisuuksien todistuksen ja hypätä suoraan Stirlingin kaavan todistuksen loppuun (rivi, jossa pieni laatikko).
Määrittelemme uuden apumuuttujan \(t = \frac{1}{2n+1}\) ja tutkimme paljonko \(d_n\) vähenee otoskoon kasvaessa yhdellä:
\[ \begin{align} d_n - d_{n+1} &= -\log(n+1) - \Big(n + \frac{1}{2}\Big) \log(n) + \Big(n + \frac{3}{2} \Big) \log(n + 1) - 1 \\ &= \Big(n + \frac{1}{2}\Big) \log(\frac{n+1}{n}) - 1 \\ &= \Big(n + \frac{1}{2}\Big) \log\Big(\frac{1 + \frac{1}{2n+1}}{1 - \frac{1}{2n+1}} \Big) - 1 \\ &= \frac{1}{2t} \log\Big( \frac{1+t}{1-t} \Big) - 1 \\ &= \frac{1}{2t} \Big[ \log(1+t) - \log(1 - t) \Big] - 1. \end{align} \]
Kun \(0<t<1\), kuten tässä, geometrisille sarjoille pätee \((1-t)(1 + t + t^2 + \cdots + t^{k-1}) = 1 - t^k\) ja \((1+t)(1 - t + t^2 + \cdots + (-t)^{k-1}) = 1 - (-t)^k\) sekä siten, \(\lim_{K \to \infty} \sum_{k=0}^K t^k = \lim_{K \to \infty} \frac{1 - t^k}{1 - t} = \frac{1}{1 - t} =: \sum_{k=0}^{\infty} t^{k}\) ja vastaavasti \(\sum_{k=0}^{\infty} (-t)^{k} = \frac{1}{1 + t}\). Integroimalla näitä kehitelmiä termeittäin nähdään, että
\[ \begin{align} \log(1-t) = -\int_0^t \frac{1}{1-s}ds = - \sum_{k=1}^{\infty} \frac{t^{k}}{k} && \text{ ja } \\ \log(1+t) = - \sum_{k=1}^{\infty} (-1)^k \frac{t^{k}}{k}. \end{align} \]
Tätä tulosta hyödyntäen,
\[ d_n - d_{n+1} = \frac{1}{2t} \sum_{k=1}^{\infty} (1 - (-1)^k) \frac{t^{k}}{k} - 1 = \frac{1}{t} \sum_{j=0}^{\infty} \frac{t^{2j+1}}{2j+1} - 1 = \frac{1}{t} \sum_{j=1}^{\infty} \frac{t^{2j+1}}{2j+1}. \]
Siten \(d_n - d_{n+1} > 0\), eli \(d_n > d_{n+1}\), tarkoittaen, että jono \(\{d_n \}_{n=1}^{\infty}\) on laskeva kohden raja-arvoaan \(d\). Yllä olevalle vähenemällä saadaan myös yläraja arvioimalla rohkeasti ylöspäin yllä johdettua summatermiä:
\[ \begin{align} d_n - d_{n+1} &< \sum_{j=1}^{\infty} \frac{t^{2j}}{3} = \frac{1}{3} \cdot \frac{t^{2}}{1 - t^{2}} = \frac{1}{3} \cdot \frac{1}{(2n + 1)^2 - 1} = \frac{1}{12} \cdot \frac{1}{n^2 + n} \\ &= \frac{1}{12} \cdot \frac{1}{n} - \frac{1}{12} \cdot \frac{1}{n+1}, \end{align} \]
mistä \(d_n - \frac{1}{12n}\) nähdään nousevaksi jonoksi (poistamalla epäyhtälön kummaltakin puolelta \(\frac{1}{12} \cdot \frac{1}{n} - \frac{1}{12} \cdot \frac{1}{n+1}\)). Siten kaikilla \(n\) pätee
\[ \begin{align} d_n - d &= \lim_{m \to \infty} (d_n - d_m) = \lim_{m \to \infty} \Big( d_n - \frac{1}{12n} - d_m + \frac{1}{12m} + \frac{1}{12n} - \frac{1}{12m} \Big) \\ &< \frac{1}{12n} - \lim_{m \to \infty} \frac{1}{12m} = \frac{1}{12n}. \end{align} \]
Tästä ja jonon \(d_n\) laskevuudesta seuraa haluttu \(d < d_n < d + \frac{1}{12n}\).
\(\square\)
DeMoivre-Laplace teoreema osoittaa, että binomijakautuneen muuttujan \(X \sim \text{Binom}(n, p)\) standardoitu versio
\[ \frac{X - \text{E}[X]}{\sqrt{\text{Var}[X]}} = \frac{X - np}{\sqrt{npq}} \]
lähestyy standardinormaalijakautunutta muuttujaa, kun otoskoko \(n\) kasvaa. Alkajaisiksi on määriteltävä kuinka edes voimme verrata diskreettiä binomijakaumaa jatkuva-arvoiseen normaalijakaumaan. Koska \(k\) on aina kokonaisluku, on luontevaa assosioida se puoliavoimeen reaalilukuväliin \([k-\frac{1}{2}, k+\frac{1}{2})\).
\[ \begin{align} f(n, k) &= P(X = k) = P(k-\frac{1}{2} \le X < k+\frac{1}{2}) \\ &= P \Big(\frac{k-\frac{1}{2} - np}{\sqrt{npq}} \le \frac{X - np}{\sqrt{npq}} < \frac{k+\frac{1}{2} - np}{\sqrt{npq}} \Big). \end{align} \]
Tämän uudelleenskaalatun binomijakauman konvergoitumisen normaalijakaumaan määritellään siis tarkoittavan, että
\[ \begin{align} f(n,k) &= P(X = k) = P \Big(\frac{k-\frac{1}{2} - np}{\sqrt{npq}} \le \frac{X - np}{\sqrt{npq}} < \frac{k+\frac{1}{2} - np}{\sqrt{npq}} \Big) \\ & \approx \phi(\frac{k - np}{\sqrt{npq}}) \cdot \frac{1}{\sqrt{npq}}, \end{align} \]
missä jälkimmäinen termi on varianssin \(npq\) normaalijakauman tiheys ilmaistuna standardinormaalijakauman tiheyden \(\phi\) avulla. Jakaumasuppenimisen ollessa alla olevan DeMoivre-Laplace teorian ydin, tässä annettu muotoilu kuitenkin ottaa kantaa myös konvergenssi- eli suppenemisnopeuteen:
Lokaali DeMoivre-Laplace teoreema. Olkoon \(X \sim \text{Binom}(n, p)\), missä \(p\) on kiinnitetty. Olkoon \(A_n\) ei-vähenevä jono siten, että \(\lim_{n \to \infty} A_n / n^{1/6} = 0\) (esim. \(A_n = 1\)). Silloin
\[ \max_{|k-np|<\sqrt{n} \cdot A_n} |\frac{f(n,k) \cdot \sqrt{npq} }{\phi(\frac{k - np}{\sqrt{npq}})} - 1| = \mathcal{O} \Big(\frac{A_n}{\sqrt{n}} \Big), \]
missä \(g(n) = \mathcal{O}(\frac{A_n}{\sqrt{n}})\) tarkoittaa, että on olemassa \(M>0\) ja \(n_0 > 0\) siten, että kaikilla \(n > n_0\) pätee \(g(n) < M \frac{A_n}{\sqrt{n}}\) (eli epäyhtälön vasen puoli lähestyy nollaa ja oikeaa nopeammin).
Todistus. Tästä todistuksesta seuraa myös, että yllä esitelty \(\hat{\pi} = \pi\). Teoreeman lauselmassa esittelimme myös ns. iso-O notaation. Merkintä \(g(n) = \mathcal{O}(h(n))\) ei tarkoita kirjaimellista yhtä suuruutta vaan, että funktio \(g\) kuuluu siihen funktioiden joukkoon, joita voidaan rajoittaa ylhäältä (majoroida) \(h\):lla. Siksi vakiolla \(c>0\) ei ole merkitystä tässä, eli \(cg(n) = \mathcal{O}(h(n))\) ja, kun \(g_1(n) = \mathcal{O}(h_1(n))\) ja \(g_2(n) = \mathcal{O}(h_2(n))\), niin \(g_1(n)g_2(n) = \mathcal{O}(h_1(n)h_2(n))\); myös \(\mathcal{O}(1/n^2 + 1/n) = \mathcal{O}(1/n)\) jne., eli hitaimmin laskevan funktion majorantti rajoittaa myös nopeammin laskevia funktioita. Hyödynnämme näitä “laskusääntöjä” alla notaation keventämiseksi. Approksimoimme seuraavaksi binomijakauman tiheysfunktiota Stirlingin kaavalla, käyttäen samalla iso-O notaatiota seurataksemme myös approksimaation tarkkuutta.
\[ \begin{align} f(n,k) &= \frac{n!}{k!(n-k)!} \cdot p^kq^{n-k} = \frac{n^n p^kq^{n-k}}{k^k (n-k)^{n-k}} \cdot \frac{\sqrt{2 \hat{\pi} n}}{\sqrt{2 \hat{\pi} k} \sqrt{2 \hat{\pi} (n-k)}} \cdot \Big( 1 + \mathcal{O}\big(\frac{1}{n} \big) \Big) \\ &= \frac{1}{\sqrt{2 \hat{\pi} npq}} \cdot \frac{1}{\big( \frac{n-k}{nq} \big)^{n-k} \big(\frac{k}{np} \big)^k } \cdot \frac{1}{\big(\frac{n-k}{nq} \big)^{1/2} \big(\frac{k}{np} \big)^{1/2} } \cdot \Big(1 + \mathcal{O}\big(\frac{1}{n} \big) \Big) \\ &= \frac{1}{\sqrt{2 \hat{\pi} npq}} \cdot \underbrace{\frac{1}{\big(1 - \frac{k-np}{nq} \big)^{n-k} \big(1 + \frac{k-np}{np} \big)^k }}_{=: I_1} \cdot \underbrace{\frac{1}{\big(1 - \frac{k-np}{nq} \big)^{1/2} \big(1 + \frac{k-np}{np} \big)^{1/2} }}_{=: I_2} \cdot \Big(1 + \mathcal{O}\big(\frac{1}{n} \big) \Big). \end{align} \]
Yllä olevan muotoilun etuna on, että \(|k - np|/n < A_n/\sqrt{n}\) lähestyy nollaa, koska tarkastelemme lauseessa maksimia yli \(\sqrt{n} \cdot A_n\) kokoisten keskiarvopoikkeamien. Olettaen riittävän nollan läheisyyden, voimme ottaa luvusta \(I_1\) logaritmin ja käyttää yllä johdettuja logaritmihajoitelmia toiseen termiin asti, loppujen kuuluessa luokkaan \(\mathcal{O(A_n^3/\sqrt{n})}\):
\[ \begin{align} \log(I_1) &= (n - k) \log \big( 1 - \frac{k - np}{nq} \big) - k \log \big( 1 + \frac{k - np}{np} \big) \\ &= -(k-n) \cdot \frac{k-np}{nq} - k \cdot \frac{k-np}{nq} - \frac{1}{2} \cdot (k - n) \big( \frac{k-np}{nq} \big)^2 + \frac{1}{2} \cdot k \big( \frac{k-np}{np} \big)^2 + \underbrace{\mathcal{O}\Big(\frac{A_n^3}{(\sqrt{n})^3} \Big) \cdot n}_{\frac{n}{6q^3} \big( \frac{k-np}{n} \big)^3 - \frac{2k}{6q^3} \big( \frac{k-np}{n} \big)^3 + \cdots} \\ &= \frac{(n - k)p - kq}{npq} \cdot (k - np) + \frac{(n - k)p^2 + kq^2}{2n^2p^2q^2} \cdot (k - np)^2 + \mathcal{O}\Big( \frac{A_n^3}{\sqrt{n}} \Big) \\ &= \frac{np - k \overbrace{(p+q)}^{=1}}{npq} \cdot (k - np) + \frac{np^2 - k(p - q) \overbrace{(p+q)}^{=1}}{2n^2p^2q^2} \cdot (k - np)^2 + \mathcal{O}\Big( \frac{A_n^3}{\sqrt{n}} \Big) \\ &= \frac{-2npq + np^2 - k(p-q)}{2n^2p^2q^2} \cdot (k - np)^2 + \mathcal{O}\Big( \frac{A_n^3}{\sqrt{n}} \Big) \\ &= - \frac{(k - np)^2}{2npq} - \frac{(p - q)(k - np)^3}{2n^2p^2q^2} + \mathcal{O}\Big( \frac{A_n^3}{\sqrt{n}} \Big) \\ &= - \frac{(k - np)^2}{2npq} - \frac{(p - q)}{2p^2q^2} \cdot \underbrace{n \cdot \big( \frac{k - np}{n} \big)^3 }_{=\mathcal{O}\Big( \frac{A_n^3}{\sqrt{n}} \Big)} + \mathcal{O}\Big( \frac{A_n^3}{\sqrt{n}} \Big) \\ &= - \frac{(k - np)^2}{2npq} + \mathcal{O}\Big( \frac{A_n^3}{\sqrt{n}} \Big). \end{align} \]
Koska pienellä \(x>0\) päti \(e^x \approx 1 + x\) ja viimeinen termi lähestyy nollaa, ottamalla eksponenttifunktio yllä johdetusta \(\log(I_1)\):n arviosta nähdään, että
\[ \begin{align} I_1 &= e^{-\frac{(k - np)^2}{2npq}} e^{\mathcal{O}\big( \frac{A_n^3}{\sqrt{n}} \big)} \\ &= e^{-\frac{(k - np)^2}{2npq}} \cdot \Big(1 + \mathcal{O}\Big( \frac{A_n^3}{\sqrt{n}} \Big) \Big). \end{align} \]
Suoraan sarjahajoitelman ensimmäisellä (vakio)termillä approksimoimalla, saadaan termille \(I_2\) ensimmäisen asteen virhearvio
\[ I_2 = 1 + \mathcal{O}\Big( \frac{A_n}{\sqrt{n}} \Big). \]
Tässä siis käytettiin tietoa \((1 + x)^{-1/2} = 1 - \frac{1}{2}x + \frac{3}{8}x^2 + \cdots\), joka saadaan myös yleistetystä binomiteoreemasta (olennaisesti, muotoa \((1+x)^s\) olevat termit ovat lähellä ykköstä, kun \(x\) on lähellä nollaa). Yhdistämällä yllä olevat yksityiskohdat, saadaan
\[ \begin{align} f(n, k) &= \frac{1}{\sqrt{2 \hat{\pi} npq}} \cdot e^{-\frac{(k-np)^2}{2npq}} \cdot \Big(1 + \mathcal{O}\Big( \frac{A_n^3}{\sqrt{n}} \Big) \Big) \cdot \Big(1 + \mathcal{O}\Big( \frac{A_n}{\sqrt{n}} \Big) \Big) \cdot \Big(1 + \mathcal{O}\Big( \frac{1}{n} \Big) \Big) \\ &= \frac{1}{\sqrt{2 \hat{\pi} npq}} \cdot e^{-\frac{(k-np)^2}{2npq}} \cdot \Big(1 + \mathcal{O}\Big( \frac{A_n^3}{\sqrt{n}} \Big) + \mathcal{O}\Big( \frac{A_n}{\sqrt{n}} \Big) + \mathcal{O}\Big( \frac{1}{n} \Big) \Big) \\ &= \frac{1}{\sqrt{2 \hat{\pi} npq}} \cdot e^{-\frac{(k-np)^2}{2npq}} \cdot \Big(1 + \mathcal{O}\Big( \frac{A_n^3}{\sqrt{n}} \Big) \Big), \end{align} \]
missä lopuksi poimimme suurimman virhetermin iso-O-laskuopin mukaisesti.
\(\square\)
Yllä oleva DeMoivre-Laplace teoreeman versio käsitteli tiheysfunktioita, ollen lokaali raja-arvoteoreema. Toisin kuin ensimmäinen lokaali argumenttimme, tarkkarajainen asymptotiikka ja virherajat olivat nyt osa todistettua väitettä. Keskeinen raja-arvolause kuitenkin vertailee kokonaisia todennäköisyysjakaumia ennemmin kuin tiheysfunktioita yksittäisessä pisteessä, ollen tässä mielessä globaali raja-arvoteoreema. Siksi yleistämme vielä verrokkimme, DeMoivre-Laplace teoreeman, globaaliksi argumentiksi. Tätä varten on hyödyllistä tuntea ns. kolmioepäyhtälö. Niin lukujen itseisarvoille kuin vektorien pituuksillekin pätee \(||x + y|| \le ||x|| + ||y||\), missä \(||x||\) on joko vektorin \(x\) pituus tai luvun \(x\) itseisarvo \(|x|\).
Globaali DeMoivre-Laplace teoreema. Olkoon \(p\) kiinnitetty ja \(X \sim \text{Binom}(n, p)\). Silloin kaikille kiinnitetyille reaaliluvuille \(a < b\), pätee
\[ \lim_{n \to \infty} P(a \le \frac{X - np}{\sqrt{npq}} \le b) = \Phi(b) - \Phi(a), \] missä \(\Phi\) on standardinormaalijakauman kumulatiivinen kertymäfunktio (esim. \(\Phi(a) = \int_{-\infty}^a \phi(x)dx\); HUOM, tulos pätee vaikka epäyhtälöt vaihdettaisiin tiukoiksi toiselta tai molemmin puolin). Otoskoon \(n\) kasvaessa, yhtälön vasenpuoli lähestyy oikeaa vähintään vauhdilla \(\sqrt{n}\).
Todistus. Huomataan, että joukko \(\{a \le \frac{X - np}{\sqrt{npq}} \le b \}\) on sama kuin \(\{a \sqrt{npq} + np \le X \le b \sqrt{npq} + np \}\), jolloin kolmioepäyhtälön nojalla,
\[ \begin{align} \Big|P(a \le \frac{X - np}{\sqrt{npq}} \le b) - (\Phi(b) - \Phi(a)) \Big| &= \Big|\sum_{k = \lceil a \sqrt{npq} + np \rceil}^{\lceil b \sqrt{npq} + np \rceil} f(n, k) - \int_a^b \phi(x)dx \Big| \\ & \le \Big|\sum_{k = \lceil a \sqrt{npq} + np \rceil}^{\lceil b \sqrt{npq} + np \rceil} \Big( f(n, k) - \frac{1}{\sqrt{npq}} \phi \Big( \frac{k-np}{\sqrt{npq}} \Big) \Big) \Big| \\ & \hspace{5 mm} + \Big|\sum_{k = \lceil a \sqrt{npq} + np \rceil}^{\lceil b \sqrt{npq} + np \rceil} \frac{1}{\sqrt{npq}} \phi \Big( \frac{k-np}{\sqrt{npq}} \Big) - \int_a^b \phi(x)dx \Big|. \end{align} \]
Toinen yo. termeistä on integraalin ja sitä edustavan Riemannin summan erotus ja siksi suppenee (integraalin määritelmän mukaisesti) kohden nollaa vauhdilla \(\mathcal{O}(1/n)\), kun \(n\) kasvaa rajatta. Ensimmäiselle yo. termeistä, asetamme \(c > \max(b \sqrt{pq}, a \sqrt{pq})\). Silloin yllä olevan lokaalin todistuksen nojalla pätee
\[ \begin{align} \Big|\sum_{k = \lceil a \sqrt{npq} + np \rceil}^{\lceil b \sqrt{npq} + np \rceil} \Big( f(n, k) - \frac{1}{\sqrt{npq}} \phi \Big( \frac{k-np}{\sqrt{npq}} \Big) \Big) \Big| & \le \sum_{k = \lceil a \sqrt{npq} + np \rceil}^{\lceil b \sqrt{npq} + np \rceil} \Big| \Big( f(n, k) - \frac{1}{\sqrt{npq}} \phi \Big( \frac{k-np}{\sqrt{npq}} \Big) \Big) \Big| \\ & \le \sum_{j = \lceil a \sqrt{npq} + np \rceil}^{\lceil b \sqrt{npq} + np \rceil} \max_{\{k:|k-np|<c\sqrt{n}\}} \Big| f(n, k) - \frac{1}{\sqrt{npq}} \phi \Big( \frac{k-np}{\sqrt{npq}} \Big) \Big| \\ & = \mathcal{O}(\sqrt{n}) \cdot \max_{\{k:|k-np|<c\sqrt{n}\}} \Big| \frac{f(n, k) \sqrt{npq}}{\phi \big( \frac{k-np}{\sqrt{npq}} \big)} - 1 \Big| \cdot \frac{1}{\sqrt{npq}} \phi \Big( \frac{k-np}{\sqrt{npq}} \Big) \\ & \le \mathcal{O}(\sqrt{n}) \cdot \mathcal{O}(\frac{1}{\sqrt{n}}) \cdot \frac{1}{\sqrt{npq}} \phi \Big( \frac{k-np}{\sqrt{npq}} \Big) \\ & = \mathcal{O}(\sqrt{n}) \cdot \mathcal{O} \Big(\frac{1}{\sqrt{n}} \Big) \cdot \mathcal{O}\Big(\frac{1}{\sqrt{n}} \Big) \\ & = \mathcal{O}\Big(\frac{1}{\sqrt{n}} \Big). \end{align} \]
Olemme nyt osoittaneet globaalin teoreeman tiheysfunktiolle \(\phi(x) = \frac{1}{\sqrt{2 \hat{\pi}}} e^{-x^2/2}\). Jotta tämä olisi tiheysfunktio ja siten integroituisi arvoon 1, on pädettävä \(\hat{\pi} = \pi\). Siten myös Stirlingin kaavassa esiintynyt vakio \(\hat{\pi}\) on viimein kiinnitetty tunnettuun arvoonsa.
\(\square\)
Yllä olevan todistuksen havainnot pätevät paljon laajemminkin.
Harjoitustehtävä 1. Simuloi satunnaismuuttujia useammasta eri jakaumasta ja tutki niiden keskiarvon jakaumaa.
Toisin kuin toisinaan virheellisesti ajatellaan, keskeisestä raja-arvolauseesta ei seuraa minkä hyvänsä usean satunnaismuuttujan funktion normaalijakautuneisuutta.
Harjoitustehtävä 2. Simuloi satunnaismuuttujia \(X_i\) standardinormaalijakaumasta ja vertaa muuttujien \(\frac{1}{n}\sum_{i=1}^n e^{X_i}\) ja \(\big( \prod_{i=1}^n e^{X_i} \big)^{\frac{1}{n}}\) jakaumia eri otoskokoarvoilla \(n\).
4.3 Konvergenssikäsitteistä lyhyesti
4.3.1 Neliöjuuri-n konsistenssi
Yllä tutkimme binomijakautunutta muuttujaa \(X\), joka voidaan kirjoittaa myös \(n\):n Bernoulli-jakautuneen satunnaismuuttujan summana, \(X = Y_1 + Y_2 + \cdots + Y_n\). Tässä muuttujat \(Y_i\) ovat toisistaan riippumattomia satunnaismuuttujia (“kolikonheittoja”), joilla on identtinen jakauma, eli \(P(Y_i = 1) = p\) kaikilla \(i\) ja jollekin \(p \in [0,1]\). Odotusarvolle pätee tässä tapauksessa myös \(\text{E}[Y_i] = 0 \times P(Y_i = 0) + 1 \times P(Y_i = 1) = p\), jolloin \(\text{E}[X] = np\). Yllä osoitimme, että seuraava satunnaissuure lähestyy standardinormaalijakautunutta satunnaismuuttujaa:
\[ \begin{align} \frac{X - \text{E}[X]}{\sqrt{\text{Var}[X]}} &= \frac{X - np}{\sqrt{npq}} \\ &= n \cdot \frac{\frac{1}{n} \sum_{i=1}^n Y_i - p}{\sqrt{n} \cdot \sqrt{pq}} \\ &= \sqrt{n} \cdot \underbrace{\Big( \frac{1}{n} \sum_{i=1}^n Y_i - p \Big)}_{=:(\hat{\theta}_n - \theta)} \cdot \underbrace{\frac{1}{\sqrt{pq}}}_{=1/\sqrt{\text{Var}[Y_i]}}, \end{align} \]
missä olemme merkinneet “tosiarvoa” \(p\) symbolilla \(\theta\) ja sen estimaattoria \(\frac{1}{n} \sum_{i=1}^n Y_i\) symbolilla \(\hat{\theta}_n\). Tässä estimaattori on siis keskiarvo, mutta seuraavassa kappaleessa puhumme yleisemmistä estimaattoreista. Koska viimeinen termi yllä on \(Y\)-muuttujien keskihajonnan \(\sigma_Y\) käänteisluku, DeMoivre-Laplace teoreemasta (ja keskeisestä raja-arvolauseesta!) nähdään, että \(\sqrt{n}(\hat{\theta}_n - \theta)\) lähestyy normaalijakaumaa \(N(0, \sigma_Y)\). Yleisemmin todetaan, että ko. termi pysyy todennäköisyyksien mielessä rajoitettuna \(n\):n kasvaessa siitäkin huolimatta, että termi \(\sqrt{n}\) kasvaa rajatta. Toisin sanoen, \((\hat{\theta}_n - \theta)\) menee nollaan “neliöjuuri-\(n\)” vauhdilla, eli \(\hat{\theta}_n\) on \(p\):n tarkentuva eli konsistentti estimaattori. Otoskoon neliöjuuren rajoittamat konsistentit estimaattorit ovat tilastotieteessä hyvin yleisiä ja siinä määrin tärkeitä, että niihin usein viitataan “\(\sqrt{n}\)-konsistentteina”. Palaamme tähän “tilastotieteellisempään” terminologiaan seuraavassa kappaleessa ja käsittelemme tässä vielä seuraavat formaalit todennäköisyysteoreettiset suppenemiskäsitteet, jotka tulevat usein vastaan sekä tilasto- että todennäköisyysteoreettisessa kirjallisuudessa.
4.3.2 Jakaumasuppeneminen, eli jakaumakonvergenssi
Keskeinen raja-arvolause on jakaumien suppenemista, eli konvergenssia, koskeva tulos. Siinä progressiivisesti suurempien otosten keskiarvot \(X_n\) muodostavat jonon satunnaismuuttujia, \(X_1, X_2, \ldots\). Yleisemmin, mikä tahansa jono satunnaismuuttujia \(X_1, X_2, \ldots\) suppenee (konvergoi) jakaumaltaan satunnaismuuttujaan \(X\), jos kaikille relevanteille joukoille \(A\) pätee,
\[ \lim_{n \to \infty} P(X_n \in A) = P(X \in A). \]
Relevantti tässä tarkoittaa, että \(A\) on joukko satunnaismuuttujan maali-avaruudessa, joka kuuluu sigma-algebraan, eikä ole nollajoukko. Nollajoukon \(A_0\) todennäköisyysmitta on nolla, \(P(X \in A_0) = 0\), eivätkä sellaiset joukot vaikuta muuttujan jakautuneisuuteen. Kun jonon satunnaismuuttujat saavat reaalilukuarvoja ja niillä on kertymäfunktiot \(F_1, F_2, \ldots\), jakaumasuppeneminen tarkoittaa, että
\[ \lim_{n \to \infty} F_n(x) = F(x) \]
kaikissa pisteissä \(x\), joissa \(F\) on jatkuva. Jakaumakonvergenssia merkitään usein mm. \(F_n \overset{\mathcal{D}}{\to} F\) tai \(F_n \overset{\mathcal{L}}{\to} F\), joista ensimmäisessä \(\mathcal{D}\) viittaa sanaan “distribution” (jakauma) ja jälkimmäisessä \(\mathcal{L}\) synonyymina käytettävään sanaan “law”, eli “todennäköisyyslakiin”.
Jakaumakonvergenssin idea on, että suurilla arvoilla jonon satunnaismuuttujat voidaan yhä paremmin mallintaa tiettyä raja-jakaumaa käyttäen. Jakaumakonvergenssi on melko heikko matemaattisen suppenemisen muoto. Tämän ymmärtää selkeämmin esiteltyämme toisen paljon käytetyn suppenimisen muodon.
4.3.3 Stokastinen (todennäköisyys)suppeneminen
Todistaessamme heikon suurten lukujen lain käytimme satunnaismuuttujien jonon suppenemista todennäköisyysmitan suhteen, eli stokastisesti. Yleinen määritelmä on seuraava. Satunnaismuuttujien jono \(X_1, X_2, \ldots\) suppenee stokastisesti kohden satunnaismuuttujaa \(X\), jos kaikille luvuille \(\epsilon > 0\) pätee
\[ \lim_{n \to \infty} P(|X_n - X| > \epsilon) = 0. \]
Lyhyempiä merkintätapoja samalle asialle ovat mm. \(X_n \overset{P}{\to} X\) ja \(\text{plim}_{n \to \infty} X_n = X\). Tämän suppenemismuodon johtoajatus on, että \(X\):n verrattuna “epätavallisen” lopputuleman todennäköisyys \(X_n\):lle käy yhä pienemmäksi, kun \(n\) kasvaa.
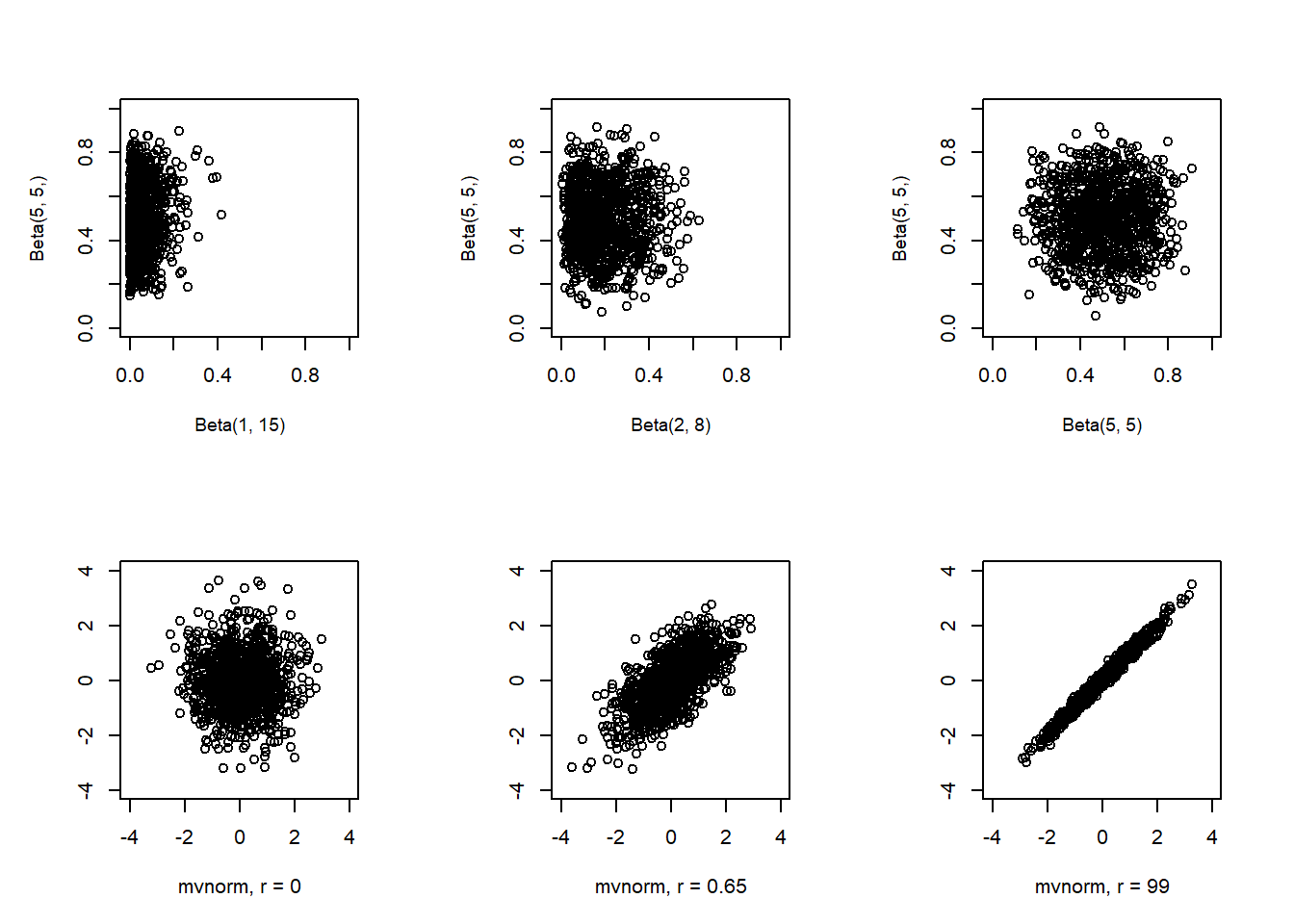
Stokastinen suppeneminen on huomattavasti jakaumasuppenemista vahvempi edellytys, josta jakaumasuppeneminen myös seuraa. Jakaumasuppenemisesta ei kuitenkaan seuraa stokastista suppenemista. Stokastinen suppeneminen koskee itse satunnaismuuttujaa, mutta jakaumasuppeneminen vain sen jakaumaa. Satunnaisotoksia luomalla, alla olevan kuvan ylärivin paneeleissa verrataan satunnaismuuttujien jonoa raja-arvoon jakaumasuppenemisen mielessä ja alarivillä taas stokastisen suppenenimisen mielessä. Olennaisesti, stokastisessa suppenemisessa satunnaismuuttujan realisaatiot lähestyvät toisiaan, kun taas jakaumasuppeneminen ei implikoi moista. Todennäköisyysteoriassa on muitakin suppenemiskäsitteitä, jotka varioivat eri tavoin tässä esiteltyjä perusperiaatteita ja, jotka tässä jätämme käsittelemättä.