6 OSA 6: Uskottavuusfunktioon perustuvasta päättelystä
Edellisen OSAn verkkomateriaalissa käsittelimme hieman suurimman uskottavuuden estimointia regressiomallinnuksen kontekstissa. Sittemmin on selvinnyt, ettei uskottavuuspäättelyä käsitellä enää myöhemmissä tutkinnon menetelmäopinnoissa, joten käsittelemme sitä nyt tässä hieman tarkemmin. Lineaarisia sekamalleja käsitellään myöhemmillä kursseilla, joten niitä ei tällä kurssilla käsitellä OSAn 4 rajattuja esimerkkejä pidemmälle. Howellista tässä OSAssa on ohjelmassa General Linear Model -kappale. Se on teknisesti selkeä, mutta tulkinnallisesti otamme siihen aluksi hieman etäisyyttä, tai perspektiiviä. Ko. asian käsiteltyäni, siirryn uskottavuuspäättelyyn ja esimerkkiin, jonka kannalta erityisesti Howellin kappale 5 on relevantti. Tämä on siis myös hyvä tilaisuus palata ajatuksissa taaksepäin ja kerrata ko. materiaali kurssitenttiä silmällä pitäen. Lisäksi tämän materiaalin kannalta hyödyllistä on derivointisäännöt ja Howellin kannalta matriisilaskenta, joten luennolla annetaan pohjatietoja niistä.
6.1 Syy-seuraussuhteista ja yleisestä lineaarisesta mallista
Varoittaessaan havaintoaineiston käytöstä, Howell viittaa 60-luvun kirjoituksiin, kuten: “Anderson (1963) made a similar point by stating, “One may well wonder exactly what it means to ask what the data would be like if they were not what they are” (p. 170).” Sitten 60-luvun, ja varsinkin viimeaikoina, tilastollisen tutkimuksen nykyiset huiput ovat paljonkin asiaa miettineet. Kuitenkin jo 70-luvun loppupuolella Donald Robin esitteli kuuluisan potentiaalisten lopputulemien viitekehyksensä (potential outcomes framework, counterfactual outcomes framework, Rubin’s causal model, jne.), jota Jerzy Neyman ilmeisesti ehdotti jo 1923. Joku voisikin kysyä miksi Andersonin kaltaisia ihmettelijöitä yhä esiintyy, lukuisista tieteen tarjoamista vastauksista huolimatta. Yksi syy lienee, että älyllisen laiskuuden näkökulmasta on houkuttelevaa yksinkertaistaa maailma mustavalkoiseksi ja olennaisesti ajatella, että kokeet ovat yhtä kuin syy-seurauspäättely ja muut havainnot jotain muuta. Nimittäin, t-testi kahdelle ryhmälle on tässä kontekstissa verrattain helppo juttu ja saattaa kohottaa kompetenssin kokemusta, jos joku vielä vakuuttaa, että se riittää ja on itse asiassa parasta mitä on. Harvoinpa se riittää. Kokeet eivät ole autuaaksi tekevä vastaus joka kysymykseen. Vanhat “malliesimerkki-tieteet”, kuten fysiikka, eivät ole koskaan nojanneet eksklusiivisesti kokeisiin. Eikä ajatus ole kestävä edes informaatioteoreettisesta näkökulmasta (vrt. esim. dimensionaalisuus-kiroukset). Silti nämä todellisuuden rajoitteet rutiininomaisesti ohitetaan joissain empirian nimeen vannovissa piireissä. Älä sinä lankea tähän ansaan ja myöhemmin muistele Howellista yo. lainauksia, vaan mieluummin vaikka hänen omaa moderoidumpaa tulkintaansa: “Anyone using covariance analysis, however, must think carefully about her data and the practical validity of the conclusions she draws”. Itse asiassa, saman huomion voi yleistää kaikkiin tilastollisiin analyyseihin, yksinkertaisimmat mukaan lukien.
Aineistoanalyysin yksinkertaisuus ei tee maailmasta yhtään yksinkertaisempaa, vaikka se voikin näyttää vähemmän maailmasta ja siksi siltä tuntua. Myöskään analyysin vaihtaminen “laadulliseen” (ei-numeeriseen) tulkintaan ja havainnointiin ei poista maailman monimutkaisuutta ja tilastollisen harhan mahdollisuutta, mutta monesti kyllä tekee harhan havaitsemisesta hyvin paljon vaikeampaa. Kääntäen, se tekee itsensä huijaamisesta helpompaa. Tästä syystä haluamme tehdä numeerisia kokeita, mutta emme vain kokeita. Haluamme yleisemminkin ymmärtää maailmaa numeroiden valossa ja mallintaa mitä tapahtuisi, jos maailma ei olisi, kuten se juuri havaittiin. Tämä on keskeinen askel, jonka kautta kykymme kuvitella parempi maailma muunnetaan kyvyksi parantaa maailmaa. Siinä tehtävässä varovaisuus on paikallaan, mutta henkisesti laiska änkyröinti vain tiellä.
6.2 Uskottavuuspäättely
6.2.1 Perus-esimerkki
Oletetaan, että olemme kiinnostuneita suhteellisesta osuudesta, joka tietynlaisista syöpäpotilaista selviää ja paranee. Merkitään tuota osuutta parametrilla \(\theta_0\), missä \(0 \le \theta \le 1\). Oletetaan, että olemme havainneet \(n\) kappaletta tällaisia potilaista. Howellin kappaleen 5 mukaisesti, selviävien potilaiden lukumäärä \(k\), missä \(k \le n\), on binomijakautunut tuntemattomalla “onnistumistodennäköisyyttä” kuvaavalla parametrilla \(\theta_0\). Tarkemmin, jos \(X\) on selviäjien lukumäärä ja ajatellaan satunnaismuuttujaksi, sen parametrista \(\theta\) riippuva todennaköisyysjakauma on
\[ P_{\theta, N}(X = k) = \frac{N!}{(N-k)!k!} \theta^{k} (1 - \theta)^{N-k}. \]
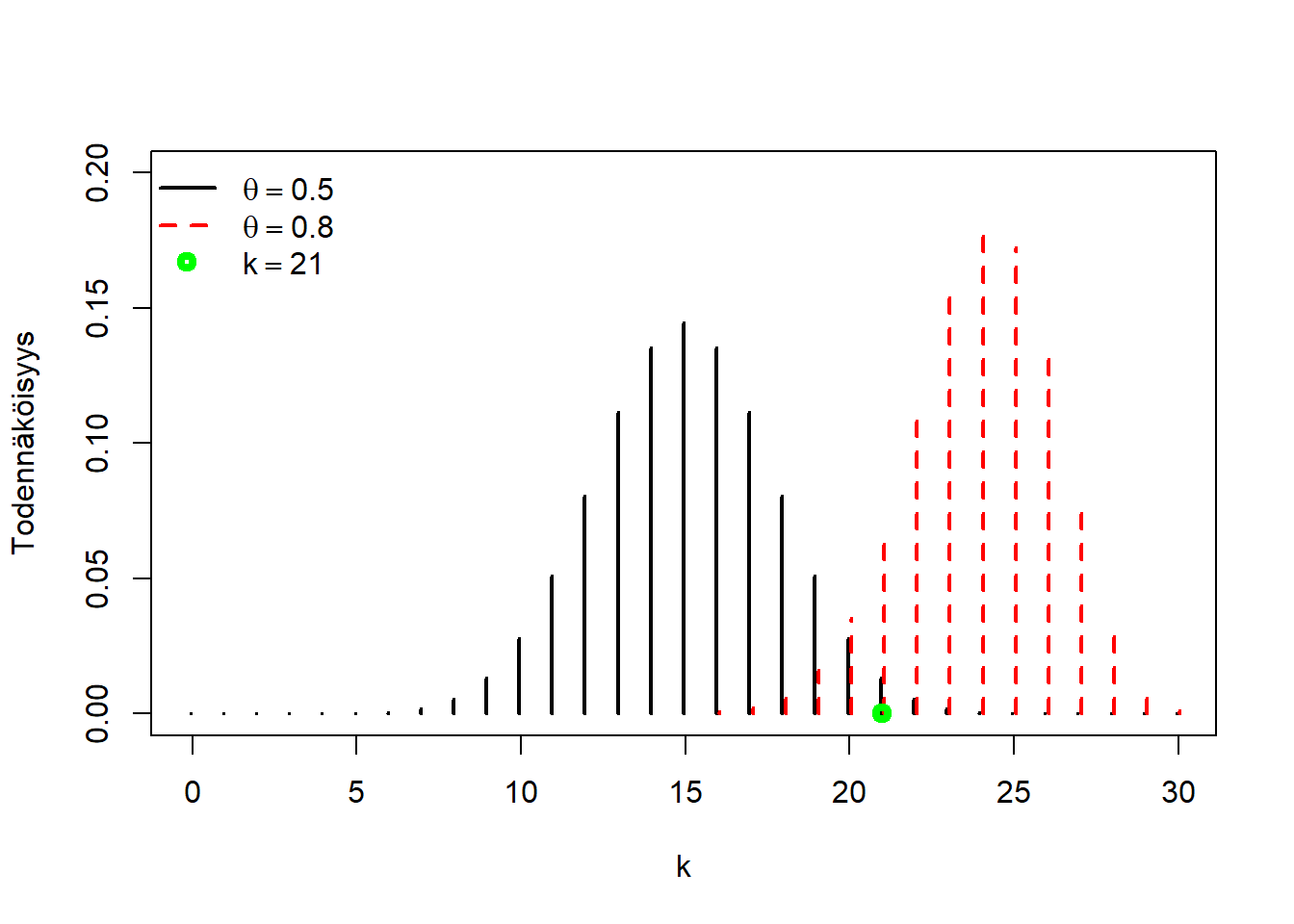
Alla oleva kuva esittää kaksi tällaista jakaumaa. Toisessa \(\theta = 0.5\) ja toisessa \(\theta = 0.8\), kun oletetaan potilasjoukko \(N = 30\). Jos ajatellaan vihreän pallon osoittamaa havaintoa \(X = 21\), eli arvoa \(k = 21\), sellainen havainto olisi uskottavampi, jos tuntemattoman parametrin arvo olisi \(\theta = 0.8\), kuin sen ollessa \(\theta = 0.5\). R:ssä voimme laskea, että se olisi dbinom(21,30,0.8)/dbinom(21,30,0.5) = 5.0706024 kertaa uskottavampi tulkinta. Luonnollisestikaan, meillä ei ole ilmeistä syytä rajoittua juuri näihin kahteen mahdolliseen tulkintaan piilevän parametrin arvosta \(\theta_0\). Sen sijaan, voisimme kysyä suoraan mikä on aineiston valossa kaikkein uskottavin arvo parametrille \(\theta\)? Ratkaisu, ja siis vastaus tähän kysymykseen, on niin kutsuttu suurimman uskottavuuden estimaatti (maximum likelihood estimate). Yleisemmin, kun viittaamme samaan prosessiin mille hyvänsä \(k\) ja \(n\), puhumme suurimman uskottavuuden estimaattorista (estimator).
Kun ajattelemme yllä nähtyä todennäköisyys-jakauman arvoa1 jollekin kiinnitetylle aineistolle (kiinnitetyille \(n\) ja \(k\)), mutta vaihtelevalle mahdolliselle parametrille \(\theta\), jakauman arvo on ko. \(\theta\)-parametrin funktio. Merkitään tätä funktiota symbolilla \(f(\theta; k, n)\), missä siis:
\[ f(\theta; k, n) = P_{\theta, N}(X = k). \]
Yllä nähdyssä esimerkissä siis funktio oli \(\theta \mapsto f(\theta; 21, 30)\) ja tutkimme sen arvoa kahdessa pisteessä, \(\theta = 0.5\) ja \(\theta = 0.8\). Suurimman uskottavuuden estimaattori \(\hat{\theta}\) on siis se arvo, joka maksimoi tämän uskottavuusfunktion (likelihood function). Koska logaritmi on järjestyksen säilyttävä funktio, eli monotoninen funktio, suurimman uskottavuuden estimaattori on myös sama asia kuin luku, joka maksimoi log-uskottavuusfunktion \(\theta \mapsto \log(f(\theta; k, N))\). Tätä hyödynnetään mm. laskujen yksinkertaistamiseen, keskeisen raja-arvolauseen käyttöön sekä numeerisen tarkkuuden tueksi.
6.2.2 Suurimman uskottavuuden estimointi
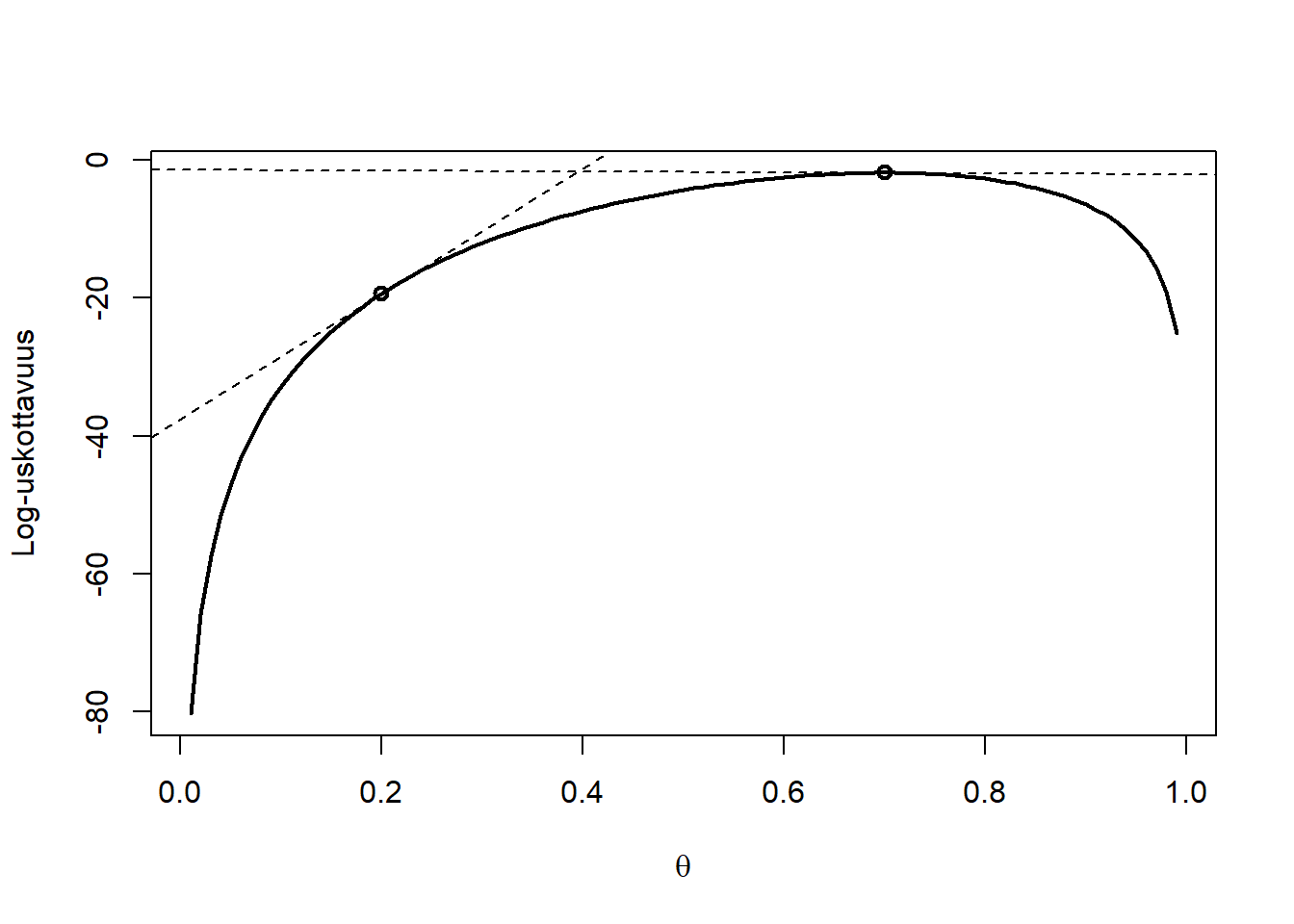
Lukiosta kenties muistamme, että jatkuvan funktion maksimikohdat löytyvät derivaatan nollakohdista. Derivaatta on funktion muutosnopeus tietyssä pisteessä. Koska se kuvaa funktion \(f\) hyvin pientä muutosta \(df\) argumenttinsa \(\theta\) muuttuessa hyvin vähän, vain \(d \theta\), suhteellista muutosta \(\frac{d}{d \theta}f(\theta)\) voidaan ajatella suoran kulmakertoimena. Jos suora asetataan esimerkiksi kohtaan \(\theta^*\), saadaan funktion tangentti ko. pisteessä, joka on suora \(\theta \mapsto f(\theta^*) + (\frac{d}{d \theta}f(\theta^*)) (\theta - \theta^*)\). Alla oleva kuva näyttää yllä käsitellyn Log-uskottavuusfunktion kaksi tangenttia, toinen kohdassa \(0.2\) ja toinen suurimman uskottavuuden pisteessä \(0.7\). Näemme, että suurimman uskottavuuden pisteessä tangentti on horisontaalisen akselin (\(\theta\)-akselin) suuntainen, koska siinä pisteessä derivaatta on nolla ja tangenttifunktio ei siis muutu \(\theta\):n funktiona lainkaan. Derivaatta asettuu nollaksi funktion huippukohdassa, koska juuri siinä pisteessä muutossuunta vaihtuu kasvavasta (positiivinen derivaatta) laskevaksi (negatiivinen derivaatta), ja siis derivaatta-funktio leikkaa nollatason. Yksi tapa löytää suurimman uskottavuuden estimaattori onkin siis ratkaista derivaatan funktio ja sitten sen nollakohdat (joita voi teoriassa olla useita).
Ratkaistaan siis binomijakaumaan liittyvän log-uskottavuusfunktion derivaatta. Sitä varten on huomattava jälleen, että logaritmi muuttaa tulot summiksi, ja siis tulon \(a^n = a \times a \times \cdots \times a\), jossa on \(n\) kappaletta tulotekijöitä, summaksi \(\log(a^n) = \log(a) + \log(a) + \cdots + \log(a) = n \log(a)\). Sovelletaan siis alla ensin tätä laskusääntöä binomijakaumaan liittyvään uskottavuus-funktioon, sen log-uskottavuusfunktion sieventämiseksi, ja käytetään sitten derivoinnin laskusääntöjä (vrt. luento tai esitiedot):
\[ \begin{align} \frac{d}{d\theta} \log f(\theta;k,n) &= \frac{d}{d\theta} \Big( \log \binom{n}{k} + \log \theta^{k} + \log\{ (1 - \theta)^{n - k} \} \Big) \\ &= k \frac{d}{d\theta} \log \theta + (n - k) \frac{d}{d\theta} \log(1 - \theta) \\ &= \frac{k}{\theta} - \frac{n - k}{1 - \theta}. \end{align} \]
Asettamalla yo. nollaksi, saadaan ratkaisu \(\theta = k/n\), eli binomijakauman parametrin suurimman uskottavuuden estimaattori. Tämä sattuu siis myöskin olemaan havaintojen keskiarvo \(\frac{1}{n} \sum_{i=1}^{n} x_i\), kun tiedämme, että summassa \(\sum_{i=1}^{n} x_i\) on \(k\) kappaletta ykkösiä ja \(n - k\) kappaletta nollia. Eli yleiselle havainnolle (satunnaismuuttujille), suurimman uskottavuuden estimaattori on \(\hat{\theta} = \frac{1}{n} \sum_{i=1}^n X_i\). Se on siis tavallinen keskiarvo, jonka tiedämme lähestyvän normaalijakautunutta satunnaismuuttujaa keskeisen raja-arvolauseen nojalla. Tämä havainto pätee yleisemminkin, kuten alla todetaan.
Pohditaan ensin kuitenkin vähän yleisempiä suurimman uskottavuuden estimaattoreita. Yllä nähty esimerkki on tärkeä ja pedagoginen, mutta monimutkaisemmissa malleissa parametri \(\theta\) on tietysti vektoriarvoinen, eli sisältää useita skalaariparametreja. Uskottavuusfunktion derivointi voi myös olla vaikeaa ja analyyttinen ratkaisu maksimille saavuttamattomissa. Tällöin voidaan käyttää numeerisia menetelmiä. Useaulotteiseen derivaattaan viitataan gradienttina, ja merkitään \(\nabla_{\theta} \ell(\theta)\). Gradientti näyttää mihin suuntaan log-uskottavuusfunktio \(\ell(\theta)\) kasvaa pisteessä \(\theta\) ja monet numeeriset menetelmät askeltavat iteratiivisesti gradientin osoittamaan suuntaan, kunnes löytävät log-uskottavuusfunktion huippukohdan. Usein tilastollisen estimointialgoritmin “konvergoituminen” viittaa tällaisen prosessin onnistumiseen ja “konvergenssivirheet” sen epäonnistumiseen. Luonnollisestikin jatkopäättely on luotettavaa vain, jos suurimman uskottavuuden estimaattori löytyy ja sitä etsivä numeerinen algoritmi konvergoituu ko. ratkaisuun. Algoritmeja on lukuisia, emmekä syvenny niihin tässä tämän enempää. Niitä kohdattaessa on kuitenkin hyvä olla edes jonkinlainen mentaalinen kartta siitä mitä ne tavoittelevat ja siinä jo tämäkin teksti (ja luennon visualisointi) voi auttaa.
6.2.3 Uskottavuuspäättely
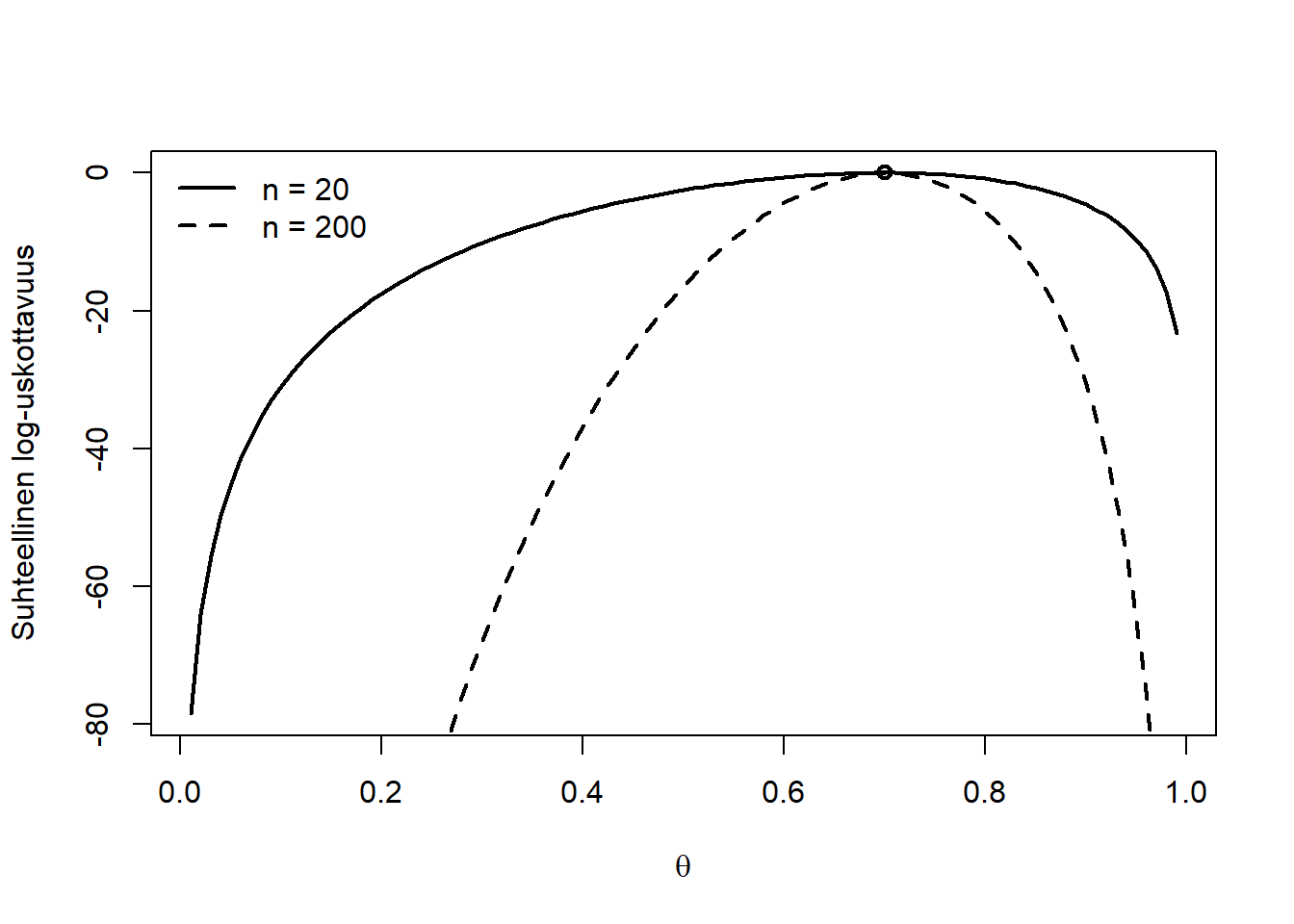
Log-uskottavuusfunktiota merkitään usein lyhyesti \(\ell(\theta)\), tai \(\ell(\theta; X)\), kun halutaan korostaa riippuvuutta havainnoista \(X=(X_1, X_2, \ldots, X_n)\). Yllä tarkastelimme log-uskottavuusfunktion ensimmäistä derivaattaa \(\frac{d}{d \theta} \ell(\theta) =: \ell'(\theta)\). Totesimme suurimman uskottavuuden estimaattorin (funktion maksimin) löytyvän derivaatan nollakohdasta. Kuitenkin myös funktion minimit löytyvät derivaatan nollakohdista. Onneksi tiedämme, että maksimipisteessä toinen derivaatta \(\ell''(\theta)\) on negatiivinen, eli ensimmäinen on laskeva funktio (mieti miksi). Eli suurimman uskottavuuden estimaattori löytyy sellaisesta derivaatan nollakohdasta, jossa toinen derivaatta on negatiivinen. Jos näitäkin on useita, on tarkistettava missä niistä funktio saa suurimman arvonsa. Toisella derivaatalla on toinenkin tärkeä rooli tilastollisessa päättelyssä. Sen absoluuttinen arvo nimittäin kuvaa sitä, kuinka jyrkästi log-uskottavuusfunktio kaareutuu nollakohtansa ympärillä. Sitä negatiivisempi on \(\ell''(\hat{\theta})\) mitä jyrkemmin \(\ell\) putoaa lakipisteensä \(\hat{\theta}\) ympärillä. Tämä suure liittyy estimaattorin keskivirheeseen ja otoskokoon. Tilannetta voidaan havainnollistaa tutkimalla suhteellista log-uskottavuusfunktiota \(\ell(\theta) - \ell(\hat{\theta})\) otoskoon suhteen:
Ajattele nyt yo. funktioiden gradienttia pitkin kiipeävää algoritmia, tai vaikka muurahaista, joka kävelee vastaavanlaista mäkeä. Lokaalissa ympäristössään muurahaisen on helpompi tietää saavuttaneensa mäen huipun, jos mäki kaareutuu jyrkästi, eli sen huippu on “terävä”. Jos taas funktio kaartuu hitaasti kuin maapallon pinta, voi olla vaikeaa edes havaita kaartumista paikallisesta asemastaan. Missä silloin on “huippukohta”? Tästä analogiasta näemme, että kaartuminen liittyy mallin parametrien huippukohtaa koskevan informaation määrään aineistossa. Yksittäiselle havaitulle aineistolle \(x\) voidaankin laskea havaittu informaatio \(j(\theta; x) := -\ell''(\theta; x)\). Yllä käsitellyn binomimallin, eli toistokokeen, tapauksessa havaittu informaatio voidaan ratkaista derivoimalla uudelleen yllä esitettyä kertaalleen derivoitua funktiota, josta seuraa
\[ j(\theta; x) :=-\ell''(\theta; x) = \frac{k}{\theta^2} + \frac{n - k}{(1 - \theta)^2}. \]
Sijoittamalla tähän \(\hat{\theta} = k/n\), saadaan \(j(\hat{\theta}; x) = \frac{n}{\hat{\theta}(1 - \hat{\theta})}\) ja nähdään havaitun informaation yhteys otoskokoon.
Teoreettisesti merkityksellinen suure on mallin odotettu informaatio, eli ns. Fisherin informaatio,2 joka voidaan laskea mille tahansa kuvitellulle tosiarvolle \(\theta\) ja merkitään seuraavasti:
\[ i(\theta) := \text{E}_{\theta}[-\ell''(\theta; X)]. \]
Fisherin informaatio on siis aineiston \(X\) funktion odotusarvo, jossa funktiona käytetään log-uskottavuusfunktion toisen derivaatan vastalukua. Fisherin informaatiolla on suora yhteys derivaatan otantavaihteluun (nimittäin \(\text{Var}[\ell'(\theta; X)] = i(\theta)\)). Kun havainnot ovat identtisesti jakaantuneita, sille pätee myös \(i(\theta) = n \times i_1(\theta)\), missä \(i_1(\theta)\) on yhden havainnon informaatio. Tässäkin mielessä se käyttäytyy, kuten summien varianssit. Voidaankin osoittaa, että riippumattomien havaintojen tapauksessa suurimman uskottavuuden estimaattori noudattaa keskeistä raja-arvolausetta ja sen poikkeamat voimassa olevasta nollahypoteesista \(\theta_0\) lähestyvät normaalijakaumaa seuraavasti:
\[ \sqrt{i(\hat{\theta}_n)} \big( \hat{\theta}_n - \theta_0 \big) \overset{\mathcal{D}}{\to} N(0, 1). \]
Identtisten riippumattomien havaintojen kohdalla pätee myös,
\[ \sqrt{n} \big( \hat{\theta}_n - \theta_0 \big) \overset{\mathcal{D}}{\to} N(0, \frac{1}{i_1(\theta_0)}). \]
Näiden raja-arvolauseiden lisäksi pätee liitännäinen ja edellisessä OSAssa keskusteltu Wilksin teoreema, joka mahdollisti uskottavuusosamäärätestit khi-toiseen-jakaumasta.
6.2.4 Tilastollisen päättelyn teoriasta
Uskottavuusfunktioon, eli yleiseen tilastolliseen malliin, perustuva päättely yleistää aiemmin nähtyjä yksittäisiä malleja koskevia huomiota melko mielivaltaisia tilastollisia malleja koskeviksi. Eli perusmalleja koskevat tulokset ovat uskottavuuspäättelyn erityistapauksia. Tässä käsitelty binomijakaumamallikin tulisi siis ymmärtää yksittäisenä esimerkkinä, jonka kautta havainnollistimme abstraktia teoriaa.
Tilastollisen teorian yleistäminen ei ainoastaan auta ymmärtämään vanhoja malleja ja johtamaan uusia, vaan yleisemmästä tilastollisesta teoriasta seuraa myös mm. erilaisia optimaalisuus-tuloksia. Voidaan esimerkiksi päätellä, että (säännöllisen) tilastollisen mallin parametrin harhattoman estimaattorin otosvarianssi voi olla alimmillaan \(1/i(\theta)\). Monesti juuri suurimman uskottavuuden estimaattorit saavuttavat ko. rajan, jolloin niiden tiedetään olevan täystehokkaita (fully efficient) parametrin \(\theta\) estimaattoreita, jotka usein (useimmille otoksille mallinnetusta populaatiosta) osuvat mahdollisimman lähelle tosiarvoa. Tämä tulos tunnetaan informaatioepäyhtälönä, tai Cramér-Rao raja-arvona.
Vaikkemme (ilmeisesti) varsinaisesti käsittelekään paljoa enempää suurimman uskottavuuden estimointia psykologian perustutkinnon menetelmäopinnoissa, se on kuitenkin taustalla läsnä koko ajan ja siksi tärkeää yleissivistystä, joka jäsentää ympäröivää maailmaa ja vastaan tulevia tekstejä. Ja maailma myös muuttuu. Kuka tietää, vaikka joidenkin meistä tulevaisuuden toimenkuvaan kuuluisi tekoälyjen käskyttäminen interventiomallien johtamisessa psykologian ja tilastotieteen yleisistä periaatteista, jolloin ei tietysti yhtään haittaisi tuntea niitä periaatteita. Vaikka elämä voi nyt tuntua kiireiseltä syvällistä tilastoteoreettista mietiskelyä ajatellen, opiskeluaika voi kuitenkin suhteessa olla siihen hyvinkin suotuisa hetki. Kerran ymmärretty ja luonteeltaan pysyvä yleinen periaate voi myös tarttua muistiin hyvin tehokkaasti verrattuna opintojen lukuisiin ajassa eläviin yksityiskohtiin. Kannattaa siis uhrata tovin verran ajatuksia tälle teoreettisemmallekin osiolle, vaikka emme tulekaan sitä kurssilla tiukan tarkasti kuulustelemaan.
6.3 Yhteenveto
- Suurimman uskottavuuden estimaattori maksimoi mallin uskottavuuden havaitun aineiston synnyttävänä teoriana.
- Log-uskottavuusfunktion toinen derivaatta miinus yhdellä kerrottuna liittyy aineistosta havaitun informaation määrään, ja odotusarvoinen havaittu informaatio liittyy suurimman uskottavuuden estimaattorin keskivirheeseen.
- Otoskoon kasvaessa, suurimman uskottavuuden estimaattorin poikkeamat nollahypoteesin mukaisesta tosiarvosta lähestyvät jakaumaltaan normaalijakaumaa, kun nollahypoteesi pätee.
- Uskottavuuspäättely yleistää frekventistisen tilastollisen päättelyn äärettömälle määrälle mahdollisia tilastollisia malleja.
- Vaikkemme tässä käsittelleet asiaa, on huomattava, ettei yllä kuvattu uskottavuusfunktioon perustuva päättely toimi aivan kaikille kuviteltavissa oleville malleille (eräiden yleisesti voimassa olevien mallin todennäköisyysjakaumaa koskevien matemaattisten säännöllisyysehtojen on toteuduttava).
6.4 Alaviitteet
Diskreetille jakaumalle jakaumafunktion arvo on todennäköisyys, mutta jatkuvalle tiheysfunktiolle ei.↩︎
Huomaa, että todennäköisyysteoriassa on muitakin informaatiokäsitteitä, kuten informaatioentropian käsitteeseen kytkeytyvä Shannonin informaatio, jota ei tässä käsitellä. Se on keskeinen mm. tietojenkäsittelytieteessä ja fysiikassa. Perinteisen tilastollisen päättelyn kannalta nimenomaan Fisherin informaatio on hyvin keskeinen konsepti. Sekin kyllä liittyy myös viimeaikaisempiin teoreettisiin aiheisiin, kuten tilastotieteen informaatiogeometriseen käsittelyyn.↩︎