Seuraavaksi käymme läpi muutaman tilastotieteen kursseilta tutun todennäköisyysteorian sovelluksen. Yksi kurssin keskeisiä tavoitteita onkin juuri syventää paljon käytettyjen menetelmien perusteiden tuntemusta, jotta niiden soveltamisesta tulee vähemmän mekaanista ja innovatiivisempaa. Ainakin, jos soveltaja ajoittain miettii toimintaansa perusteiden kannalta. Alkuun lukijasta saattaa tuntua, että tällä kurssilla saavutettiin kovin vähän suhteessa tilastomenetelmien laajaan kirjoon. Teksti toivattavasti kuitenkin antaa ajattelun työkaluja, jotka vasta perusperiaatteiden pohdinnan kautta voi lyötää.
Ensinnäkin vanhat periaatteet ovat mukana uudessa myös. Tässäkin materiaalissa käsiteltiin esimerkkiä, jossa tutkijat olivat tiedostaneet, etteivät monitekijäiset ilmiöt automaattisesti lähesty normaalijakaumaa (tai muutakaan helposti arvattavaa jakaumaa). Se taas mahdollisti kysymyksen siitä, mikä jakauma taustalla todella on (Talkkari and Rosenström 2024). Tulokset avaavat jälleen uusia mahdollisuuksia jatkossa hyödyntää jakaumiin perustuvia menetelmiä alalla (Rosenström et al. 2023), ja siten uusia reittejä rikastaa ymmärrystä alkuperäisestä ilmiöstä. Edellä ja alla esitellyt ajatukset ovat myös keskeistä taustateoriaa hyvin pragmaattisille ja teknisesti monimutkaisille tutkimustavoitteille, kuten psykoterapiasuunteuksen personointi ja personoinnin hyötyjen arvioiminen havaintoaineistoista (Malkki et al. 2025).
Toiseksi, perusteiden ymmärtämisestä on monenlaisia hyötyjä, vaikka tutkija haluaisikin käyttää vanhoja menetelmiä mahdollisimman konservatiivisesti. Motivaation roolia ei voi väheksyä pitkäjänteisessä tutkimustyössä ja hallinnan tunne luontaisesti motivoi: on paljon mielekkäämpää edistää laajempaa tavoitetta pienin loogisin ja omaehtoisin askelin kuin pienin askelin, joille jokaiselle on oma käsittämätön manuaalinsa, jota orjan lailla seurata. Vaikka manuaalien seuraamista rakastaisikin ja olisi siinä erinomainen (harva on), “manualisaatio” on aika tehoton menetelmä ns. “kombinatoriaalisen räjähdyksen” vuoksi. Monissa soveltajille suunnatuissa tilasto-oppaissa menetelmiä opetetaan päätöspuiden kautta, jotka haarautuvat eri menetelmiin kysymyksen tai aineiston ominaisuuden mukaan. Tarkoituksena on tehdä soveltamisesta mekaanista, mutta jo viisi peräkkäist kolmen vaihtoehdon valintaa tuottaa “erillisiä” menetelmiä peräti \(3^5 = 243\) kappaletta. Kaikkien erikoistapausten sijaan, on huomattavasti helpompaa muistaa yli vuosien muutama looginen periaate, joista ne kaikki juontuvat. Vanha päätöspuu tukee myös huonosti uusien ratkaisujen oppimista, koska uudet nerokkaat ratkaisut usein murtavat koko puurakenteen. Ne eivät kuitenkaan voi murtaa todistettuja matemaattisia periaatteita. Päinvastoin, uudetkin ratkaisut usein hyödyntävät vanhoja tuttuja periaatteita, joskin uudessa kontekstissa.
5.1 Estimaattori
Yksi tärkeimmistä todennäköisyysteorian sovellutuksista on epäilemättä tilastollinen estimointi. Usein kiinnostuksen kohteena on jokin teoreettisesti tai kliinisen käytännön kannalta keskeinen parametri, jonka arvo pyritään päättelemään aineiston perusteella. Merkitään tämän parametrin tosiarvoa \(\theta\) ja olkoon se reaalilukuarvo esimerkin vuoksi. Tällöin muodostetaan estimaattori, joka on jonkin aineiston \(D\) funktio \(\hat{\theta}(D)\), vaikka usein merkitäänkin vain lyhyesti \(\hat{\theta}\). Tarkemmin ottaen, aineistofunktio määrittelee estimaattorin ja samalla sisällölliselle suureelle voikin olla useita eri tilastollisia estimaattoreita, eli useita aineistosta riippuvia suureita saman asian arviointiin. Tilastotieteessä tyypillisesti tavoitellaan estimaattoreita, joilla on jossain mielessä hyviä ominaisuuksia. Näitä ominaisuuksia tutkittaessa, aineisto \(D\) ajatellaan satunnaismuuttujaksi.
Esimerkiksi, keskiarvo on vain aineistoa kuvaava luku, mutta voidaan kysyä onko se teoriassa hyvä estimaattori jollekin parametrille. Asetamme estimaattorin \(\hat{\theta}_n = \frac{1}{n} \sum_{i=1}^n X_i\), missä esiintyy \(n\) kappaletta (\(i\):llä indeksöityä) riippumatonta havaintoa \(X_i\) samasta jakaumasta. Teoreettisessa tarkastelussa näitä havaintoja mallinnetaan riippumattomilla satunnaismuuttujilla. Jos tuon mallinnetun jakauman odotusarvo on \(\mu\), niin odotusarvoa koskevista laskusäännöistä (todennäköisyysteoriasta) tiedämme, että \(\text{E}[\hat{\theta}_n] = \text{E}[\frac{1}{n} \sum_{i=1}^n X_i] = \frac{1}{n} \sum_{i=1}^n \text{E}[X_i] = \frac{1}{n} \times n \times \mu = \mu\). Keskiarvoa voi siis hyvin käyttää odotusarvo-parametrin estimaattorina. Yllä oleva laskumme osoittaa sen olevan tämän parametrin harhaton estimaattori.
Harhattomuus on yksi estimaattorin usein tutkituista ominaisuuksista. Harhan määritelmä on
missä odotusarvo on yli niiden satunnaismuuttujien, joiden funktio estimaattori on. Estimaattori on harhaton, kun harhan arvo on nolla. Jos harhan (Bias) arvo ei ole nolla, estimaattori on harhainen (biased). Yllä näimme, että kun \(\theta = \mu\), eli odotusarvoparametri, aritmeettinen keskiarvo on sen harhaton estimaattori. Huomaa myös, että harhan voi laskea vain teoreettiselle tosiarvolle, joka on tunnetuksi oletettu suure. Usein on kuitenkin hyvin tärkeää tietää toimisiko jokin käytännön estimointiproseduuri edes teoriassa.
Harhattomuus on kuitenkin vain yksi estimaattorin mahdollisista ominaisuuksista, eikä lainkaan niin välttämätön kuin nimi vihjaa. Esimerkiksi, varianssin \(\sigma\) estimointi neliöpoikkeamien keskiarvolla, \(\hat{\theta}_n = \frac{1}{n} \sum_{i=1}^n (X_i - \frac{1}{n} \sum_{i=1}^n X_i)^2\), on perusteltua, mutta johtaa lievästi harhaiseen estimaattoriin. Tällöin nimittäin, \(\text{Bias}(\hat{\theta}_n) = \frac{1}{n} \sigma^2\), mikä ei ole vakava harha, koska se katoaa vauhdilla \(1/n\) otoskoon kasvaessa (suppenee kohti nollaa, kun \(n \to \infty\)). Estimaattoria, joka suppenee stokastisesti kohden haluttua parametria sanotaan tarkentuvaksi tai konsistentiksi (engl. consistent). Konsistenssi viittaa siihen, että estimoinnin tulos on tarkalleen tavoitteenmukainen otoskoon kasvaessa. Tämä on usein harhattomuutta tärkeämpää. Monet menestyksekkäät estimaattorit ovat tarkoituksella lievästi harhaisia, koska se voi vähentää niiden keskineliövirhettä suhteessa harhattomaan estimaattoriin. Kun kaksi estimaattoria, \(\hat{\theta}_n\) ja \(T_n\), ovat kummatkin harhattomia saman suureen estimaattoreita, sanomme estimaattoria \(\hat{\theta}_n\) näistä tehokkaammaksi (efficient) silloin, kun \(\text{Var}[\hat{\theta}_n] < \text{Var}[T_n]\). Yleisemmin tarkastellaan keskineliövirhettä, jolle pätee edelle viitattu ns. harha-varianssi vaihtosuhde (engl.Bias-variance tradeoff):
Edellisessä kappaleessa esittelimme, että keskiarvosta \(\bar{X}_n\) muodostettu suure \(\sqrt{n}(\bar{X}_n - \mu)\) jakautuu normaalisti, \(\sqrt{n}(\bar{X}_n - \mu) \sim N(0, \sigma^2)\), kun otoskoko on riittävän suuri. Varianssia koskevista laskusäännöistä seuraa, että
Varianssin harhaton ja tarkentuva estimaatti on (lähes) neliöpoikkeamien keskiarvo, \(\hat{\sigma}^2 = s^2 := \frac{1}{n - 1} \sum_{i=1}^n (X_i - \bar{X}_n)^2\). Jakajassa on \(n - 1\) koko otoskoon sijaan, koska keskiarvo on jo yksi aineistosta estimoitu parametri ja siten sitoo yhden havainnon [riippumattomia kohinatermihavaintoja on vain \(n - 1\) kpl, koska \(\sigma\):n estimointi edellyttää myös \(\mu\):n estimointia]. Kun \(\hat{\sigma}^2\) siis otoskoon kasvaessa lähestyy vakiota \(\sigma^2\) stokastisesti, voidaan ajatella, että \(\sqrt{n}(\bar{X}_n - \mu) / \hat{\sigma} \approx \sqrt{n}(\bar{X}_n - \mu) / \sigma\). Itse asiassa, ns. Slutskyn teoreema takaa, että riittävän suuressa otoksessa näin käy.
Nämä tosiasiat luovat mahdollisuuden suurten otosten teoriaan perustuvalle tilastolliselle testaamiselle. Tarkemmin, hypoteesin testaamiselle. Myös tilanteissa, joissa emme jo ennalta tunne todellista populaatioparametrin arvoa. Testaaminen tapahtuu seuraavasti. Oletamme aineiston taustalla piilevälle keskiarvolle \(\mu\) jonkin vakioarvon \(\mu_0\) ja hypoteesit
Ns. “nollahypoteesi” on siis esimerkiksi jokin teoreettisesti merkityksellinen odotusarvoparametrin arvo ja haluamme tutkia vastaako teoria todellisuutta. Esimerkiksi koehenkilöt voisivat kokeilla kahta vaihtoehtoista hoitotekniikka ja \(X_i\) kuvastaa näistä saadun hyödyn eroa henkilön \(i\) kohdalla, jolloin \(\mu_0\) voitaisiin asettaa nollaksi (\(\mu_0 = 0\)). Se tarkoittaisi nollahypoteesia, ettei hoitojen välillä keskimäärin ole hyötyeroa. Seuraavaksi tutkitaan onko jokin havaintoaineisto uskottava nollahypoteesin pätiessä ja, jollei ole, todetaan aineiston “kumoavan” hypoteesin. Voimme jo etukäteen asettaa merkitsevyystason, joka ratkaisee kuinka epätodennäköinen saadun aineiston tulee olla, jotta katsomme nollahypoteesin kumotuksi. Merkitsyvyystasoa merkitään tyypillisesti symbolilla \(\alpha\). Esimerkiksi arvo \(\alpha = .01\) tarkoittaa, että hypoteesin pätiessä vain yksi sadasta vastaavankokoisesta otoksesta tuottaa yhtä paljon tai enemmän nollahypoteesista poikkeavan odotusarvoestimaatin, eli keskiarvon.
Sitten laskemme aineistollemme testisuureen\(\hat{z} = \sqrt{n}(\bar{X}_n - \mu_0)/\hat{\sigma}\). Koska se keskeisen raja-arvolauseen nojalla jakautuu standardinormaalisti riittivän suurella \(n\), voimme laskeä kuinka epätodennäköinen näin suuri tai vielä suurempi poikkeama oletetusta keskiarvosta on. Tämän ns. p-arvon voi määritellä standardinormaalisti jakautuneen teoreettisen \(Z\)-muuttujan todennäköisyysjakaumalla seuraavasti
missä \(\phi\) on standardinormaalijakauman tiheysfunktio, \(\phi(z) = \frac{1}{\sqrt{2 \pi}} e^{-\frac{1}{2}z^2}\), ja \(\Phi\) siitä yllä määritelty kumulativiinen jakaumafunktio. Kolmas yhtäsuuruus yllä seurasi standardinormaalijakauman symmetrisyydestä: \(P(Z < -a) = P(Z > a)\) kaikilla \(a\) (huomaa, etteivät kaikki jakaumat suinkaan ole symmetrisiä nollan ympärillä).
Standardinormaalijakauman kumulatiiviselle (kertymä)funktiolle ei ole olemassa analyyttista kaavaa ilman integraalia, mutta sen arvot on helppo laskea numeerisesti, esimerkiksi R-ohjelmassa funktiolla “pnorm”. Annamme käytännön esimerkin alla.
# Ajattellaan, etta havaitsimme ao. arvot otoksessamme 0 ja otoksessa 1set.seed(12358) # poista rivi, jos haluat kokeilla eri arvoilla(x0 <-round(runif(n =30, min =-27, max =27))) # H_0 voimassa
# lasketaan havaittu z-arvo kummassakin tapauksessa(z0 <-sqrt(30)*(mean(x0) -0)/sd(x0))
[1] -0.7482979
(z1 <-sqrt(30)*(mean(x1) -0)/sd(x1))
[1] 11.07399
# lasketaan p-arvot kummassakin tapauksessa hypoteesille mu = 0(p0 <-2*(1-pnorm(abs(z0))))
[1] 0.4542805
(p1 <-2*(1-pnorm(abs(z1))))
[1] 0
Nähdään, että p-arvo on ensimmäisen aineiston kohdalla suurempi kuin ennalta asettamamme merkitsevyystaso. Tuo aineisto ei siis kumoa asettamaamme nollahypoteesia \(\mu = 0\). Toinen aineisto sen sijaan hyvin selvästi kumoaa, sillä numeerisen tarkkuuden rajoissa p-arvo on nolla. Käytännössä tällainen tilastollinen testaaminen suoritetaan usein ns. t-testillä, joka tarkemmin mallintaa sitä tosiasiaa, että myös \(\hat{\sigma}\) (keskihajonta) on satunnaismuuttuja äärellisessä aineistossa. t-testi hyvin nopeasti otoskoon noustessa asettuu samaan arvoon kuin tässä laskettu z-testikin, antaen esimerkissämme arvon, joka on hyvin lähellä edellä laskettua:
# lasketaan p-arvot kummassakin tapauksessa(p0_ttest <-t.test(x0)$p.value)
[1] 0.4603065
Huomaa, että valmiin R-ohjelman testityökalun sijaan, myös t-testin voisimme laskea suoraan yllä olevan esimerkin mukaisesti ns. t-jakaumasta, joka on sekin symmetrinen:
# suoraan t-jakaumasta laskeminen antaa saman arvon kuin yo. R-funktio:2*(1-pt(abs(z0), df =29)) # df = n - 1 tassa tapauksessa (vapausasteet)
[1] 0.4603065
5.3 Tilastollinen mallintaminen ja uskottavuusfunktio
Hypoteesien testaaminen on aika perinteinen todennäköisyysteorian sovellus, mutta yhä enemmän nojataan havaintoaineistojen monimutkaisempaan tilastolliseen mallintamiseen. Tilastollinen malli on matemaattinen malli, joka vangitsee aineiston syntyä koskevat tilastolliset oletukset. Aiemmin tarkastelimme nopanheittoa olettaen, että jokaisen kuuden silmäluvun todennäköisyys on \(\frac{1}{6}\). Tästä syntyi havaintoaineistoa generoiva matemaattinen malli, joka mahdollisti havaintojen todennäköisyyksiin liittyviä laskuja. Tasajakauma oli kuitenkin vain oletus, vaikkakin mielekäs sellainen. Olisi kuitenkin mahdollista olettaa noppa painotetuksi siten, että silmäluvun kuusi todennäköisyys on \(\frac{7}{12}\) ja muiden silmälukujen \(\frac{1}{12}\). Tilastolliseen mallintamiseen siis väistämättä liittyy oletuksia, joita joudutaan perustelemaan jostain teoriasta käsin. Tilastolliselle mallille on mahdollista antaa yleisiä määritelmiä, kuten seuraava.
Määritelmä (Tilastollinen malli). Tilastollinen malli on pari \((\mathcal{S}, \mathcal{P})\), missä \(\mathcal{S}\) on otanta-avaruus (perusjoukko) ja \(\mathcal{P}\) on avaruus, jonka alkiot ovat todennäköisyysjakaumia otanta-avaruudessa \(\mathcal{S}\). \(\mathcal{P}\) edustaa kaikkia aineistoa generoivia malleja, jotka katsotaan mahdollisiksi.
On tyypillistä parameterisoida\(\mathcal{P}\) siten, että \(\mathcal{P} = \{ F_\theta : \theta \in \Theta \}\), missä \(\Theta\) määrittää mallin parametri-avaruuden ja jokainen parametrin arvo \(\theta \in \Theta\) määrittää jonkin todennäköisyysjakauman \(F_\theta\). Kun parameterisaatio on sellainen, että ehdosta \(F_{\theta_1} = F_{\theta_2}\) väistämättä seuraa \(\theta_1 = \theta_2\), tilastollista mallia sanotaan identifioituvaksi. Tarkastellaan esimerkkinä edellä tutkittua Binomijakaumaa. Siinä tapauksessa \(\Theta = [0, 1] \subset \mathbb{R}\), eli välin nollasta yhteen reaalilukualkiot. Malliavaruuden alkiot ovat muotoa \(f(Y|\theta) = \binom{n}{\sum Y_i} \theta^{\sum Y_i} (1 - \theta)^{n - \sum Y_i}\) havainnoille \(Y = \{Y_1, Y_2, \ldots, Y_n \}\), missä jokainen \(Y_i\) saa arvon 1 (tapahtuma) tai 0 (ei tapahtumaa). Tässä \(k = n \bar{Y} = \sum_{i=1}^n Y_i\) on ns. tyhjentävä tunnusluku, koska binomijakauma riippuu usean arvon aineistosta vain tämän yhden tunnusluvun kautta: \(f(Y|\theta) = \binom{n}{k} \theta^{k} (1 - \theta)^{n - k} = \binom{n}{n \bar{Y}} \theta^{n \bar{y}} (1 - \theta)^{n - n \bar{y}}\).
Huomautus. Tilastollisen mallin identifioituvuus on tärkeää lähinnä, kun tavoitteena on tehdä päätelmiä malliparametrista \(\theta\). Usein kuitenkin kiinnostuksen kohteena on jokin todellisuuden syy-seurausrakenteeseen liittyvä rakenteellinen parametri, jolloin tilastolliset mallit voivat olla ns. semiparametrisia ja niiden parametrien identifioituvuus toissijaista tai määrittelemätön kysymys [ks. esim. (Laan and Rose 2011a)]. Silloinkin on kuitenkin usein mahdollista tunnistaa ns. tehokas vaikutusfunktio (engl. efficient influence curve, or function) \(\psi\) ja lokaalisti lineaarinen (rakenteellisen parametrin) estimaattori \(\hat{\theta}_n\), jolla
missä \(o_P(1)\) on otoskoon myötä stokastisesti nollaan suppeneva termi, \(\text{E}[\psi(Y_i)] = 0\) ja suurilla otoksilla pätee siis keskeisen raja-arvolauseen nojalla \(\sqrt{n}(\hat{\theta}_n - \theta) \sim N(0, \text{E}[\psi(Y_i)^2])\). Tämä tarkoittaa, että yllä opitut strategiat yleistyvät hyvinkin abstrakteihin sovelluksiin. Esimerkiksi, alla keskustellun suurimman uskottavuuden estimaattorin kohdalla \(\psi(Y_i) = \ell'(\hat{\theta}; Y)\) ja (säännölliselle mallille) \(\text{E}[\psi(Y_i)^2]) = i(\hat{\theta})\).
Kun binomijakauman tiheysfunktiota ajatellaan tunnusluvun \(k\) funktiona, \(k \mapsto f(k|\theta)\), ja parametri \(\theta\) on kiinnitetty yhteen tiettyyn arvoon, objekti \(f\) on todennäköisyystiheysfunktio. Sama objekti \(f\) on ns. uskottavuusfunktio, kun aineisto \(y\) ja siten \(k\) on kiinnitetty yhteen tiettyyn arvoon ja tutkitaan \(f\):n arvon vaihtelua parametrin \(\theta\) vaihtelun funktiona, \(\theta \mapsto f(k|\theta)\). Uskottavuusfunktio kertoo kuinka “uskottava” tietty parametrin arvo on aineiston \(k\) tuottaneeksi (generoineeksi) arvoksi. Parametrin \(\theta\) arvoa, jolle uskottavuus on kaikkein suurin, sanotaan suurimman uskottavuuden estimaattoriksi (engl. maximum likelihood estimator) ja merkitään myöskin symbolilla \(\hat{\theta}\).
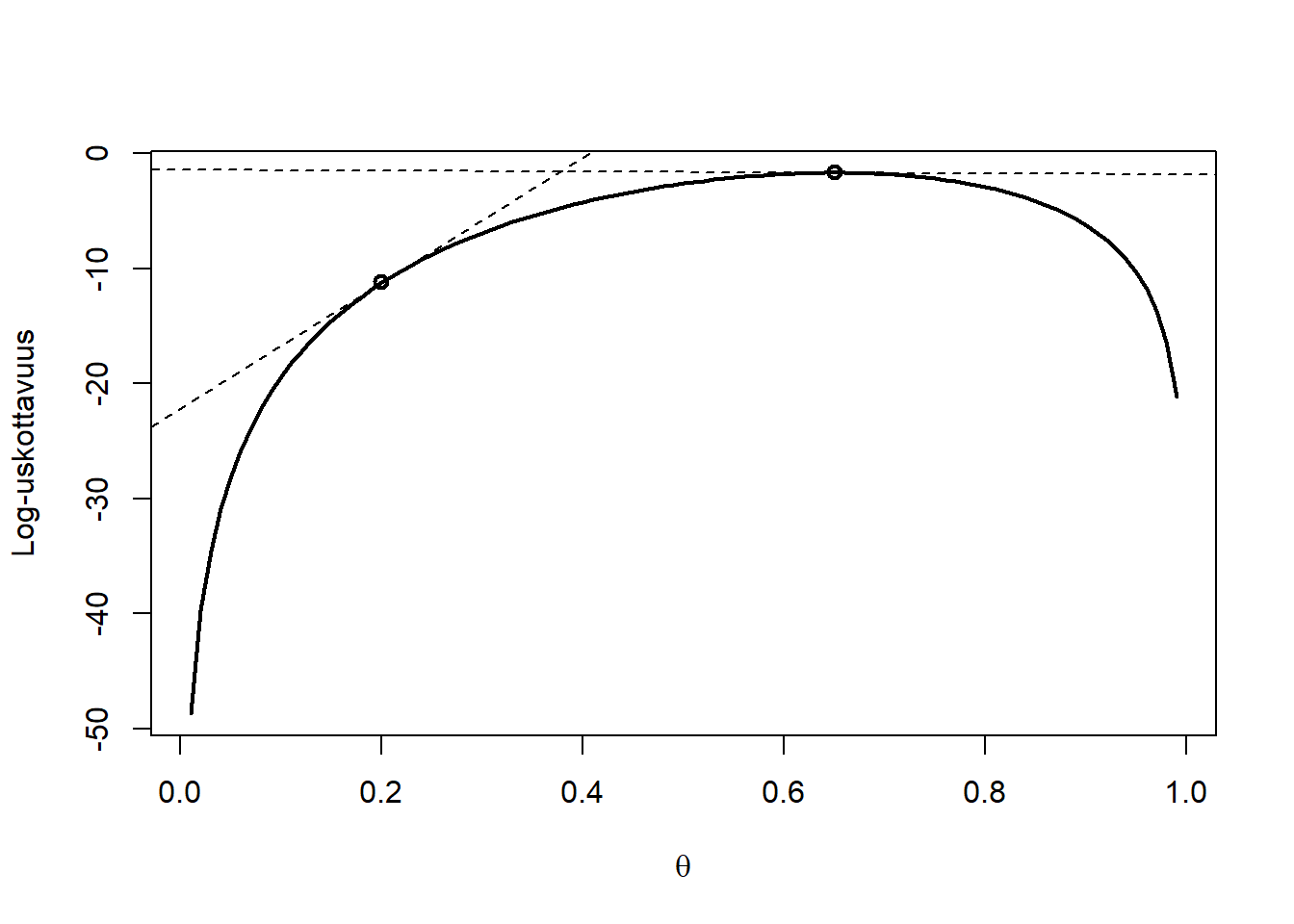
Suurimman uskottavuuden estimaattori on tilastotieteessa hyvin tärkeä käsite. Etsitään siis esimerkkinä binomijakauman suurimman uskottavuuden estimaattori. Tässä yksinkertaisessa tapauksessa voimme tehdä sen ns. analyyttisesti (symboleja manipuloimalla), mikä on pedagogisesti havainnollista, mutta useimmiten estimaattorin arvo määritellään uskottavuusfunktion huippukohtaa etsivin numeerisin algoritmein. On hyvin hyödyllistä huomata, että uskottavuusfunktion \(\theta \mapsto f(k|\theta)\) maksikohta on sama kuin funktion \(\theta \mapsto \log f(k|\theta)\) maksimi, koska logaritmi on monotonisesti kasvava, eli järjestyksen säilyttävä, funktio. Riittää siis etsiä log-uskottavuusfunktion maksimi annetulle aineistolle \(k\), eli \(\max_{\theta} \log f(k|\theta)\). Havainnollisuuden vuoksi alla oleva R-osio tuottaa log-uskottavuusfunktion graafin konkreettisista (simuloiduista) havainnoista. Lukiomatematiikasta tiedämme, että funktion maksimiarvo löytyy pisteestä \(\theta\), jossa derivaatta asettuu nollaan, \(\frac{d}{d\theta} \log f(k|\theta) = 0\). Kuva piirtääkin derivaatan mukaisen tangentin parissa kohtaa kuvaajaa, joista jälkimmäinen on suurimman uskottavuuden estimaatin kohdassa (kasvunopeuden, eli derivaatan, nollakohdassa).
# simuloidaan aineistoset.seed(123); n <-20; theta_true <-0.7# parametrit( y <- (runif(n) <= theta_true)*1 ) # havainnot
[1] 1 0 1 0 0 1 1 0 1 1 0 1 1 1 1 0 1 1 1 0
k <-sum(y) # lasketaan tyhjentava tunnusluku# log-uskottavuusfunktio:logf <-function(theta) log(dbinom(k, size=n, prob=theta))# kuvaaja:theta_vals <-seq(0.01, 0.99, by=0.01)plot(theta_vals, logf(theta_vals), type ="l", lwd =2,xlab =expression(theta), ylab ="Log-uskottavuus")# derivaatatds <-diff(logf(theta_vals))/0.01; sue =round(k/n*100)abline(a=logf(theta_vals[20])-ds[20]*theta_vals[20],b=ds[20], lty =2)abline(a=logf(theta_vals[sue])-ds[sue]*theta_vals[sue],b=ds[sue], lty =2)points(theta_vals[c(20,sue)], logf(theta_vals[c(20,sue)]), lwd =2)
Figure 5.1: Log-uskottavuusfunktion maksimointi.
Derivoimalla ja logaritmien laskusääntöjä käyttämällä nähdään, että
Asettamalla yo. nollaksi, saadaan \(\theta = k/n\), eli binomijakauman parametrin suurimman uskottavuuden estimaattori on \(\hat{\theta} = \frac{1}{n} \sum_{i=1}^n Y_i\), joka sattuu siis myöskin olemaan havaintojen keskiarvo. Olemme yllä osoittaneet, että tämän nimenomaisen suurimman uskottavuuden estimaattorin (keskiarvon) otantajakauma lähestyy normaalijakaumaa otoskoon kasvaessa (keskeinen raja-arvolause). Normaalijakaumatesti löytyy kuitenkin paljon yleisemmin suurimman uskottavuuden estimaattoreille, kuten alla osoitamme.
5.3.1 Informaation käsite
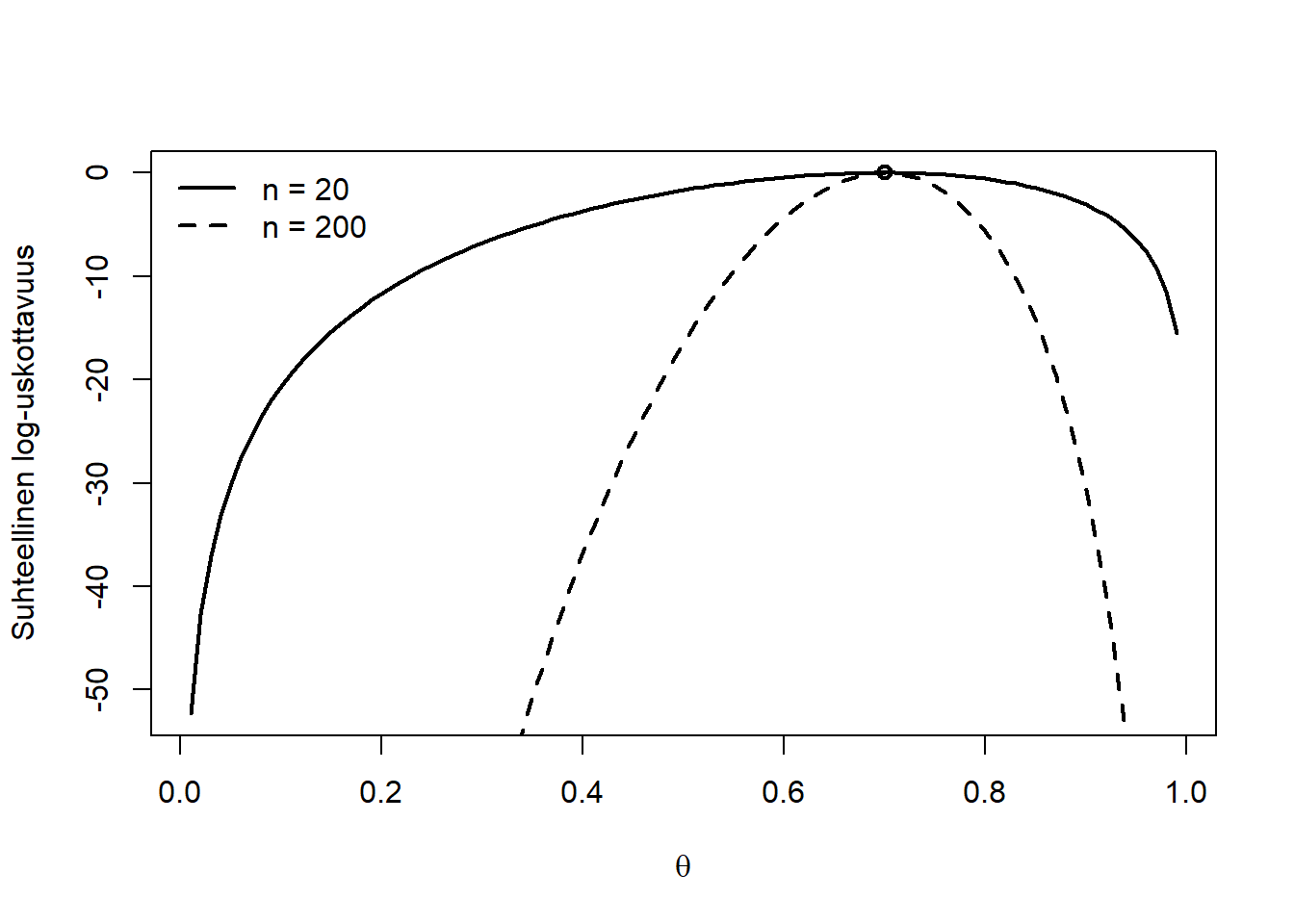
Yllä näimme kuinka suurimman uskottavuuden estimaattori löytyi log-uskottavuusfunktion nollakohdasta. Merkitään nyt log-uskottavuusfunktiota lyhyesti \(\ell(\theta) := \ell(\theta; Y) := \log f(Y|\theta)\) ja havaitulle aineistolle \(\ell(\theta; y)\). On mielenkiintoista verrata binomijakauman log-uskottavuusfunktioiden muotoa suurimmin uskottavuudeen pisteen ympärillä, kun otoskoko muuttuu. Alla oleva kuva piirtää kuvaajan \(\theta \mapsto \ell(\theta) - \ell(\hat{\theta})\), kun otoskoko kasvaa kahdesta kymmenestä (katkoton viiva) kahteen sataan (katkoviiva) ja suurimman uskottavuuden estimaatti \(k/n\) (pallo) pysyy vakiona. Siinä missä suurimman uskottavuuden arvo pysyy paikallaan x-akselilla yli otoskokojen, log-uskottavuusfunktion kaarevuus tuon pisteen ympärillä muuttuu suuresti, jyrkentyen otoskoon kasvaessa. Jos ehto \(\ell'(\hat{\theta}) = 0\) määrittää suurimman uskottavuuden estimaatin, niin funktion vahvempi kaareutuminen pisteen \(\ell(\hat{\theta})\) ympärillä implikoi suurempaa varmuutta, että juuri \(\hat{\theta}\) todella on funktion \(\ell'\) nollakohta, jonkin toisen likeisen \(\theta\)-akselin pisteen sijaan. Funktion \(\ell\) kaareutumiseen määrää pisteessä \(\hat{\theta}\) mittaa sen toinen derivaatta ko. pisteessä, eli \(\ell''(\hat{\theta})\). Sitä negatiivisempi on \(\ell''(\hat{\theta})\) mitä jyrkemmin \(\ell\) putoaa lakipisteensä \(\hat{\theta}\) ympärillä.
Figure 5.2: Informaation käsite.
Sanomme, että \(-\ell''(\hat{\theta}; y)\) on aineistosta \(y\)havaittu informaatio. Havaittu informaatio riippuu tietysti havaitusta aineistosta. Jos aineisto ajatellaan parametrista \(\theta\) riippuvaksi satunnaismuuttujaksi, sen odotusarvoa kutsutaan mallin odotetuksi informaatioksi, eli Fisherin informaatioksi, ja merkitään
Kyseessä on tiettyyn parametrin arvoon \(\theta\) liittyvä odotusarvo, joka voidaan laskea mallille jo ennen kuin mitään aineistoa on kerätty tai tiedossa. Odotettu informaatio on siis mallia luonnehtiva teoreettinen suure, jolla on syvällinen merkitys tilastollisen päättelyn teoriassa. Nimittäin, funktion \(\ell'\) nollakohta on toki ratkaistavissa yksittäiselle aineistolle, vaikka se kaareutuisikin vain heikosti, mutta otantavaihtelulle pätee \(\text{Var}[\ell'(\theta; Y)] = i(\theta)\) (ks. ao. osio).
Vaikkemme käsittele teemaa tässä tekstissä, on hyvä tietää, että tilastotieteessä ja matematiikassa on muitakin informaatiokäsitteitä kuin tässä esitelty klassinen Fisherin informaatio, kuten informaatioteoreettinen informatio.
5.4 Tehokas piste-estimointi ja luottamusvälit
Uskottavuusfunktion \(f_Y(y; \theta)\) määrittämä jatkuva tilastollinen malli on säännöllinen, jos seuraavat tekniset ehdot ovat voimassa
jakauman alusta ei riipu parametrista \(\theta\). Alusta on joukko \(A = \{y: f_Y(y; \theta) > 0\}\), jossa aineisto on mahdollinen.
funktion \(\theta \mapsto f_Y(y; \theta)\) on kaksi kertaa (jatkuvasti) derivoituva jokaiselle \(y\).
Lisäksi pätee \(\int_A \frac{d}{d\theta} f_Y(y; \theta)dy = 0\) ja \(\int_A \frac{d^2}{d\theta^2} f_Y(y; \theta)dy = 0\).
Varsin monet yleisesti käytetyt tilastolliset mallit, kuten eksponenttiperheen mallit, ovat säännöllisiä.
Apulause. Kun \(f_Y(y; \theta)\) on säännöllinen malli ja \(\ell(\theta; y) = \log \big( f_Y(y; \theta) \big)\) sen uskottavuusfunktio, \(\text{E}[\ell'(\theta; Y)] = 0\) ja \(\text{E}[\ell'(\theta; Y)^2] = \text{Var}[\ell'(\theta; Y)] = i(\theta)\).
Säännöllisille malleille pätee Cramér-Rao epäyhtälöt, eli informaatioepäyhtälöt, jotka hivenen rajatummassa ja yksinkertaisemmassa muodossa ovat seuraavat.
Informaatioepäyhtälöt. Olkoon \(f_Y(y; \theta)\) säännöllinen malli ja \(i(\theta)\) sen Fisherin informaatio. Olkoon \(T = t(Y)\) jokin \(\theta\):n estimaattori ja \(\text{Bias}(T)\) sen harha. Tällöin
Todistus sivuutetaan tässä sisällön laajuudeen rajaamiseksi, muttei ole erityisen hankala ja löytyy helposti suomenkielisestä ja ulkomaisesta kirjallisuudesta. Raja on kuitenkin luonteeltaan syvällinen, sillä se osoittaa perustavanlaatuisen määrällisen ylärajan estimoinnin tehokkuudelle, jota ei voida millään prosessein ylittää.
Harhattoman estimaattorin tehokkuus voidaan siis ilmaista prosentteina kaavalla \(100 \% \times i(\theta)^{-1} / \text{Var}_{\theta}[T]\). Kun \(\text{Var}_{\theta}[T] = i(\theta)^{-1}\), estimaattori on täystehokas. Vaikka harva estimaattori on täystehokas, suurimman uskottavuuden estimaattorit ovat asymptoottisesti harhattomia ja täystehokkaita, eli ne tarkentuvat täystehokkaaseen estimaattoriin otoskoon kasvaessa. Soveltamalla keskeistä raja-arvolausetta, niiden rajajakauma voidaan osoittaa normaalijakaumaksi, mikä jälleen mahdollistaa yllä esitellyn luottamusvälilaskennan ja testauksen. Annamme tässä Niemistä ja Saikkosta (2013) seurailevan todistuksen idean lyhyesti. Sitä varten tarvitsemme yhden työkalun matemaattisen analyysin puolelta.
Matemaattisessa analyysissa Taylorin teoreemana tai kehitelmänä tunnettu tulos osoittaa kuinka äärettömän monta kertaa derivoituva funktio \(f\) voidaan ilmaista pisteen \(a\) ympärillä pylynomisarjana
missä \(f^{(n)}\) on funktion \(f\) n:s derivaatta ja \(\xi\) jokin \(a\):n ja \(x\):n välinen piste. Kun \((x - a) =: 1/s\) lähestyy nollaa, eli \(s\) kasvaa rajatta, kaikilla \(k \ge 1\) termit \((x - a)^{1+k}\) ovet häviävän pieniä suhteessa termiin \((x - a)\), koska \((x - a)^{1+k}/(x - a) = 1/s^k \to 0\). Toisin sanoen, ensimmäisen asteen lineaarinen termi dominoi Taylorin kehitelmää kehityspisteensä ympärille. Taylorin kehitelmää käytetään alla ilman todistusta.
5.4.1 Suurimman uskottavuuden estimaattorin asymptoottinen jakauma
Tarkastellaan tilannetta, jossa havaintoja vastaavat satunnaismuuttujat \(Y_1, Y_2, \ldots, Y_n\) ovat samoin jakautuneita, yhden parametrin tiheysfunktionaan \(f_Y(y; \theta)\). Havaintovektorin \(y = (y_1, y_2, \ldots, y_n)\) tilastollinen malli on tällöin \(f_Y(y; \theta) = \prod_{i=1}^n f_Y(y_i; \theta)\) ja sen log-uskottavuusfunktio on \(\ell(\theta; y) = \log(f_Y(y; \theta)) = \sum_{i=1}^n \log(f_Y(y_i; \theta))\). Tällöin (riittävien säännöllisyysehtojen toteutuessa) suurimman uskottavuuden estimaattorille \(\hat{\theta}_n\) pätee
kun \(n \to \infty\), missä \(i(\theta)\) on n:n havainnon aineiston Fisherin informaatio, eli riippumattomin samoin jakautunein havainnoin \(i(\theta) = n \times i_1(\theta)\) yhden havainnon informaatiolla \(i_1(\theta)\).
Toteamme ilman todistusta, että \(\hat{\theta}_n\) tarkentuu kohden todellista parametria \(\theta\) otoskoon kasvaessa, mutta tutkimme hieman perusteluja yo. jakaumaa koskevalle väitteelle. Merkitään selvyyden vuoksi todellista aineiston generoinutta parametrin arvoa alaindeksi-symbolilla \(\theta_0\). Suurimman uskottavuuden estimaattori löydetään log-uskottavuusfunktion ensimmäisen derivaatan nollakohdasta. Oletetaan riittävä säännöllisyys ja tutkitaan tuon funktion (eli \(\ell'\)) Taylorin kehitelmää pisteen \(\theta_0\) ympärillä:
Kun tätä tarkastellaan aineistoa vastaavalle satunnaisvektorille \(Y\) ja sijoitetaan muuttujan \(\theta\) paikalle \(\theta_0\):n suurimman uskottavuuden estimaattori \(\hat{\theta}_n\), viimeinen termi on muotoa \(\frac{1}{2} \ell'''(\xi; Y) (\hat{\theta}_n - \theta_0)^2\). Yllä olevan Taylorin kehitelmää koskevan argumentoinnin nojalla, ko. termi on suurilla otoksilla häviävän pieni suhteessa muihin termeihin, koska \(\hat{\theta}_n\) on tarkentuva. Päädytään asymptoottiseen arvioon
Koska oletamme, että \(\hat{\theta}_n\) on saatu suurimman uskottavuuden estimointiyhtälön \(\ell'(\hat{\theta}_n;y)=0\) ratkaisuna, yo. yhtälön vasen puoli on nolla. Ratkaisemalla se termin \((\hat{\theta}_n - \theta_0)\) suhteen ja tuomalla otoskoko näkyviin yhtälössä aritmeettisesti kumoutuvana terminä, saadaan
missä \(\ell_1(Y_i; \theta) = \log(f_Y(Y_i; \theta))\) on yhteen havaintoon perustuva log-uskottavuusfunktio. Satunnaismuuttujat \(\ell_1'(Y_i;\theta_0)\) ovat toisistaan riippumattomia, kunkin odotusarvo on nolla yllä olevan apulauseen nojalla ja kunkin varianssi on yhden havainnon Fisherin informaatio \(i_1(\theta_0)\). Keskeisen raja-arvolauseen nojalla, (Equation 5.1):n osoittaja jakaumasuppenee kohden jakaumaa \(N(0, i_1(\theta_0))\). Suurten lukujen lain nojalla (Equation 5.1):n nimittäjä \(-\ell''(\theta_0; Y)/n = \frac{1}{n} \sum_{i=1} -\ell_1''(\theta_0; Y_i)\) suppenee stokastisesti kohden termiä \(\text{E}[-\ell_1''(\theta_0; Y_1)] = i_1(\theta_0))\). Yhdistämällä tulokset (ja nojaamalla Slutskyn teoreeman), voidaan päätellä, että
Toisin sanoen, suurimman uskottavuuden estimaattorin asymptoottinen jakauma on \(N(\theta_0, (ni_0(\theta_0))^{-1})\), missä \(ni_1(\theta_0)\) on koko mallin Fisherin informaatio.
Näin ollen, suurimman uskottavuuden estimaattorit ovat hyvin yleisesti ottaen asymptoottisesti tarkentuvia ja normaalisti jakautuneita, mikä todennäköisesti selittänee niiden suurta suosiota tilastotieteessä. Myös paljon yleisemmin, ns. asymptoottisesti lineaariset estimaattorit ovat tarkentuvia ja asymptoottiselta jakaumaltaan normaalisia (Laan and Rose 2011b).
5.5 Suurten otosten teorian rajoista ja Bayes-laskennasta
Yllä esitellyt tulokset perustuvat äärettömän rajankäynnin ajatukseen, mutta mikään otoskoko ei tietysti käytännössä ole ääretön. Kuten olemme edelle nähneet, otoksen ei aina tarvitse olla kovinkaan suuri ollakseen käytännössä ääretön mitä tulee jakaumakonvergenssiin. Tutkimmekin tässä ns. neliöjuuri-n vauhtia konvergoituvia estimaattoreita, eivätkä tätä hitaammin konvergoituvat välttämättä ole käytännössä hyödyllisiä. Toisaalta, tällaisetkaan asymptoottiset tulokset eivät anna takeita, että riittävä konvergenssi tapahtuisi yhtä nopeasti kaikissa olennaisissa tapauksissa, eikä tapahdukaan. Asymptotiikkaan nojaaminen usein merkittävästi keventää laskennallista taakkaa ja vapautuneelle laskentateholle lopulta aina löytyy käyttöä, minkä vuoksi suurten otosten approksimaatioita tultaneen jatkossakin hyödyntämään paljon. Tilastotieteestä löytyy kuitenkin paradigmoja, jotka nojaavat vähemmän todennäköisyysteorian asymptoottisiin tuloksiin. Yksi tällainen on ns. Bayes-laskenta tai -filosofia, joka saa nimensä 1700-luvulla eläneeltä tilastotieteilijä-filosofi-pappi Thomas Bayesiltä.
Kappaleessa 2 käsittelimme lyhyesti Bayesin kaavaa ja tämän kappaleen kontekstissä sitä voidaan soveltaa kohdeparametrin \(\theta\) jakauman ratkaisemiseen aineistosta seuraavasti. Toisin kuin ns. frekventistisessä tilastotieteessä, Bayes-tilastotieteessä todennäköisyyksiä käytetään myös kuvaamaan ja tarkentamaan subjektiivista uskomusta matemaattisesti. Sinulla ja minulla voi siis olla eri jakauma parametrille \(\theta\) riippuen paitsi havaitsemistamme aineistoista myös niistä riippumattomista ennakko-, eli a priori uskomuksista, jotka operationalisoimme a priori todennäköisyysjakaumalla \(p(\theta)\). Voimme toki tutkia estimaatteja molempien a priori jakaumille ja mahdollisesti suurelle joukolle muitakin ennakko-oletuksia, mikä lisää käsitystämme päätelmien herkkyydestä oletuksille. Kullekin oletukselle saadaan juuri tiettyyn otokseen ja otoskokoon liittyvä tarkka jakaumaestimaatti, ei vain epämääräisesti ilmaistuun “suureen otokseen” nojaavaa approksimaatiota. Bayes-laskenta voi siis huomattavasti rikastaa suurten lukujen teoriasta johdettuja arvioita koskevaa ymmärrystä. Kääntöpuolena on, että laskut usein muodostuvat monimutkaisemmiksi, hitaammiksi/laskentaintensiivisemmiksi ja monipuolisemmiksi, ja siis paitsi informatiivisemmiksi myös työläämmiksi läpikäydä. Joissain tapauksissa Bayes-menetelmin voidaan ratkaista ongelmia, jotka ovat hankalia frekventistisesti, ja kääntäen. Kirjallisuudessa on myös hyvin paljon filosofista debattia siitä kumpi soveltavan todennäköisyyden tulkinta on oikeampi, mutta soveltajat lisääntyvissä määrin hyödyntävät molempia nojaten yo. pragmaattisiin näkökulmiin.
Uskottavuusfunktiota voidaan ajatella myös havaitun aineiston todennäköisyystiheytenä tai pistetodennäköisyysfunktiona ehdolla tietty parametrin arvo \(\theta\), tyypillisesti merkiten \(p(y|\theta) = f_Y(y;\theta)\). Bayes-tilastotieteessä parametria \(\theta\) koskevaa uskomusta \(p(\theta)\) päivitetään Baysin kaavaa soveltamalla seuraavasti
missä oikean käden jakajassa näemme kokonaistodennäköisyyden kaavan käytössä. Bayesin kaava näyttää petollisen helpolta soveltaa, mutta käytännössä juuri kokonaistodennäköisyyden laskemin on monille malleille hyvin hankalaa. On toki ns. konjugaattijakaumia, joille Bayesin käänteistodennäköisyys on \(p(\theta| y)\) helppo ratkaista. Usein ratkaisut kuitenkin nojaavat jonkinlaiseen “Monte Carlo” estimointiin, jossa joudutaan tuottamaan suuria määriä satunnaisotoksia tavalla, jonka epäsuorasti tiedetään tuottavan otoksia jakaumasta \(p(\theta| y)\). Jakauman ominaisuuksia arvioidaan sitten näistä satunnaisotoksista, joiden tuottaminen voi olla hyvinkin laskentaintensiivistä, jos \(\theta\) on kovin useaulotteinen, aineisto \(y\) hyvin suuri tai satunnaistanta-algoritmi tehoton ko. mallille.
5.6 Kirjallisuutta tilastollisesta päättelystä
Esitietovaatimuksia minimoidaksemme, tässä tekstissä olemme pyrkineet etenemään ilman merkittävää lineaarisen algebran ja vektorilaskennan (monimuuttujalaskennan) tuntemusta. Yleisesti ottaen, käsitellyt tulokset yleistyvät myös usea-ulotteisille parametreille. Lineaarialgebran kurssin ja mahdollisesti matemaattisen analyysin kurssit käyneelle lukijalle löytyy hyviä kotimaisia (Nieminen and Saikkonen 2013) ja englanninkielisiä (Casella and Berger 2002) tekstejä tässä kappaleessa keskusteltujen tilastollisen päättelyn sisältöjen syvällisempään käsittelyyn. Myös Bayes-päättelystä löytyy suosittuja tekstejä soveltajille ja alue on muodostumassa yhä tärkeämmäksi tuntea jossain määrin (McElreath 2020).
Erityisesti yllä käsitellyistä osatodistuksista, lukija toivottavasti sai syvällisempää käsitystä kuinka todennäköisyysteoriaa mm. tilastotieteessä sovelletaan. Yleisimpien taustaperiaatteiden tuntemuksesta pitäisi olla hyötyä monien tekstien lukemisessa, sillä kirjoittajat tyypillisesti olettavat yleisimmät asiat tunnetuiksi ja taustoittavat vähemmän yleisiä enemmän.
Casella, George, and Roger L. Berger. 2002. Statistical Inference. 2nd ed. Pacific Grove, CA, USA: Duxbury.
Laan, Mark J. van der, and Sherri Rose. 2011a. Targeted Learning: Causal Inference for Observational and Experimental Data. New York, US-NY: Springer.
———. 2011b. Targeted Learning: Causal Inference for Observational and Experimental Data. New York, US-NY: Springer.
Malkki, Veera, Suoma E. Saarni, Wolfgang Lutz, and Tom H. Rosenström. 2025. “Targeted Learning for Optimal Patient Assignment to Psychotherapy.”Psychotherapy Research, 1–15. https://doi.org/10.1080/10503307.2025.2517567.
McElreath, Richard. 2020. Statistical Rethinking: A Bayesian Course with Examples in r and Stan. 2nd ed. Boca Raton, US-FL: CRC Press.
Rosenström, Tom H., Nikolai O. Czajkowski, Ole André Solbakken, and Suoma E. Saarni. 2023. “Direction of Dependence Analysis for Pre-Post Assessments Using Non-Gaussian Methods: A Tutorial.”Psychotherapy Research 33 (8): 1058–75. https://doi.org/10.1080/10503307.2023.2167526.
Talkkari, Anna, and Tom H. Rosenström. 2024. “Non-Gaussian Liability Distribution for Depression in the General Population.”Assessment OnlineFirst (September): 10731911241275327. https://doi.org/10.1177/10731911241275327.