Y <- c(1, 1, 0, 1, 0, 0)
A <- c(1, 1, 1, 0, 0, 0)
A==1[1] TRUE TRUE TRUE FALSE FALSE FALSEY[A==1][1] 1 1 0Y*(A==1)[1] 1 1 0 0 0 0mean(Y[A==1])[1] 0.6666667mean(Y*(A==1))[1] 0.3333333Tässä osiossa herätellään jatkumon aiempian kurssien ja ennen kaikkea PSYK-381-kurssin (Johdatus tilastolliseen tietojenkäsittelyyn) asioita aktiiviseen muistiin, tuodaan tärkeitä uusia käsitteitä, sekä käydään viimein ja muitta mutkitta kiinni koulutusohjelman tärkeimpään tilastotyökaluun, R-kieleen ja sen RStudio-kehitysympäristöön. RStudio on vain käyttö- ja kehitysympäristö R-kielelle, jota voi käyttää muissakin ympäristöissä. Ko. ympäristöä esitellään videomateriaaleissa ja oletettavasti laskuharjoitukssissakin, mutta tämä materiaali keskittyy R-kieleen ja kurssisisältöihin. Tällä kurssilla ei voi käyttää muuta kieltä kuin R, mikä on käytetyin avoin tilastotieteen ohjelmointikieli ja varsinkin psykologian parissa jo lähes edellytys kansainvälisen kirjallisuuden seuraamiselle. Toisaalta, jos jo osaat vastaavan tyyppisiä kieliä, kuten Python- tai Matlab-kieli, varsin saman tapaisen R:n omaksuminen kurssia seuraamalla on melko vaivatonta. Jos taas et osaa R-kieltä tai muutakaan ohjelmointia, varaudu alun käsitteellisiin haasteisiin, jotka kuitenkin työskentelyn myötä helpottuvat.
Aloita lukemalla Howellin kappale 5 ja katsomalla kurssin ensimmäisen osan R-esittelyvideot ja jatka sitten vasta tähän tekstiin ja tehtäviin. Toisin kuin Howell, tässä merkitsemme tapahtuman \(A\) todennäköisyyttä \(P(A)\) hänen \(p(A)\) merkintänsä sijaan. Kumpikin merkintätapa on käytössä laajasti, mutta iso P todennäköisyydelle (probability) sekoittuu vähemmän herkästi p-arvoihin ym. käsitteisiin. Etenkin tässä ensimmäisessä osassa, Howellin kirjan lisäksi nojaan Hernanin ja Robinsin Causal Inference: What If -kirjan materiaaliin. Pärjäät tällä kurssilla jälkimmäistä kirjaa konsultoimatta, mutta katson tarpeelliseksi sisällyttää tähän kurssimateriaaliin myös vähän Howellin kirjaa uudempia tuulia. Erityisesti, olisi tärkeää saada moderneja työkaluja syy-seuraussuhteiden formalisointiin. Nehän nimittäin kokeiden tekemistä motivoivat. Ja varsinkaan kliinisessä psykologiassa ei aina voida suorittaa kaikkia olennaisia kokeita, jolloin havaintoaineistoon nojaamista ei voida välttää ja on tärkeää tuntea missä olosuhteissa havaintoaineisto eroaa kokeellisesta ja missä ei.
Usein mittaamme hoitovaikutusta suureella, joka ajatellaan satunnaismuuttujaksi, koska olisi epärealistista odottaa vaikutuksen toteutuvan luotettavasti samansuuruisena jokaiselle potilaalle. Olkoon \(Y\) esimerkiksi oiremuutos tmv. vastemuuttuja ja \(A\) on hoitomuuttuja tai muu toimenpide (action), joka voi saada arvot \(1\) (aktiivinen hoito) ja \(0\) (referenssihoito). Olemme usein kiinnostuneita kysymyksestä kuinka paljon suurempaa hoitovaikutusta voi odottaa aktiiviselta hoidolta suhteessa referenssihoitoon, joka voi olla pelkkä plasebo-hoitokin:
\[ E[Y|A=1] - E[Y|A=0], \] missä \(E[Y|A=1]\) on hoitotuloksen odotusarvo ehdolla, että potilas on aktiivisessa hoidossa. Se määritellään seuraavasti
\[ E[Y|A=1] = \sum_{y \in \Omega} y P(Y=y|A=1). \] Tässä siis kukin mahdollinen hoitotulosarvo kerrotaan ehdollisella todennäköisyydellään ja tulotekijät summataan yhteen (jatkuva-arvoiselle \(Y\) summa korvataan integraalilla). Referenssihoidon odotusarvo \(E[Y|A=0]\) määritellään vastaavalla tavalla, mutta ehdolla, että \(A=0\). Tässä todennäköisyys \(P(Y=y|A=1)\) mittaa aktiivisen hoitotuloksen \(y\) yleisyyttä teoreettisessa populaatiossa, joka saattaa olla esimerkiksi kaikki nykyiset ja tulevat potilaat. Käytännössä tietysti joudumme arvioimaan teoreettisia odotusarvoja otoksesta potilaita, jotka usein ajattelemme otoksiksi teoreettisesta populaatiosta, eli toisistaan riippumattomiksi toisinnoiksi teoreettisesta satunnaismuuttujasta \(Y\). Merkitsemme otosta \(Y_1, Y_2, \ldots, Y_N\), missä \(N\) on potilaiden (havaintojen) lukumäärä. Teoreettisessa käsittelyssä havainnot ovat isolla kirjaimella merkittyjä satunnaismuuttujia, \(Y_1, Y_2, \ldots, Y_N\), mutta lopulta reaalimaailmassa tietysti tehdään havaintoja, jotka ovat pienellä kirjaimella merkittyjä realisoituneita lukuja, \(y_1, y_2, \ldots, y_N\). Aiemmilta kursseilta tiedämmekin, että paras arvio (estimaatti) teoreettiselle odotusarvolle on keskiarvo:
\[ \hat{E}[Y|A=1] = \frac{1}{N} \sum_{i=1}^N Y_i. \]
Kaksiluokkaiset vastemuuttujat ovat tärkeä erikoistapaus, jolloin merkitsemme esimerkiksi tapahtumia “potilas parantui” ja “potilas ei parantunut” teknisin merkinnöin \(Y=1\) ja \(Y=0\). Tällöin odotusarvo saa määritelmänsä mukaisesti muodon:
\[ \begin{array}{rl} E[Y|A=1] &= \sum_{y \in \{0, 1\}} y P(Y=y|A=1) \\ &= 0 \times P(Y=0|A=1) + 1 \times P(Y=1|A=1) \\ &= P(Y=1|A=1). \end{array} \]
Siten kaksiluokkaisella vastemuuttujalla mitattu aktiivisen hoidon vaikutus suhteessa referenssihoitoon on
\[ E[Y|A=1] - E[Y|A=0] = P(Y=1|A=1) - P(Y=1|A=0). \]
Tällaisen kaksiluokkaisen vastemuuttujan odotusarvon estimaatti on
\[
\begin{array}{rl}
\hat{E}[Y|A=1] &= \frac{1}{N} \sum_{i:A_i=1} Y_i \\
&= S_1/N_1 \\
&= \hat{P}(Y=1|A=1),
\end{array}
\] missä \(S_1\) on onnistuneiden hoitojen lukumäärä aktiivisessa hoidossa ja \(S_1/N_1\) niiden suhteellinen osuus, eli hoidon onnistumistodennäköisuuden \(P(Y=1|A=1)\) estimaatti aktiiviselle hoidolle. R-ohjelma laskee vastaavan odotusarvon havaintovektorille \(Y\) käskyllä mean(Y[A==1]), missä A==1 on vektori loogisia arvoja (TRUE tai FALSE -arvoja). Kun loogista vektoria käytetään indeksinä hakasulkujen sisällä, operaatio valitsee ne vektorin arvot, joiden indeksi on “tosi” (TRUE) ja jättää pois ne, joiden indeksi on “epätosi” (FALSE). Indeksöinti on kuitenkin hyvin eri asia kuin totuusarvoilla kertominen, jota myös alla hydöynnämme: R-ohjelma automaattisesti tulkitsee TRUE-arvolla kertomisen arvolla \(1\) kertomiseksi ja FALSE-arvolla kertomisen arvolla \(0\) kertomiseksi. Alla on esimerkit sekä loogisella arvolla indeksöinnistä että sillä kertomisesta:
Y <- c(1, 1, 0, 1, 0, 0)
A <- c(1, 1, 1, 0, 0, 0)
A==1[1] TRUE TRUE TRUE FALSE FALSE FALSEY[A==1][1] 1 1 0Y*(A==1)[1] 1 1 0 0 0 0mean(Y[A==1])[1] 0.6666667mean(Y*(A==1))[1] 0.3333333Käsittelemme kuvitteellista esimerkkiä, jossa potilaasi voivat saada uutta hoitoa \(A = 1\) tai tavanomaista hoitoa \(A = 0\). Hoito on siis muuttuja, joka voi saada arvoja \(0\) tai \(1\). Joissain tapauksissa voimme ajatella asettavamme hoidon, jolloin \(A\) on deterministinen muuttuja, toisissa se asettuu osin satunnaisesti, jolloin \(A\) on satunnaismuuttuja. Sovitaan esimerkin vuoksi, että uusi hoito on LOL-terapia, jossa tavanomaisen hoidon lisäksi potilaat laitetaan nauramaan ääneen (Laughing Out Loud) ja toivotaan negatiivisten käyttäytymismallien näin antavan sijaa positiivisille. Olkoon vastemuuttuja \(Y\) arvoltaan \(1\), jos potilas on muuttunut positiiviseksi hoidon jälkeen ja \(0\), jos hän edelleen on rasittava ja ikävä, eli ei-positiivinen. Tiedetään myös, että joillain ihmisillä on piilevä (latentti) taipumus huumorintajuttomuuteen, joka saattaa heikentää hoidon tehoa. Merkitsemme huumorintajuttomia muuttujan \(L\) arvolla \(L = 1\) ja muita \(L = 0\). Alla oleva taulu kerää esimerkin tulkinnat.
\[ \begin{array}{lcc} \hline \text{Muuttuja} & \text{Arvo } 0 & \text{Arvo } 1 \\ \hline A & \text{Tavanomainen hoito} & \text{LOL-terapia} \\ L & \text{Huumorintajuinen} & \text{Huumorintajuton} \\ Y & \text{Tulokseton hoito} & \text{Tuloksekas hoito} \\ \hline \end{array} \]
Esimerkki on tarkoituksellisen älytön, sillä tulemme luomaan aineiston R-kielellä, eli simuloimaan sen, emmekä halua sekoittaa simulaatiota todellisuuteen. Vaikka tämä voi äkkiseltään kuulostaa jonkin sortin huijaamiselta, ns. aineistoa generoivan mallin (data-generating model) simulointi on erittäin vahva työkalu omien ja toisten ajattelun varmentamiseen, koska se on matemaattista analyysia helpompaa ja sen ohella ainoa tilanne, jossa “tosimalli” tunnetaan. Osa tilastotieteilijöistä ajattelee, että kaiken tutkimuksen tulisi edetä oikean aineiston pariin vasta tällaisen teoreettisen järkevyystarkastelun jälkeen. Simulointitaitojen arvo myös kasvaa kohisten tekoälyn käytön lisääntymisen myötä, kun tilastollisen “reseptitiedon” saatavuus helpottuu, luotettavuuden samalla heikentyessä. Simulaatio ei takaa mallin toimivuutta oikeassa aineistossa, mutta usein olisi hyvä tietää toimiiko se edes ideaalisessa aineistossa. Simulaation tulos myös yllättää siinä määrin usein, että niiden suorittaminen kehittää tervettä epäluuloa aineistoanalyysejä kohtaan ja antaa keinoja niiden jälkiarviointiin, mikä johtaa kestävämpään tieteeseen.
R-kielessä on sisäänrakennettuna satunnaislukugeneraattori, joka luo tarkoituksiimme nähden riittävän satunnaisia lukuja. Tavalliset tietokoneet eivät kykene luomaan aidosti satunnaisia lukuja, vaan R hyödyntää algoritmia ja listaa alkuarvoista. Alkuarvon voi määrittää set.seed-käskyllä ja sama alkuarvo tuottaa aina samat satunnaisluvut. Tämä on erittäin hyödyllistä, sillä se mahdollistaa tulosten tarkan toistamisen, “satunnaisuudesta” huolimatta. Algoritmi luo välin \([0, 1]\) tasajakautuneita (uniformly distributed) satunnaislukuja, \(U \sim \mathcal{U}([0, 1])\), mutta se riittää pitkälle. Nimittäin tällöin \(F^{-1}(U)\) jakautuu kertymäfunktion \(F\) mukaisesti, kun \(F^{-1}\) on ko. kertymäfunktion käänteisfunktio (eli \(F^{-1}(F(u))=u\) kaikilla \(u\)). Tämä johtuu siitä, että \(F(u)\) kuuluu aina välille \([0, 1]\) todennäköisyyden määritelmän mukaisesti, jolloin sen käänteisfunktion on edustettava jakauman mukaisia satunnaismuuttujan arvojen “yleisyyksiä”. Matemaattisten todisteluiden sijaan, katsomme kuinka asia R-ympäristössä toimii.
# Asetetaan satunnaislukugeneraation alkuarvo
set.seed(2026)
# luodaan 5000 tasajakautunutta arvoa
u <- runif(5000)
# muunnetaan ne standardinormaalikertymäfunktion käänteisfunktiolla
z <- qnorm(u)
# Piirretään normaalijakauma, sen kertymäfunktio, ja u:n ja z:n histogrammit
par(mfrow=c(2, 2)) # asetetaan 4 paneelia grafiikkakoneelle
x <- seq(-3,3, length.out=100) # arvoja jakauman piirtämiseen
plot(x, pnorm(x), type="l", lwd = 2, main = "Kertymäfunktio",
ylab = "F(x), eli u", xlab = "z")
x <- seq(0.005,0.995, length.out=100) # arvoja jakauman piirtämiseen
plot(x, qnorm(x), type="l", lwd = 2, main = "Käänteiskertymäfunktio",
ylab = expression(F^-1~(u)), xlab = "u")
hist(u, main = "U:n histogrammi")
hist(z, main = expression(F^-1~(U)~":n histogrammi"))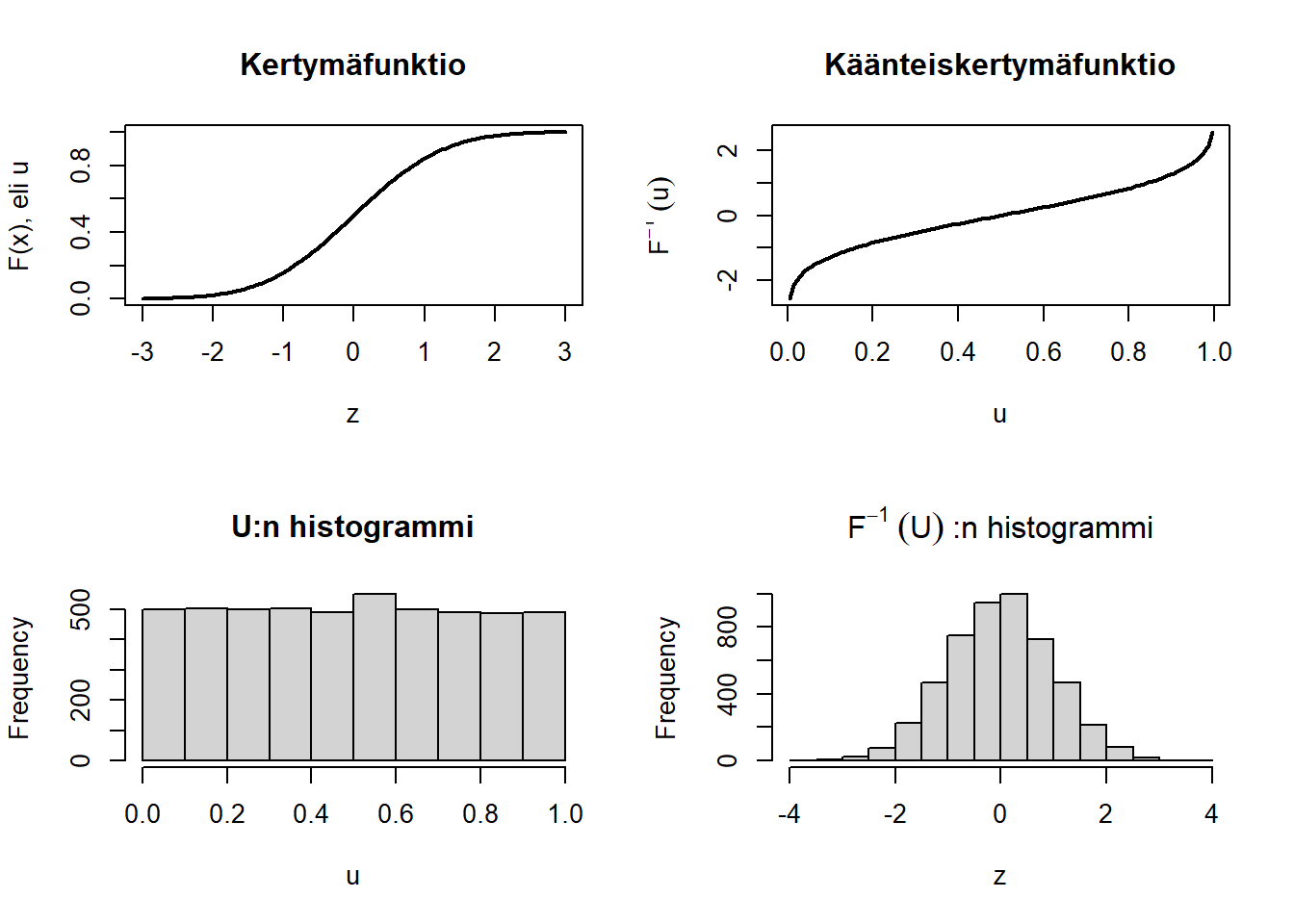
Yllä kohtasimme joitain R-kielen yleisiä merkintätapoja. Yleensä “r” jakaumanimen edessä viittaa kyseisen jakauman satunnaislukugeneraattoriin. Tässä runif siis on yhdistelmä “r” + “unif”, missä jälkimmäinen lyhenne viittaa tasajakaumaan (uniform distribution). R-funktio rnorm tuottaisi satunnaisia normaalijakautuneita lukuja, mutta yllä teimme niitä itse tasajakautuneista satunnaisluvuista, hyödyntämällä kvantiilifunktiota qnorm. Tässä “q” viittaa kvantiilifunktioon (quantile function), eli kertymäfunktion käänteisfunktioon, ja “norm” viittaa normaalijakaumaan (oletusarvoisesti standardinormaalijakaumaan, jonka keskiarvo on 0 ja varianssi 1). Esimerkiksi qnorm(0.025) antaa tutun kaksisuuntaista merkitsevyystasoa 0.05 vastaavan poikkeaman piste-estimaatista, eli noin -1.96. Vastaavasti “p”, kuten funktiossa pnorm, antaa kertymäfunktion, eli todennäköisyyden (probability) tapahtumalle, että satunnaismuuttujan arvo on välillä miinus äärettömästi arvoon johonkin arvoon \(x\). Eli \(F(x) = P(X \le x)\). Esimerkiksi, pnorm(-1.96) antaa suurin piirtein arvon 0.025. Kokeile tätä itse R:ssä!
Jos \(U \sim \mathcal{U}([0, 1])\), eli \(U\) jakautuu tasaisesti välillä \([0, 1]\), ja myös \(p\) on tuon välin lukuarvo, niin \(P(U \le p) = p\). Tämä on oikeastaan tasajakauman määritelmä – jokainen osaväli kontribuoi pituutensa verran todennäköisyysmassaa. Bernoulli-jakauma taas määritellään seuraavasti: \(X \sim Bernoulli(p)\), kun \(P(X=1) = p\) ja \(P(X=0) = q = 1 - p\). Tapahtumaa \(X = 1\) ajatellaan usein “onnistumisena” ja tapahtumaa \(X = 0\) “epäonnistumisena”, tai vaihtoehtoisesti vain jokin asiaa sattuu vs. ei satu. Näemme, että LOL-terapiaesimerkkiin liittyvät muuttujat ovat Bernoulli-jakautuneita, jollain sattumistodennäköisyydellä \(p\), joka luultavimmin eroaa muuttujien välillä. Merkitään muuttujiin \(A, L, Y\) liittyviä sattumistodennäköisyyksiä \(p_A, p_L, p_Y\). Bernoulli-jakautuneita muuttujia halutuin sattumistodennäköisyyksin saadaan siis luotua tasajakautuneista satunnaisotoksista, kuten yllä perusteltiin teoriassa ja alla kohta toteutamme käytännössä. Luodaan siis nyt aineisto seuraavan ajatusleikin mukaisesti. Toista itsekin nämä vaiheet R-ohjelmassa ja luo aineisto itsellesi. Tässä luomme hyvin suuren (miljoonan hlön) aineiston, jotta vältymme pohtimasta satunnaisotannan vaikutuksia – palaamme niihin kurssin myöhemmissä osissa.
Ajatellaan, että huumorintajuttomuus on yksilön ominaisuus, joka on kehittynyt ennen hoitoa ja sen kohdehäiriötä. Simuloidaan minimaalinen yksilöitä koskeva tieto, eli ovatko he huumorintajuisia vai eivät. Tämä voi olla piilevää tietoa kokeen tekijälle ja kokeen kannalta sekoittava tekijä, mutta aineistoa luovan mekanismin ja siis “simuloijan” näkökulmasta se tunnetaan.
set.seed(2026)
N <- 10^6 # henkilöiden lkm (1 miljoona)
pL <- 0.4 # huumorintajuttomuuden yleisyys (osuus) populaatiossa
L <- (runif(N) <= pL)*1 # satunnaisotanta populaatiosta
L[1:10] # katsotaan kymmenen ensimmäistä arvoa [1] 0 0 1 1 0 1 0 0 1 0Nyt meillä on vektorina joukko realisoituneita \(L\) muuttujan arvoja. Ykkösellä kertominen yllä muutti TRUE/FALSE-arvot 1/0-arvoiksi, mutta kumpikin merkintä olisi vain merkintä huumorintajuton/huumorintajuinen-ominaisuuksille. Tässä joukossa huumorintajuttomien osuus on 0.400047, eli hyvin lähelle tasan \(0.4\), ja pieni ero johtuu satunnaisotannasta. Voit itse kokeilla kuinka ero suurenee, jos tutkit pienempää otosta, esimerkiksi valitsemalla vain havainnot 1:stä n:nteen seuraavasti:
mean(L[1:30]) # satunnaisotanta populaatiosta, n = 30[1] 0.6mean(L[1:60]) # satunnaisotanta populaatiosta, n = 60[1] 0.4666667mean(L[1:500]) # satunnaisotanta populaatiosta, n = 500[1] 0.406mean(L[1:10000]) # satunnaisotanta populaatiosta, n = 10000[1] 0.4022Huomaa kuitenkin vaihtelu tuloksissa, jos ajat saman koodin uudestaan määrittämättä satunnaislukualkuarvoa. Tällöin R jatkaa algoritmia eri kohdasta ja tuottaa siis (satunnaisvaihtelun puitteissa) eri tulokset. Hallitaan tilannetta kuitenkin hetki vielä ja luodaan loput LOL-aineistostamme, sekä asetetaan se aineistojen käsittelyä varten luotuun R-kielen aineistotaulu-objektiin.
pY <- 0.4 # hoidon onnistumistodennäköisyys
he <- 0.2 # LOL-lisähoidon hoitoefekti
le <- -0.3 # piilovaikutus (huumorintajuttomuuden)
u <- runif(N)
Y0 <- (u <= pY + he*0 + le*L)*1 # hoitotulos, jos A = 0
Y1 <- (u <= pY + he*1 + le*L)*1 # hoitotulos, jos A = 1
LOLdata <- data.frame(id = 1:N, L = L, Y0 = Y0, Y1 = Y1) # asetetaan aineisto
head(LOLdata) # katsotaan aineiston 6 ensimmäistä riviä id L Y0 Y1
1 1 0 0 0
2 2 0 0 0
3 3 1 1 1
4 4 1 0 0
5 5 0 0 0
6 6 1 0 0Tässä siis LOLdata on erityinen listaobjekti, jossa listan alkiot ovat muuttujan havaintovektoreita. Näihin vektoreihin, eli kaikiin muuttujan havaittuihin arvoihin, voidaan viitata dollarimerkillä ja muuttujan nimellä, dataobjektin perään kirjoitettuna. Kokeile ajaa R-konsolissasi käsky LOLdata$L, kun olet luonut aineiston esimerkkiä kopioiden. Datataulu (data frame) on sikäli erikoinen lista, että havaintovektoreiden on oltava yhtä pitkiä ja yksittäiseen skalaarihavaintoon voidaan viitata määrittämällä sen rivi ja sarakeindeksit. Aja nyt seuraavat käskyt R:ssä yksi kerrallaan (yo. aineiston luovien käskyjen jälkeen) ja mieti mitä niissä tapahtuu: head(LOLdata), LOLdata$L[3], LOLdata[3,2], LOLdata[3,].
Hoitoefekti voidaan määritellä nyt mm. seuraavasti \(ATE = E[Y^{A=1} - Y^{A=0}] = E[Y^{A=1}] - E[Y^{A=0}]\), tai lyhyemmin \(ATE = E[Y^{1}] - E[Y^{0}]\), missä \(E\) on odotusarvo-operaatio, \(ATE\) viittaa sanoihin average treatment effect ja \(Y^{1}\) on hoitotulos LOL-lisähoidolla (kun \(A = 1\)) ja \(Y^{0}\) on hoitotulos tavanomaisella hoidolla. Esimerkiksi, \(Y^{1}\) on satunnaismuuttuja, jolle olemme juuri luoneet \(N\) arvoa, tässä miljoona arvoa. Voimme siis laskea ATE-arvon seuraavasti:
ATE <- mean(LOLdata$Y1 - LOLdata$Y0)
ATE[1] 0.200345# vaihtoehtoinen laskutapa
with(LOLdata, mean(Y1) - mean(Y0))[1] 0.200345# vaihtoehtoinen laskutapa keskiarvo "käsin" laskien
with(LOLdata, sum(Y1 - Y0)/N)[1] 0.200345Tulos tarkoittaa, että keskimääriin potilas paranee 20 prosenttiyksikköä todennäköisemmin LOL-terapiassa kuin tavanomaisessa hoidossa, tai vaihtoehtoisesti, 20 prosenttiyksikköä suurempi osuus potilaista paranee. Yllä nähtyjä havaintovektoreita Y1 ja Y0 kutsutaan kontrafaktuaalisiksi lopputulemiksi, tai vaihtoehtoisesti, potentiaalisiksi lopputulemiksi, tässä tapauksessa potentiaalisiksi hoitotuloksiksi. Niitä kutsutaan potentiaalisiksi tai kontrafaktuaalisiksi (faktanvastaisiksi) siksi, että ne sisältävät havaintoja maailmasta, jota ei koskaan tapahdu. Nimittäin potilaat menevät joko LOL-hoitoryhmään tai tavanomaisen hoidon ryhmään, mutta eivät yhtaikaa molempiin. Aineistosta tehtävien päätelmien kannalta, on myös hyvin tärkeää kuinka potilaat näihin ryhmiin menevät. Tulemme seuraavaksi tarkastelemaan havaintoaineiston ja satunnaistetun kokeen eroa, kun havaintoaineistoon vaikuttaa sekoittava tekijä (confounding factor, confounder). Yllä kohtasimme myös dollarimerkille vaihtoehtoisen tavan viitata havaintovektoreihin: with-käsky luo aineistosta ympäristön, jossa muuttujat ovat suoraan viitattavissa käskyn toisen argumentin sisälle [Sama voitaisiin tehdä globaalille ympäristölle käskyllä attach(LOLdata), mutta se on harvoin tarpeen tai suositeltavaa.].
Ajatellaan kahta hoitovalinnat generoivaa prosessia, joista toinen samaistetaan luonnolliseen valikoitumiseen ja toinen kokeelliseen. Oletamme, etteivät huumorintajuttomat henkilöt aineistoaan hyödy muita huonommin LOL-hoidosta, vaan he myös valitsevat LOL-hoidon muita harvemmin (jos saavat itse vaikuttaa). Tällöin luonnollinen hoitovalinta saattaisi muodostua esimerkiksi seuraavasti:
se <- -0.3 # valikoitumisefekti (selection effect)
pA <- 0.5 # LOL-hoidon todennäköisyys ilman "valikoitumaa"
LOLdata$A <- (runif(N) <= pA + se*LOLdata$L)*1 # valikoituneet hoidotSen sijaan, jos kokeen tekijä satunnaistaa potilaat hoitoryhmiin, hoitovalinta saattaisi muodostua seuraavasti:
pA <- 0.5 # LOL-hoidon päätetty todennäköisyys
LOLdata$Aexp <- (runif(N) <= pA)*1 # satunnaistetut hoidot (experimental)
head(LOLdata) # kontrafaktuaalinen aineisto (6 ensimmäistä riviä) id L Y0 Y1 A Aexp
1 1 0 0 0 1 0
2 2 0 0 0 1 0
3 3 1 1 1 1 1
4 4 1 0 0 0 1
5 5 0 0 0 0 0
6 6 1 0 0 0 0Aineistoa generoivaa prosessiamme vastaavat faktuaaliset, kokonaan havaitut, aineistot ovat nyt:
# Havaittu (observed) LOL-data
OLOLdata <- subset(LOLdata, select = -Aexp)
OLOLdata$Y0[OLOLdata$A==1] <- NA
OLOLdata$Y1[OLOLdata$A==0] <- NA
head(OLOLdata) id L Y0 Y1 A
1 1 0 NA 0 1
2 2 0 NA 0 1
3 3 1 NA 1 1
4 4 1 0 NA 0
5 5 0 0 NA 0
6 6 1 0 NA 0# Kokeellinen (experimental) LOL-data
ELOLdata <- subset(LOLdata, select = -A)
ELOLdata$Y0[ELOLdata$Aexp==1] <- NA
ELOLdata$Y1[ELOLdata$Aexp==0] <- NA
head(ELOLdata) id L Y0 Y1 Aexp
1 1 0 0 NA 0
2 2 0 0 NA 0
3 3 1 NA 1 1
4 4 1 NA 0 1
5 5 0 0 NA 0
6 6 1 0 NA 0Riippuen A-muuttujan (tai Aexp-muuttujan) arvosta, vain toinen hoitotulos havaitaan, Y0 tai Y1, toisen ollessa puuttava (not available, NA) arvo. Käytännössä havaittuja aineistoja harvemmin esitetään kontrafaktuaalit puuttuvat arvot mukaan lukien. Saman tiedon sisältävä tyypillisempi esitystapa on:
# Havaittu (observed) LOL-data
OLOLdata$Y <- ifelse(is.na(OLOLdata$Y1), OLOLdata$Y0, OLOLdata$Y1)
OLOLdata <- subset(OLOLdata, select = -c(Y0, Y1))
head(OLOLdata) id L A Y
1 1 0 1 0
2 2 0 1 0
3 3 1 1 1
4 4 1 0 0
5 5 0 0 0
6 6 1 0 0# Kokeellinen (experimental) LOL-data
ELOLdata$Y <- ifelse(is.na(ELOLdata$Y1), ELOLdata$Y0, ELOLdata$Y1)
ELOLdata <- subset(ELOLdata, select = -c(Y0, Y1))
head(ELOLdata) id L Aexp Y
1 1 0 0 0
2 2 0 0 0
3 3 1 1 1
4 4 1 1 0
5 5 0 0 0
6 6 1 0 0Aineistoa generoivien prosessiemme esitykset suunnattuina ei-syklisenä graafina (DAG, directed acyclic graph) ovat:
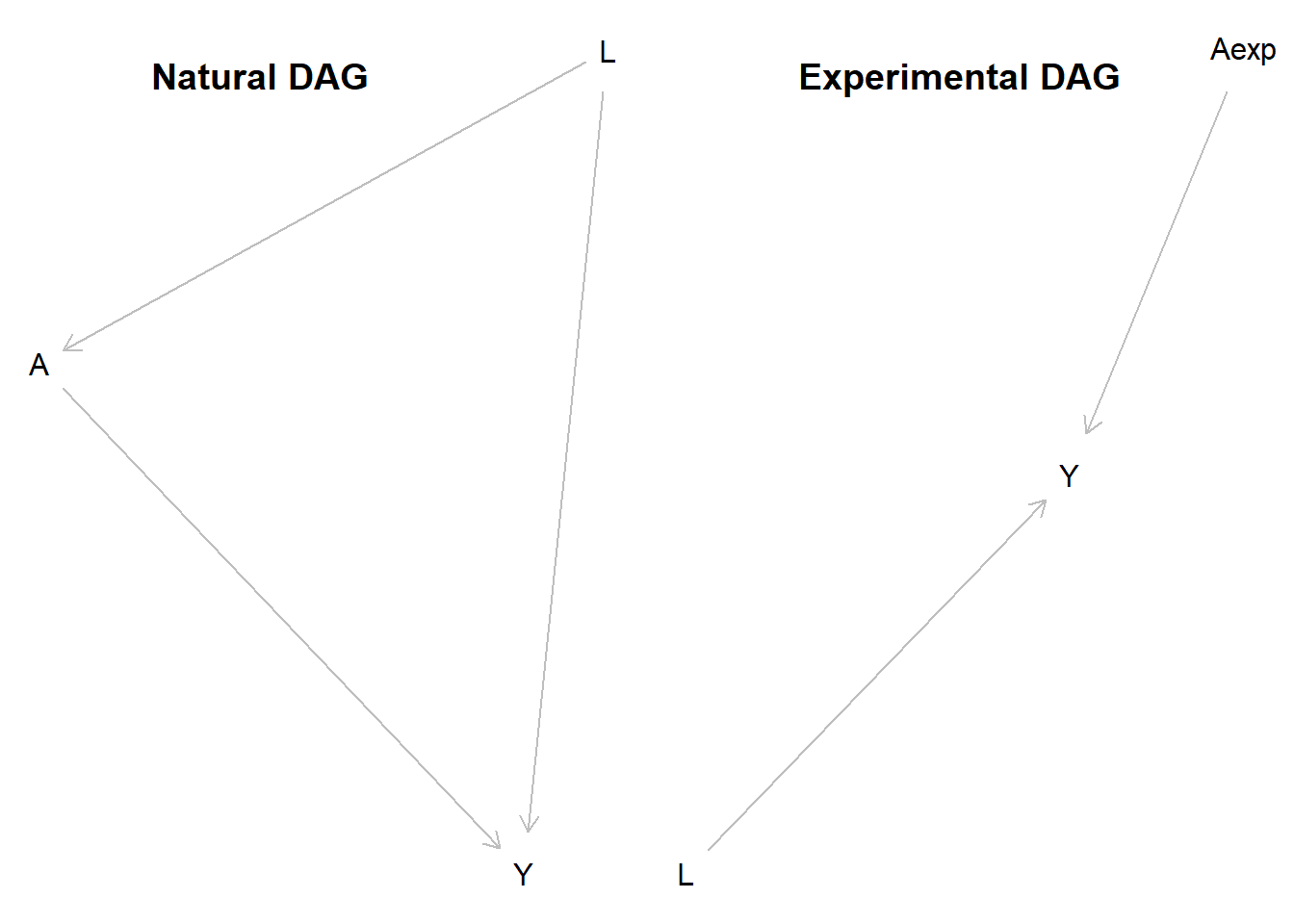
DAG on ns. polkudiagrammin erityistyyppi, joka kuvaa suunnattuja tilastollisia tai syy-seurausriippuvuuksia nuolilla [ja riippumattomuutta nuolen puuttumisella]. Luonnollisissa hoitohavainnoissamme huumorintajuttomuus (L) vaikutti sekä hoitoallokaatioon (A) että hoidon lopputulokseen (Y), kun taas kokeellisissa havainnoissa satunnaistimme hoitoallokaation (Aexp), jolloin mikään muu kuin sattuma ei vaikuta allokaatioon (lukuun ottamatta mahdollista “post-randomization” harhaa). Nyt voimme edelleen arvioida ATE-arvoa laskemalla keskiarvot niistä hoitokohtaisista havainnoista, joita meillä on (ohittaen puuttuvat):
# Havaintoaineistosta laskettu hoitovaikutus:
with(OLOLdata, mean(Y[A==1]) - mean(Y[A==0]))[1] 0.291116# Kokeellisesta aineistosta laskettu hoitovaikutus:
with(ELOLdata, mean(Y[Aexp==1]) - mean(Y[Aexp==0]))[1] 0.1995704Näemme, että hoitovaikutusarvioiden välillä on huomattava ero ja kokeellinen arvio on selvästi lähempänä todellista (kontrafaktuaalia) vaikutusta. Itse asiassa ero kontrafaktuaalin ja kokeellisen arvion välillä johtuu puhtaasti otannasta, kun taas kontrafaktuaalin ja havaintoaineistoarvion välinen ero johtuu osin myös sekoittavan tekijän L vaikutuksesta. Kokeellisen tutkimuksen suosio selittyykin pitkälti sillä, että keinotekoisten koeasetelmien ulkopuolella voimme vain hyvin harvoin sulkea pois mahdollisuuden, että jokin sekoittava tekijä selittää hoidon ja tulosmuuttujan välisen yhteyden osin tai kokonaan. Hoitotutkimuksen lisäksi kokeita tietysti käytetään monenlaisten muidenkin muuttujien syy-seurausyhteyden varmistamiseen. Varsin usein, satunnaistettu koe ei kuitenkaan ole mahdollinen tai eettinen tutkimusstrategia. Seuraavissa osioissa näemme, ettei se myöskään aina ole välttämätön.
Kun tunnemme ja olemme havainneet sekoittavat tekijät, niiden huomioiminen havaintoaineistoa hyödyntäen on mahdollista, tekemättä kokeellista manipulaatiota (jollainen randomisaatiokin on). Nimittäin, yleisesti pätee kokonaisodotusarvon lain nojalla,
\[ E[Y|A=1] = \sum_{l} E[Y|A=1,L=l] P(L=l|A=1). \] Tässä laissa ei ole kyse sen kummemmasta kuin odotusarvon laskemisesta \(L\) muuttujan suhteen, sillä \(E[Y|A=1,L]\) on siitä riippuva satunnaismuuttuja silloin, kun \(L\)-muuttujan taso jätetään kiinnittämättä. Kokeellisen satunnaistuksen tapauksessa \(P(L=l|A=1) = P(L=l)\), koska \(A\) ja \(L\) ovat riippumattomia toisistaan koeasetelman vuoksi (\(A\) riippui vain satunnaistuksesta, ei potilaiden ominaisuudesta \(L\)). Tällöin havaittu odotusarvo \(E[Y|A=1]\) vastaa kontrafaktuaalia populaatio-odotusarvoa \(E[Y^{A=1}] = \sum_{l} E[Y^{A=1}|L=l] P(L=l)\). Jos taas \(P(L=l|A=1) \ne P(L=l)\), odotusarvo on “väärin” painotettu suhteessa koetilanteeseen. Voimme kuitenkin tutkia odotusarvoa painotetulle \(Y\)-muuttujalle ja siten arvioida odotusarvoa \(E[Y^{A=1}]\) riippuvuudesta huolimatta. Esitellään tätä varten funktio \(1_{A=a}\), jolle pätee \(1_{A_i=a}=1\), kun hlö \(i\) kuuluu hoitoryhmään \(a\) ja \(1_{A_i=a}=0\) muulloin. Olkoon nyt painotettu \(Y\)-muuttuja seuraavanlainen:
\[ \frac{Y 1_{A=1} }{P(A=1|L=l)} = 1_{A=1} Y \frac{P(L=l)}{P(L=l|A=1)P(A=1)}, \] missä hyödynsimme Bayes-kaavaa \(P(A=1|L=l) = \frac{P(L=l|A=1)P(A=1)}{P(L=l)}\). Näin painotetun havaitun muuttujan ehdollinen odotusarvo vastaa aina (odotusarvoltaan) kokeellista odotusarvopainotusta
\[ \begin{array}{rl} E[Y 1_{A=1}/P(A=1|L=l)|A=1] &= \sum_{l} E[Y|A=1,L=l] P(L=l|A=1) \times \frac{1_{A=1}P(L=l)}{P(L=l|A=1)P(A=1)} \\ &= \sum_{l} E[Y|A=1,L=l]P(L=l) \times \frac{1_{A=1}}{P(A=1)}, \end{array} \] missä termi \(\frac{1_{A=1}}{P(A=1)}\) skaalaa aktiivisen hoidon havaitusta osapopulaatiosta (kontrafaktuaalisesti) koko populaatioon. Esimerkiksi, jos 1. hoitoryhmään menisi kolmannes potilaista, \(1/3\), ja näillä pyritään edustamaan koko populaatiota, kukin havainto edustaa kolmea potilasta, \(\frac{1}{1/3} = 3\). Siten, odotusarvoisesti \(E[\frac{1_{A=1}}{P(A=1)}] = \frac{E[1_{A=1}]}{P(A=1)} = \frac{P(A=1)}{P(A=1)} = 1\). Jos siis voimme tarkasti laskea hoitoallokaation todennäköisyyden ehdollisena sekoittavalle tekijälle, \(P(A=1|L=l)\), on mahdollista estimoida kokeellinen tulos tekemättä koetta. Esimerkkitapauksessamme tiedämme hoitoallokaation todennäköisyyden ehdolla huumorintajuttomuus, kun sen itse määrittelimme. Voimme siis laskea käänteistodennäköisyyspainokertoimet \(1_{A=1}/P(A=1|L=l)\) ja \(1_{A=0}/P(A=0|L=l) = 1_{A=0}/(1 - P(A=1|L=l))\), sekä kokeellista tulosta vastaavan käänteistodennäköisyyspainotetun estimaatin (inverse-probability of treatment weighted estimator, IPTW estimaatin):
# Ennustettu allokaatiotodennäköisyys
ppA <- pA + se*L # predicted pA
# Havaintoaineistosta laskettu hoitovaikutus:
with(OLOLdata, mean(Y*(A==1)/ppA) - mean(Y*(A==0)/(1 - ppA)))[1] 0.1990723# Kokeellisesta aineistosta laskettu hoitovaikutus:
with(ELOLdata, mean(Y[Aexp==1]) - mean(Y[Aexp==0]))[1] 0.1995704Teorian mukaisesti, näimme kuinka havaintoaineiston painotettu estimaattori vastasi kokeellista estimaattia.
On olemassa toinenkin tapa arvioida kokeellista tulosta, mitä kutsutaan vakioinniksi, adjustoinniksi ja toisinaan myös standardoinniksi. Jälkimmäisellä termillä kuitenkin on muitakin merkityksiä. Yllä totesimme kokonaisodotusarvon laista seuraavaan, että havaintoaineistossa \(E[Y|A=1] = \sum_{l} E[Y|A=1,L=l] P(L=l|A=1)\), kun taas syy-seurauspäättelyä varten meitä enemmän kiinnostaisi asettaa \(A=1\) sekoittavasta tekijästä \(L\) riippumattomasti, jolloin keskimääräinen hoitotulos aktiivisen hoidon ryhmässä olisi \(\sum_{l} E[Y|A=1,L=l] P(L=l)\). Jos voimme laskea edellä esiintyneet summatermit, voimme arvioida koevaikutusta populaatiossa vakioimalla sekoittavan tekijän vaikutuksen (ehdollistamalla sille) ja painottamalla sen tasojen yleisyydellä populaatiossa:
\[ \begin{array}{rl} E[Y^{A=1} - Y^{A=0}] \approx & \sum_{l} E[Y|A=1,L=l] P(L=l) \\ & - \sum_{l} E[Y|A=0,L=l]P(L=l), \end{array} \]
Tehdään tämä simuloimassamme esimerkkiaineistossa ja tarkistetaan vastauksen paikkaansa pitävyys:
# Vakioitu keskiarvo aktiivisen hoidon ryhmässä
mY_A1 <- with(OLOLdata, mean(Y[(A==1)&(L==0)])*mean(L==0) +
mean(Y[(A==1)&(L==1)])*mean(L==1))
# Vakioitu keskiarvo referenssihoidon ryhmässä
mY_A0 <- with(OLOLdata, mean(Y[(A==0)&(L==0)])*mean(L==0) +
mean(Y[(A==0)&(L==1)])*mean(L==1))
# Vakioitu hoitoefekti
mY_A1 - mY_A0[1] 0.199337Näemme, että vakioimallakin saamme saman vastauksen kuin kokeella tai käänteistodennäköisyyspainotuksella. Vakiointi kuitenkin edellyttää hyvää estimaattia odotusarvolle \(E[Y|A,L]\), mikä ei aina ole yhtä helppoa kuin yllä. Kaiken lisäksi, käänteistodennäköisyyspainotuksesta on olemassa ns. tuplarobusteja versioita, jotka sallivat koetuloksen estimoinnin kun ainoastaan toinen arvioista, \(E[Y|A,L]\) tai \(P(A|L)\) saadaan estimoitua oikein. Lisäksi on olemassa koko joukko ei-kokeellisia menetelmiä, joita voidaan käyttää vaikkemme lainkaan havaitsisi sekoittavaa tekijää \(L\), joskin näissä kaikissa on omat oletuksensa ja aineistotarpeensa. Tässä jo kuitenkin näimme, ettei ole mahdotonta korvata koetta havaintoaineistolla, joskin seuraavissa kappaleissa toteamme siihen liittyviä haasteita.
Satunnaistettu koe mahdollistaa syy-seurauspäättelyn silloin, kun aineisto täyttää ns. vaihdettavuus (exhangeability) oletuksen. Vaihdettavuus tarkoittaa seuraavaa: jos vaihtaisimme aktiivista hoitoa saaneet henkilöt referenssihoitoryhmään, he saisivat saman hoitotuloksen kuin alkuperäinenkin referenssihoitoryhmä (ja sama kääntäen). Tekninen tapa ilmaista asia on
\[ Y^a \mathrel{\unicode{x2AEB}} A \text{ for all } a. \]
Tämä tarkoittaa, etteivät kontrafaktuaali lopputulemat riipu siitä mikä hoito satuttiin asettamaan. Kukin potilas siis olisi voinut olla kummassa vain hoitoryhmässä ilman, että kokeen tulos siitä olennaisesti muuttuisi. Satunnaistus yleensä takaa tämän keskiarvomielessä vähintään, koska mikään muu asia kuin sattuma ei vaikuta siihen mihin ryhmään potilaat päätyvät.
Havaintoaineistossa taas on todennäköistä, että jokin lopputulosta ennustava tekijä vaihtelee eri suhteissa eri hoitoryhmissä. Esimerkiksi, huumorintajuttomat etsiytyvät muita harvemmin juuri LOL-terapiaan. Edellä näimme, että pystyimme tästä huolimatta estimoimaan syy-seuraussuhteen, koska ns. ehdollinen vaihdettavuus päti, eli
\[ Y^a \mathrel{\unicode{x2AEB}} A|L \text{ for all } a. \] Edellä myös tiesimme ehdollisen vaihdettavuuden pätevän, koska olimme itse simuloimalla luoneet aineiston. Reaalimaailman aineiston parissa sen sijaan joudumme työskentelemään oletuksen varassa – ei ole olemassa testiä, joka voisi taata ehdollisen vaihdettavuuden havaintoaineistossa. Toisinaan oletus on uskottavampi ja toisinaan vähemmän, mutta sen avulla voidaan saada tietoa edes joistain mahdollisista todellisuuksista, mikä sekin on lisätietoa.
Ehdollisen vaihdettavuuden lisäksi, vakionti ja käänteistodennäköisyyspainotus tarvitsevat toimiakseen kaksi muutakin oletusta. Toinen näistä on positiivisuus (positivity), mikä tarkoittaa, että kaikkien hoitoryhmäallokaatioiden on oltava mahdollisia jokaisella sekoittavan tekijän tasolla. Toisin sanoen, positiivisuus tarkoittaa, että \(P(A = a|L = l) > 0\) kaikilla \(a\) ja kaikilla sellaisilla \(l\), jotka esiintyvät päättelyn kohdepopulaatiossa. Esimerkiksi, jos sairaala ohjaisi kaikki huumorintajuttomat potilaat aina muuhun kuin LOL-terapiaan, positiivisuus-oletus ei täyttyisi. Jos \(P(A = a|L = l) = 0\), ryhmässä \(a\) ei yksinkertaisesti ole ketään edustamaan kaikkia populaation \(l\) tason henkilöitä.
Viimeinen tarvittava oletus on yhdenmukaisuus (consistency; HUOM! eri asia kuin “tarkentuvuus”, mikä myös on englanniksi consistency). Yhdenmukaisuus tarkoittaa, että havaitun hoitotuloksen hoidolle \(a\) on vastattava kontrafaktuaalia hoitotulosta samalle hoidolle. Eli, että \(Y^a = Y\) jokaiselle henkilölle, joka sai hoidon \(A = a\). Tämä tuntuu ilmeiseltä, muttei ole itsestään selvää. Kuvitellaan esimerkiksi, että yksi terapeutti antaa syvään vatsanauruun perustuvaa LOL-hoitoa, joka on tehokasta, kun taas toinen antaa tehotonta kurkunpääkikatusta. Kummassakin tapauksessa, potilaillle 1 ja 2, tutkija merkitsee \(A_1 = 1\) ja \(A_2 = 1\), mutta kontrafaktuaalit vaikutukset \(Y_1^{A=1}\) ja \(Y_2^{A=1}\) eivät ole verrannollisia tapahtumia. Vastaavasti kolmas potilas saattaisi päätyä referenssihoitoon, mutta tutkimuksen ulkopuolella käydä omilla rahoillaan kehutussa LOL-hoidossa, jolloin tutkijan kirjoissa olisi \(A_3 = 0\), vaikka todellisuudessa \(Y_3 = Y_3^{A=1}\), mikä myöskin rikkoisi yhdenmukaisuus-oletusta. Jälkimmäinen tilanne on itse asiassa esimerkki ns. satunnaistuksen jälkeisestä harhasta (post-randomization bias), jonka vaikutuksia edes koeasetelma ei aina riitä kontrolloimaan. Näemmekin, ettei mikään syy-seurauspäättelyn menetelmä ole “pomminvarma”, vaan tutkijan on oltava alati valppaana.
Ensimmäisellä luennolla osoittautui, että moni on jo tutustunut R-ohjelmaan, muttei toisaalta muistanut kuulleensa keskeisestä raja-arvolauseesta. Tässä lisäosassa havainnollistetaan raja-arvolauseita R:n avulla ja paikataan siten teoreettisia tietopuutteita näiltä osin. Lisäksi Howellin kirjan kappaleesta 7 voi katsoa lisätietoa raja-arvolauseista. Olennainen teoreettinen tulos on:
Keskeinen raja-arvolause. Olkoon \(X_1, X_2, \ldots, X_n\) jono riippumattomia satunnaismuuttujia (otos; \(n\) kappaletta), joiden odotusarvo on \(\mu\) ja varianssi \(\sigma^2\), ja \(\bar{X}_n\) näiden keskiarvo. Silloin satunnaismuuttujan \(\sqrt{n}(\bar{X}_n - \mu)\) jakauma lähestyy otoskoon \(n\) kasvaessa jakaumaa \(N(0, \sigma^2)\), eli normaalijakaumaa, jonka varianssi on \(\sigma^2\).
Tämä tarkoittaa myös, että riittävän suurella \(n\), \(\sqrt{n}(\bar{X}_n - \mu)/\sigma^2 \sim N(0, 1)\), riippumatta siitä kuinka alkuperäiset havainnot ovat jakautuneet. Kun todellista arvoa \(\mu\) ei tiedetä vaan oletetaan nollahypoteesin mukaiseksi \(\mu_0\), standardinormaalijakaumaa \(N(0, 1)\) voidaan käyttää testaamaan kuinka uskottavaa olisi havaita tietyn suuruinen keskiarvo \(\bar{x}\). Konkretisoidaan asiaa R-simulaatiolla. Välin \([0,1]\) tasajakautuneen satunnaismuuttujan \(X_1\) keskiarvo on \(0.5\) ja varianssi on \(\frac{1}{12}\). Kun siitä miinustaa keskiarvon ja jakaa varianssin neliöjuurella, eli keskihajonnalla, saadun uuden muuttujan \(Z_1 = (X_1 - 0.5) \cdot \sqrt{12}\) keskiarvo on \(0\) ja varianssi \(1\), eli muuttuja on standardoitu. Sen jakauma on silti edelleen tasajakauma. Usean, eli \(n\):n, tällaisen riippumattoman muuttujan keskiarvo on myös \(0.5\) ja varianssi on \(\frac{1}{n \cdot 12}\), ja standardoidun keskiarvon \(Z_n = (\bar{X}_n - 0.5) \cdot \sqrt{n \cdot 12}\) keskiarvo on edelleen \(0\) ja varianssi \(1\), mutta jakauma ei enää ole tasainen. Se lähestyy standardinormaalijakaumaa keskeisen raja-arvolauseen nojalla. Tarkastelleen tilannetta R:n avulla:
# Luodaan matriisi riippumattomia tasajakautuneita arvoja siten, että
# rivit ovat otoksia ja sarakkeita (kohta) ajatellaan otoksen kokona
set.seed(12012026)
X <- matrix(runif(10000*100),10000,100)
# Tarkastellaan yhden havainnon otoksen "otantajakaumaa" 10 tuhannella toistolla
Z_1 <- (X[,1] - 0.5) * sqrt(12)
# Ja kahden, kolmen ja sadan havainnon keskiarvojen otantajakaumaa samoin
Z_2 <- (rowMeans(X[,1:2]) - 0.5) * sqrt(2*12)
Z_3 <- (rowMeans(X[,1:3]) - 0.5) * sqrt(3*12)
Z_100 <- (rowMeans(X[,1:100]) - 0.5) * sqrt(100*12)
# Piirretään histogrammit ja päälle standardinormaalijakauman tiheysfunktio
z <- seq(-4,4,length.out=100)
par(mfrow=c(2,2))
hist(Z_1, breaks = 30, freq = F, ylim = c(0,0.4)); lines(z, dnorm(z), lwd=2)
hist(Z_2, breaks = 30, freq = F, ylim = c(0,0.4)); lines(z, dnorm(z), lwd=2)
hist(Z_3, breaks = 30, freq = F, ylim = c(0,0.4)); lines(z, dnorm(z), lwd=2)
hist(Z_100, breaks = 30, freq = F, , ylim = c(0,0.4)); lines(z, dnorm(z), lwd=2)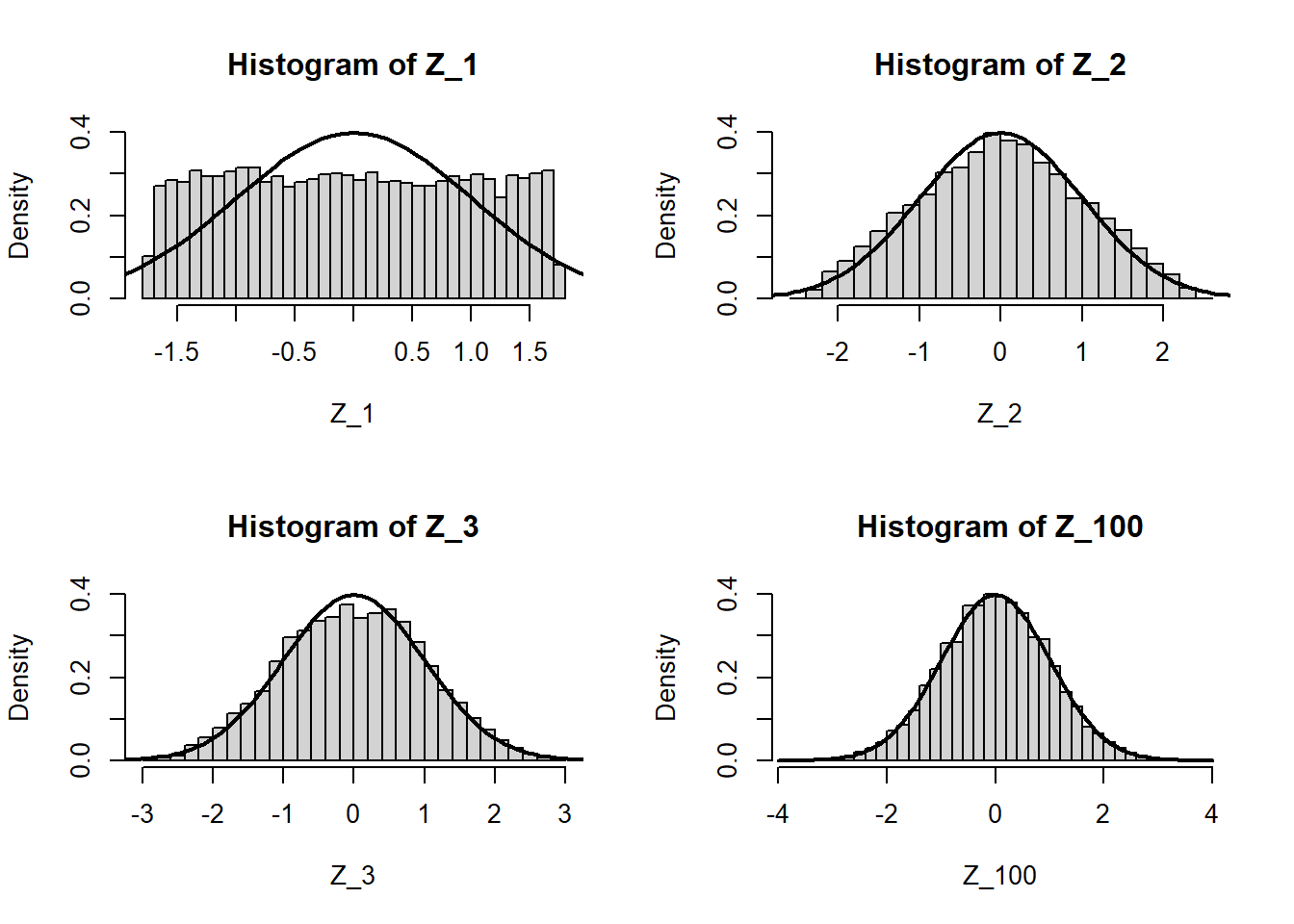
Havaitsemme kuinka suureen \(\sqrt{n}(\bar{X}_n - \mu)/\sigma\) jakauma hyvin nopeasti lähestyy standardinormaalijakaumaa. Suuremmilla otoskoilla todellinen varianssi voidaan sekin korvata aineistoestimaatilla, jolloin \(\sqrt{n}(\bar{X}_n - \mu)/\hat{\sigma} \approx \sqrt{n}(\bar{X}_n - \mu)/\sigma\).
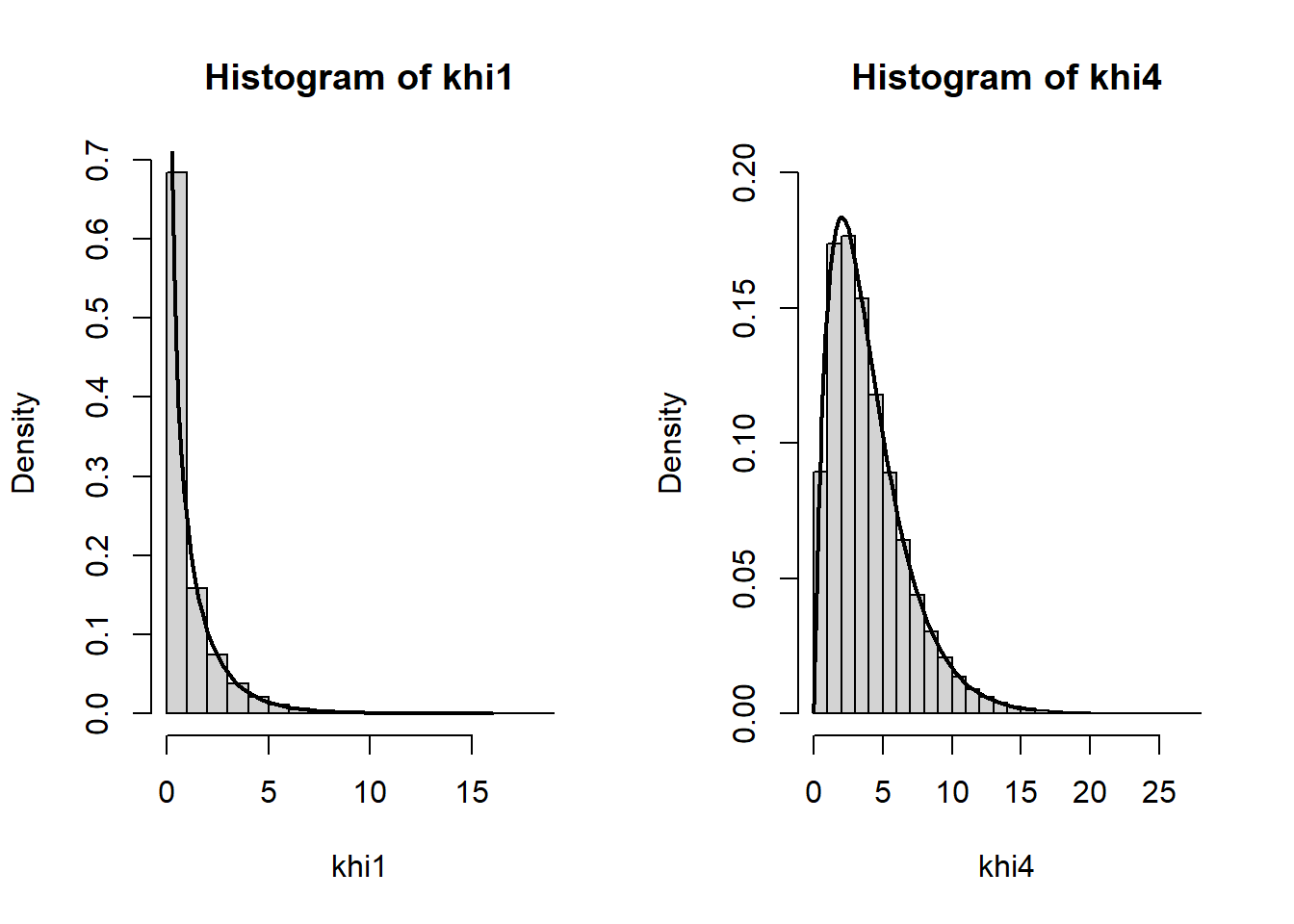
Vastaavasti voit R:n avulla todentaa, että \(\sum_i^n Z_i^2 \sim \chi^2(n)\), kun \(Z_i \sim N(0,1)\) ja, että \(\frac{\chi^2(n_1)/n_1}{\chi^2(n_2)/n_2} \sim F(n_1, n_2)\), eli, että standardinormaalijakautuneiden muuttujien neliösummat ovat khi-toiseen jakautuneita ja khi-toiseen jakautuneiden muuttujien vapausastekorjatut osamäärät ovat F-jakautuneita. Näitä tilastollisen testaamisen kannalta tärkeitä tietoja päästään usein hyödyntämään juuri keskeisen raja-arvolauseen kautta, koska se antaa takeita summittaisesta normaalijakautuneisuudesta. Tarkistetaan khi-toiseen jakauman tulos itse nopeasti ja palataan vastaaviin F-jakaumaa koskeviin simulaatiotarkasteluihin ensi viikolla:
# simuloidaan normaalijakaumasta ja tutkitaan neliösummien jakaumia:
n <- 10^5
khi1 <- rnorm(n)^2
khi4 <- rnorm(n)^2+rnorm(n)^2+rnorm(n)^2+rnorm(n)^2
par(mfrow=c(1,2))
hist(khi1, freq=F)
lines(z^2, dchisq(z^2, df=1), lwd=2)
hist(khi4, freq=F, ylim=c(0,0.2), breaks=30)
lines(z^2, dchisq(z^2, df=4), lwd=2)