Lue ensin Howellin faktoriaalista ANOVAa käsittelevä kappale Moodlen määrittelemin osin. Sen jälkeen voit edetä tätä verkkotekstiäkin aina toistomittaus-varianssianalyysia käsittelevään kohtaan. Sitä ennen kannattaa katsoa Howellin asiaan liittyvää kappaletta, jälleen Moodlen määrittelemin osin (halutessasi toki enemmänkin). Tämän tekstin viimeistä visualisointia koskevaa osaa ennen on hyödyllistä katsoa R-videoluento.
4.1 Miksi kaavoja?
Jos vastaus otsikon kysymykseen on sinulle selvä, voit hyvin siirtyä suoraan seuraavaan osioon. Jollei, lue toki tämäkin lyhyt osio. Nimittäin, opiskelijat usein kysyvät tarvitseeko kaavoja osata tai jopa kritisoivat asioiden käsittelyä “kaavojen kautta”. Toive sisältöjen väistelystä on inhimillinen ja ymmärrettävä laajoja ja vieraita asiakokonaisuuksia kohdatessa, muiden kiireiden keskellä. Koska vastaus kysymykseen on monitahoinen, tarkastellaan sitä tovi.
Tätä asiaa voisi jäsentää siten, että on kahdenlaista kaavoja koskevaa ymmärrystä. Kuvailevaa ja selittävää. Kuvailu ei tässä tarkoita ulkoa muistamista. Se tarkoittaa esimerkiksi sitä, että tiivistämme kaavaan tai yhtälöön sen, miten ja millaisia symbolisia edustuksia tilastollinen malli yhdistää. Eli sen, miten se operationalisoi psykologisen ymmärryksemme. Kaikki kaavat voi myös kirjoittaa auki sanallisessa muodossa, mutta yhtään epä-triviaaleissa tapauksissa, kuvauksista tulee naurettavan pitkiä ja huonosti ihmisen työmuistia tukevia. Symbolisen edustuksen (kaavan) tehtävä on helpottaa sisällön pitämistä työmuistissa ja konkretisoida sitä tosiasiaa, että sisältö on symbolista – sen paikalle voidaan sijoittaa lukuisia asioita, muttei tyhjentävästi korvata millään niistä (tästä lisää alla). Erilaiset “for dummies” -esitykset usein toki kursailematta korvaavat abstraktion konkretialla ja siten menestyksekkäästi rahastavat ihmisten luontaisella halulla välttää symbolifunktion käytön edellyttämää kognitiivista lihasjumppaa. Nekin esitykset voivat olla hyödyllisiä, jos ne esimerkit auttavat kohden symbolifunktion ymmärrystä, mutta myös haitallista petosta, kun näin ei käy.
Selittävät kaavat yhdistävät käsitteitä toisiinsa, luoden niihin ymmärrystä, tai todistaen yhden käsitteen toisilla. Matemaattinen todistaminen on juuri tätä. Meillä on tietyt yhteisesti hyväksytyt totuudet, joita usein aksioomiksikin kutsutaan. Kun kohtaamme uuden väitteen, jonka totuusarvo on meille epäselvä, voimme nähdä totuusarvon luomalla yhteyden aiempiin hyväksyttyihin tosiasioihin, eli dedusoimalla väitteen aksioomista tai muusta paremmin tunnetusta tiedosta käsin. Tällä kurssilla edellytetään melko vähän selittävää kaavojen käyttöä, jos nyt ei täysin vältelläkään, eikä ero kuvailevaan ylipäätään ole tarkkarajainen. Sen sijaan on turha kuvitella ymmärtäneensä kurssisisältöä, jos ohittaa kaikki kuvailevatkin kaavat, eli symboliedustuksen periaatteen. Usein ne voi kuitenkin osin ohittaa ja varsinkin ensimmäisellä lukukerralla, koska symboliedustukset luonteeltaan muodostuvat hitaammin kuin yksinkertaiset assosiaatiot. Eivät ammattilaisetkaan lue kirjallisuutta jumiutuen yhteen hankalaan kohtaan, vaan ensin usein katsotaan kokonaiskuvaa. Joskus kuitenkin on tarpeen palata asiaan ja puskea läpi se yksikin kohta suurimman huolellisuuden periaatteella.
Havainnollistetaan vielä lyhyesti symbolifunktiota ja siihen liittyviä tiedon tasoja. Voi ymmärtää tai tietää, että \(2 \times 2 = 4\), mutta se ei ole sama asia kuin ymmärtää, että on olemassa reaalilukujen kenttä, jonka äärettömän monelle alkiolle \(a\) ja \(b\) voidaan suorittaa tulo-operaatio \(ab\) ja, että sen tulo-operaatio voidaan yleistää muillekin joukoille, joskus osia operaation ominaisuuksista uhraten (esimerkiksi symmetria-ominaisuus \(ab = ba\) on uhrattava matriisitulossa). Voi ymmärtää esimerkin siitä kuinka tutkijat sovelsivat tilastollista monitasomallia aineistoon, jossa on kahden tasoisia havaintoja, koulun luokkia ja luokissa oppilaita. Mutta, se ei ole monitasomallin selitys tai edes kuvaus, vaan sovellus. Monitasomalli on abstrakti ja aineeton olio. Sen voi ymmärtää vain ymmärtämällä kuinka se yhdistää symbolisia edustuksia – eli kaavoin. Vasta silloin mallia voi soveltaa aidosti uusiin tilanteisiin, ja se on tavoitteemme. Teknologia tekee yhä helpommaksi aiemman esimerkin kopioimisen, jolloin todellinen inhimillinen arvo usein luodaan symbolifunktion ymmärryksellä. Myös tieteelliset edistysaskeleet tyypillisesti edustavat uusien yhteyksien havaitsemista, vaikkei replikointikaan toki hyödytöntä ole. Kyky korvata klinikoiden vanhentuneita tiedolla johtamisen ja testaamisen käytäntöjä niin ikään edellyttää sovelluskykyä ja kykyä nähdä mahdollinen, ei vain referoida jo tehtyä.
4.2 Esimerkkiaineiston tuominen
Kappaleessa 13 Howell tuo käyttöön laajennetun Eysenckin (pseudo)aineiston. Kopioimme hänen aineistonsa myös tässä käytettäväksi. Aineiston voisi OSAn 2 opein itsekin R:n näpytellä, mutta olen äskettäin vienyt sen GitHub-palvelimelta löytyvään psyktools-R-pakettiin. Paketti on siis päivittynyt kurssin alun jälkeen, joten saat aineiston laitteellesi ajamalla alkusanat-osasta löytyvän installointi-käskyn uudestaan. Huomaa, että nyt pakettimme ei ole R:n virallisella CRAN-kokoelmalla (Comprehensive R Archive Network), joten install.packages käsky ei osaa hakea sitä automaattisesti verkon ylitse. Alun ohjeiden käskyt ja devtools-paketti kuitenkin osaavat. Vaihtoehtoisesti olisi mahdollista tallentaa paketti omalle koneelle ja sitten käyttää install.packages-käskyä, tai yksinkertaisesti poimia haluttu eysenck_2way-aineisto psyktools-paketin verkkorepon data-sivulta. Enemmän R-ohjelmaa käytettäessä, melko piankin saattaa törmätä työkaluihin, joita ei löydy CRAN-verkosta. Hyvin usein ne tällöin ovat juurikin avoimen-lähdekoodin ohjelmoijien suosiossa olevalla GitHub-verkkoalustalla, mutta muitakin toki on olemassa. Kun olet asentanut paketin, halutun paketin sisältämän aineiston voi tuoda tarkasteluun pakettia lataamattakin, esimerkiksi näin:
Nyt muistikoekonditiota kuvaava “lab”-muuttuja (label) sekä ikä-muuttuja (age) ovat jo valmiiksi luokkaa, eli tyyppiä, factor. R tallentaa faktorimuuttujat kokonaislukuina sekä kokonaisluvun parituksena character-tyyppiseen luokkanimeen, eli faktorimuuttujan “tasoihin” (levels). Eri käskyt kuitenkin tunnistavat, että muuttujan luokka on tyyppiä factor ja siten osaavat tulostaa ja tulkita kokonaislukuarvot nominaalisiksi muuttujatasoiksi. Esimerkiksi regressiomalli-käsky lm automaattisesti tekee \(k - 1\) kappaletta 0 ja 1 arvoja saavia dummy-muuttujia, kun faktorimuuttujassa on \(k\) erillistä tasoa. Alla hyödynnämme tätä ominaisuutta, kuten olemme aiemminkin tehneet (joskin toisinaan muuttaen muuttujan faktoriksi vasta osana formula-notaatiota).
4.3 Faktoriaalinen asetelma
Sekä Howellin kirjassa, että aiemmalla kurssilla, totesimme t-testin ja regressiomallin kulmakertoimen olevan sama asia, mutta se pätee vain tietyssä tilanteessa. Asia jäi monimutkaisuutensa vuoksi yhtälöin osoittamatta, mutta voimme tarkistaa sen nyt R:llä. Samalla hahmotamme mallia t-testin taustalla ja laajennamme sitä koeasetelmien ulkopuolisiinkin syy-seurauskysymyksiin. Suoritetaan regressioanalyysi ja t-testi tarkoitusta varten luomassamme väliaikaisessa dtmp aineistossa, johon on valittu loogisella indeksillä vain adjektiivi ja tarkoituksellinen harjoittelu -ryhmissä olleita koehenkilöitä. Balansoidun koeasetelman vuoksi, eysenck_2way-aineistossa on yhtä paljon nuoria ja vanhoja, ja tämä ominaisuus siirtyy myös valikoimallemme alaotokselle:
old
young
Adjective
10
10
Counting
0
0
Imagery
0
0
Intentional
10
10
Rhyming
0
0
Suoritetaan siis yllä kuvatun aineiston valinta ja t- ja regressio-testit:
lind <- eysenck_2way$lab %in%c("Adjective", "Intentional") # looginen indeksidtmp <- eysenck_2way[lind, ] # valitaan indeksin TRUE-arvojen rivitfit <-lm(obs ~ lab, data = dtmp) # sovitetaan malli (HUOM: lab on jo faktori)summary(fit)$coefficients # Kulmakertoimet ja niiden t- ja p-arvot
Estimate Std. Error t value Pr(>|t|)
(Intercept) 12.90 0.9558339 13.496069 4.493268e-16
labIntentional 2.75 1.3517532 2.034395 4.893416e-02
# Kulmakerroin vastaa ryhmäkeskiarvojen eroa ja sen p-arvo t-testiäa <-t.test(dtmp$obs[dtmp$lab =="Intentional"], dtmp$obs[dtmp$lab =="Adjective"])c(ryhmaero =-diff(a$estimate), t_arvo = a$statistic, p_arvo = a$p.value)
ryhmaero.mean of y t_arvo.t p_arvo
2.75000000 2.03439496 0.04964034
Tässä siis regressiomallin kulmakerroin olennaisesti testasi ryhmäeroa. Lisätään nyt malliin ikä.
fit <-lm(obs ~ lab + age, data = dtmp) # sovitetaan mallisummary(fit)$coefficients # Kulmakertoimet ja niiden t- ja p-arvot
Näemme, että absoluuttisen ryhmäeron arvio on pysynyt samana, eli kulmakerroin-estimaatti “labIntentional”-dummumuuttujalle on sama kuin aiemmin, mutta sen t- ja p-arvot eivät. Tilastollisen varmuuden mielessä, tulos vaikuttaa jopa aiempaa vahvemmalta. Tutkitaan tilannetta vähän Howellin notaation valossa, jos se helpottaisi (käytetään tutumpaa \(Y\)-symbolia riippuvalle muuttujalle \(X\):n sijaan kuitenkin):
Yllä siis ensimmäinen tilanne ja t-testi, vastasi suureen \(\mu_{A_2} - \mu_{A_1}\) estimointia keskiarvoilla ja testiä, joka vertaa estimaattia termeistä \(\beta_i + (\alpha \beta)_{ij} + \epsilon_{ijk}\) syntyvään “virhevaihtelun” estimaattiin. Vaikka tietäisimmekin, ettei kaikki tämä vaihtelu ole “virhettä”, t-testi (tai muu yksinkertainen ryhmävertailu) kohtelee ko. vaihtelua “virheenä”, eli suhteuttaa testattavan ryhmäeron kokoluokkaa kaikkeen muuhun vaihteluun vastemuuttujassa (sekä tietysti otoskokoon). Yllä olevat kaavat siis kuvaavat piilevää teoreettista rakennemallia, eli aineistoa (oletetusti) synnyttyvää tilastollista mallia.1
Tällaisessa balansoidussa asetelmassa ikä ei liity sekä vastemuuttujaan että koeryhmään päätymisen todennäköisyyksiin (ikä ei ole sekoittava tekijä), jolloin sen kontrollointi ei vaikuta ryhmäeron \(\mu_{A_2} - \mu_{A_1}\) estimaatin absoluuttiseen kokoon (mikä ylläkin siis nähtiin). Sen sijaan, se vaikuttaa virhekeskiarvoon (\(MS_{error}\)), mikä kontrolloinnin jälkeen heijastelee enää termeistä \((\alpha \beta)_{ij} + \epsilon_{ijk}\) syntyvää vaihtelua. Luomamme jälkimmäinen regressiomalli on siis suorittanut OSAssa 1 nähdyn vakioinnin, joskaan ei täydellisesti. Malli on kuitenkin “imenyt” osan aiemmin selittämättä jääneestä residuaalista muun tulkinnan piiriin. Erityisesti, mallimme on huomioinut iän mahdollisen vaikutuksen suoriutumiseen, muttei mahdolliseen erilaiseen suoriutumiseen eri konditioissa. Siksi termi \((\alpha \beta)_{ij}\) edelleen esiintyy residuaalissa. Muutakin puuttuu suhteessa OSAn 1 syy-seurauspäättelyyn, mutta palataan siihen asiaan vasta, kun olemme lisänneet interaktiotermin ja tyhjentäneet residuaalin mallinnettavissa olevasta vaihtelusta. R:n formula-notaatiossa interaktiotermin symboli on lab:age, kun aineiston vuorovaikuttaja-kandidaattimuuttujien nimet ovat lab ja age:
fit <-lm(obs ~ lab + age + lab:age, data = dtmp) # sovitetaan mallisummary(fit)$coefficients # Kulmakertoimet ja niiden t- ja p-arvot
OHO! Vaikka poistimme residuaalivaihtelua, menetimmekin tarkoituksellisen (Intentional) mieleenpainamisen tilastollisesti merkitsevän2 eron adjektiivi-konditiosta, joka tässä oli referenssinä.
Tämä johtuu siitä, että koekonditioiden keskiero on paljon suurempi nuorilla kuin vanhoilla: todellinen merkitsevä ilmiö onkin aiemmin mallintamatta jäänyt ikä-interaktio, eikä aiemmin mallinnettu päävaikutus. Mallin avulla, on kuitenkin mahdollista yhtaikaa sekä tutkia interaktio-asiaa että toteuttaa aiempi päävaikutuksen testi siten, että residuaaliin jää vain \(\epsilon_{ijk}\). Jos nimittäin koekonditio olisi jokin hoitointervention, voisimme hyvinkin olla kiinnostuneita sen kokonaisvaikutuksesta, tuli se sitten suoraan tai muun kanssa vuorovaikutuksessa.
Regressiomallissa vakio (Intercept, \(\beta_0\)) mallintaa referenssiryhmän (Adjective-konditio) keskiarvoa (tai yleisemmin, \(Y\)-leikkausta). Ensimmäinen dummy-muuttuja taas mallintaa ko. ryhmän eroa referenssistä (\(\beta_1\), tässä “labIntentional”, eli “lab” muuttujan ryhmään “Intentional” kuuluminen vs. kuulumattomuus), toisen dummy-muuttujan mallintaessa nuorten eroa vanhoista (\(\beta_2\), “ageyoung”). Interaktiotermin kulmakerroin \(\beta_3\), jota alla merkitään “labIntentional:ageyoung”, mallintaa sellaista ko. kondition ryhmäkeskiarvon eroa nuorilla vs. vanhoilla, jota ei referenssikonditiossa nähdä. Koska vanhoja on tasan puolet koehenkilöistä ja nuoria puolet,
kun taas \(\mu_{\text{Adjective}} = \beta_0\), ja siten aiempi yleinen ryhmäero \(\mu_{A_2} - \mu_{A_1}\) vastaa siis tässä mallissa lineaarista termiä \(\beta_1 + \beta_2/2\) ja testi sen nolla-arvolle vastaa yleistä lineaarista hypoteesia:
\[
H_0: \beta_1 + \beta_2/2 = 0.
\]
Tarkistetaan arvot R:ssä ja katsotaan kuinka ikä-interaktio imaistaan residuaalista ja jätetään yleiseen ryhmäeroon:
# koska nuoria ja vanhoja yhtä paljon, ryhmävertailua vastaava keskiefekti on:coef(fit)["labIntentional"] +coef(fit)["labIntentional:ageyoung"]/2
labIntentional
2.75
# tilastollinen ero on taas aavistuksen vahvempi "pienemmän" residuaalin myötä:gmodels::glh.test(fit, cm =matrix(c(0,1,0,1/2), nrow =1))
Test of General Linear Hypothesis
Call:
gmodels::glh.test(reg = fit, cm = matrix(c(0, 1, 0, 1/2), nrow = 1))
F = 7.6539, df1 = 1, df2 = 36, p-value = 0.008885
Yllä näimme kuinka iän vaikutus käsittelyyn (koekonditioon) täysin vakioidaan regressiomallissa, mutta tämä ei ole vielä sama asia kuin OSAn 1 keskimääräisen käsittelyvaikutuksen vakiointi.3 Nimittäin, regressiomalli ei ole populaatiokeskivaikutuksen malli, vaan ehdollisen keskivaikutuksen. Jos merkitään ikää \(X\):llä ja koeryhmä-altistusta \(A\):lla, regressioennuste (ilman residuaalitermiä) tässä mallintaa seuraavaa muistitulosten ehdollista odotusarvoa yhtälön oikean puolen kuvaamalla tavalla:
\[
E[Y|A=a, X=x] = \beta_0 + \beta_1 a + \beta_2 x + \beta_3 xa.
\]
Yllä otimme erotuksen termeistä \(A\):n suhteen ja keskiarvon \(X\):n suhteen, olettaen 50-50-jaon nuorille ja vanhoille. Koska oletus pätee balansoidussa aineistossa, laskutoimitus on sama kuin, jos olisimme tehneet regressioennusteet \(\beta_0 + \beta_1 a_i + \beta_2 x_i + \beta_3 x_i a_i\) jokaiselle Intentional-ryhmäläiselle \(i\) ja verranneet niiden keskiarvoa Adjective-ryhmäläisten vastaavaan (R:ssä predict-käsky antaa mallin ennusteen):
Tarkastellaan sitten balansoimatonta, “luonnollisempaa”, aineistoa. Tehdään hetkeksi uusi pseudoaineisto, jossa nuoria onkin kaksi kertaa enemmän. Havainnollistuksen vuoksi yksinkertaisesti teen kopion jokaisesta nuoresta ja lisään aiempaan dataan:
dtmp2 <-rbind(dtmp, dtmp[dtmp$age=="young", ]) # uusi pseudoaineistofit2 <-lm(obs ~ lab + age + lab:age, data = dtmp2) # sovitetaan malli uudestaansummary(fit2)$coefficients # Todetaan, etteivät kulmakertoimet muuttuneet
# ja vastaavan ryhmäeroa "luonnollisessa" pseudoaineistossamean(dtmp2$obs[dtmp2$lab=="Intentional"]) -mean(dtmp2$obs[dtmp2$lab=="Adjective"])
[1] 3.333333
Jokseenkin triviaalisti, yllä nähdyt erot johtuvat siitä, että nuoria oli nyt kaksinkertaisesti vanhoihin nähden, jolloin heidän merkityksensä suhteellisia osuuksia arviovalle keskiarvolle on suurempi. Toisaalta näemme, että kulmakertoimet eivät muuttuneet ja voisimme edelleen viedä 50-50-ikäjaon oletukselle perustuneen analyysimme läpi tismalleen identtisenä. Tämän kirjan OSAssa 1 keskustelimme, että kovariaattien tasainen jakautuminen koeryhmiin on olennaista syy-seurauspäättelylle. Onkin huomionarvoista, että tässä kykenimme ensin mallintamaan aineistoa ja sitten mallin avulla asettamaan\(X\)-muuttujan jakauman tasaisesti koeryhmiin. Kun teimme laskun balansoituun aineistoon sovitetun mallin kulmakertoimille, lasku perustui havaituille ikäryhmäosuuksille ja oli siis faktanmukainen. Sama lasku jälkimmäiseen muokattuun aineistoon sovellettuna olisi kontrafaktuaalinen siinä mielessä, ettei \(X\)-arvot nyt todellisuudessa jakautuneet tasaisesti koeryhmiin – ainoastaan laskussamme. Sikäli kuin malli on totuudenmukainen, sillä voi siis tutkia mitä kävisi, jos kovariaattijakauma olisi tasainen ja siis satunnaistetun kokeen mukainen. Tai muun relevantin populaatiojakauman \(P(X)\) mukainen. Voimme siis siirtyä malliperusteisesti sekoittumista edustavista keskiestimaateista \(E[Y|A=a] = \sum_x E[Y|A=a, X = x]P(X=x|A=a)\) sekoittumattomiin keskiestimaatteihin \(E[Y|A=a] = \sum_x E[Y|A=a, X = x]P(X=x)\) ja tässä erityisesti estimaatteihin \(E[Y|A=a] = \sum_x E[Y|A=a, X = x]/2\). Tutkitun efektin yleiseen jakaumaan vakiointi (vrt. Section 1.5) tapahtuisi seuraavasti, kontrafaktuaaleja ennusteita hyödyntäen:
Näemme, ettei \(X\):n jakauma suoraan vaikuta regressioennusteeseen \(E[Y|X=x, A=a]\), mutta se vaikuttaa keskimääräisen käsittelyefektin (average treatment effect, ATE) ennusteeseen \(E_X[E[Y|X=x, A=a]]\), t-testeihin, ym. ryhmävertailuihin. Nimenomaan jälkimmäinen estimaatti voidaan syy-seurauspäättelyn keinoin ja oletuksin muokata vastaamaan kontrafaktuaaliin kysymykseen: mitä jos kaikki yksiköt \(X\) olisivat olleet käsittelyssä \(A = 1\) (Intentional) vs. \(A = 0\) (Adjective). Se vastaa ensimmäistä estimaattia yleisesti vain silloin, kun eri tyyppisiä yksiköitä \(x\) on tasan yhtä paljon koeryhmissä. Toki, jos satunnaistamme henkilöt koeryhmiin, eri tyyppisten henkilöiden osuudet keskimäärin asettuvat samanlaisiksi yli ryhmien, mutta yllä siis simuloitiin syy-seurauspäättelyä, kun aineisto ei ole näin (eli satunnaistamalla) muodostunut.
Jos vierastaa syy-seurauspäättelyä havaintoaineistoista, asiaa voi myös ajatella varianssianalyysin ymmärtämisenä mallina ennemmin kuin “metodina” tai yksittäisinä “testeinä”. Metodit, testit, ja ennen kaikkea laskut, olivat tärkeitä siinä historiassa, josta Howellin kirjakin ponnistaa. Tästä historiasta ponnistaa myös mahdollisesti hämmentävät lausunnot, kuten “There has been a great deal written about the treatment of unequal sample sizes, and we won’t see any true resolution of this issue for a long time. (That is in part because there is no single answer to the complex questions that arise.) However, there are some approaches that seem more reasonable than others for the general case. Unfortunately, the most reasonable and the most common approach is available only using standard computer packages, and a discussion of that will have to wait until Chapter 15.” (Howell, ed. 7). Juurikin siitä syystä, että asioiden ymmärtäminen yksittäisten laskujen kautta on vanhanaikaista ja tehotonta modernissa maailmassa, olemme pyrkineet hyödyntämään regressiomallia läpi kurssin, kun taas Howell esittelee sen vasta lopuksi. Jos tekisimme näin, se viestittäisi asian toissijaisuutta tai haastavuutta, kun mieluummin näemme sen ensisijaisena ja lopulta helpompana tapana.
Yllä näimme esimerkin kuinka tilastollinen malli irroittaa sisällön teknisistä yksityiskohdista, kuten yhtä suuret koeryhmät, ja sitten haluttaessa palauttaa sen niihin. Kun astumme yhtään monimutkaisempien tilanteiden pariin, kuten nykytutkimuksessa on välttämätöntä, on tämä abstraktien mallien taso myöskin välttämätön tai ainakin hyvin hyödyllinen. On myös huomionarvoista, että tämä osio käsitteli yksinomaan “faktoriaalista varianssianalyysia”, kuitenkaan juuri käsitettä mainitsematta. Näin voi tehdä, koska käsite on toissijainen. Näin myös tutkimuskirjallisuudessa usein tehdään. Kommunikaation kannalta on olennaista puhua muuttujien vuorovaikutuksesta ja syy-seuraussuhteista, muttei välttämättä muistutella vuorovaikutusten jäsentämisen historiallisista tavoista. Tottahan sitten on myös tekstejä ja yleisöjä, jotka ajattelevat historian kautta tai nojaavat vanhoihin oppeihin, joten terminologiaakin on toki syytä tuntea. Seuraavassa kuitenkin tullaan jo sen kysymyksen äärelle, että kuinka paljon on hyödyllistä tuntea?
4.4 Sisäkkäiset, ristikkäiset ja satunnaismuuttuja-asetelmat
Howell käyttää kohtalaisesti sivuja satunnaisten, sisäkkäisten (nested) ja ristikkäisten (crossed) koeasetelmien erilaisen analysoinnin kuvailuun. Ohitan sitä osiota tässä, koska nykyään niin paljon hyödynnetään regressio- ja sekamalleja (mixed-effects model). Näissä paljon käytettyjen pakettien algoritmit eivät välitä crossed-nested erosta ja ovat huomattavasti joustavampia satunnaisille efekteille. Ne myös nojaavat enemmän mallintamisen logiikkaan. Jos olet sisäistänyt faktoriaalisen varianssianalyysin perusajatukset, pystyt kyllä halutessa ja tarvittaessa omaksumaan myös sen variantteihin liittyvät huomiot. Näiden sijaan, siirrymme tässä seuraavaksi toistomittausasetelmaan. Viimeisessä osiossa keskitymme edeltäneiden kohtien aineistojen visualisointiin R-ohjelmassa. Katsotaan kuitenkin satunnaismuuttuja-asetelmaa (random design) lyhyesti uuden notaation esittelyn mielessä.
Howell on esittänyt yksinkertaisen varianssianalyysin seuraavalla tutuksi muodostuneella notaatiolla:
missä \(\tau_{j}\) on ryhmän \(j\) keskiarvon poikkeama yleiskeskiarvosta \(\mu\) ja \(\varepsilon_{ij}\) on henkilöarvon \(ij\) normaalisti jakautunut poikkeama ryhmän keskiarvosta, eli residuaali (ryhmittelyllä selittämättä jäävä poikkeama). Tämä esitys ei määritä jakaumaa ryhmätason poikkeamille \(\tau_{j}\), koska ne ajatellaan populaation kiinteiksi tosiarvoiksi (fixed effects). Jos taas ryhmät ajatellaan otoksiksi laajemmasta populaatiosta, ne eivät ole kiinteitä parametreja vaan satunnaismuuttujan arvoja. Tämä mahdollistaa pienen, mutta tärkeän lisäyksen yllä olevaan notaatioon: \(\tau_{j} \sim N(0, \sigma_{\tau}^2)\). Oletamme siis, että \(\tau_{j}\) ovat poimintoja normaalijakautuneesta populaatiosta, ja yksittäisten arvojen sijaan, kiinnostuksemme kohdistuu niiden vaihteluun \(\sigma_{\tau}^2\). Aiemminkin kiinnostuksemme kohdistui samankaltaiseen suureeseen apuvälineenä nollahypoteesin \(\tau_1 = \tau_2 = \cdots = \tau_k = 0\) tutkimiseen. Nyt se kuitenkin kohdistuu siihen todellisena populaatioparametrina ja poikkeama-arvoille oletetaan todennäköisyysjakauma.
Voisimme esimerkiksi ajatella, että \(\tau_j\) on henkilön \(j\) verenpaine-ero väestökeskiarvosta ja \(\varepsilon_{ij}\) yksi saman henkilön lukuisten varenpainemittausten mittausvirheistä, tai vaihtoehtoisesti, että se edustaa hänen päivittäisvaihteluaan. Tällöin varianssitermi \(\sigma_{\varepsilon}^2\) vastaa mittausvirhevaihtelua ja varianssitermi \(\sigma_{\tau}^2\) yksilöiden välisten erojen merkitystä vastemuuttujan \(Y\) vaihtelussa (eli kaikille verenpainemittauksille).4 Samalle mallille on olemassa myös helpommin luettava notaatio, missä termiä \(\varepsilon_{ij}\) merkitäänkin \(\varepsilon_{j[i]}\) korostaaksemme, että kaikki indeksit \(j[i]\) kuvaavat indeksin \(j\) alla tapahtuvaa vaihtelua (esim. saman henkilön \(j\) eri arvoja \(j[i]\)):
Tämä on “random design” ANOVA-malli. Se on myös toistomittaus-ANOVA, joskin tyypillisemmin sen otsikon alle laitetaan useamman selittävän muuttujan malleja. Malli kulkee myös nimellä “random-effects model”, eli satunnaisvaikutusmalli. Ainoa ero on, että jälkimmäinen estimoidaan eri tavoin kuin perinteinen ANOVA. Palataan tähän alempana.
4.5 Toistomittausasetelmat
Yllä näimme faktoriaalisen varianssianalyysin, jossa oli useampi selittävä/luokitteleva muuttuja (koekonditio ja ikä). Toistomittaus-varianssianalyysi (repeated measures ANOVA) vastaa sikäli samanlaista ongelmaa, että siinäkin voi olla kaksi muuttujaa. Nyt kuitenkin toinen muuttujista on esimerkiksi “koehenkilöt” ja sen tasot koehenkilöitä, joten heidän havaitut arvonsa toistomittaus-muuttujan tasoilla eivät ole riippumattomia. Kirjan esimerkissä havaintoyksikkö on migreenin kesto tietyn viikon (toistomittausmuuttujan taso) aikana tietylle ihmiselle (henkilömuuttujan taso). Kaksi ensimmäistä kokeen aikaista viikkoa edusti perustasomittauksia ja kolme jälkimmäistä viikkoa rentoutusharjoittelun aikaisia viikkoja. Katsotaan tätä aineistoa alla olevassa koodipätkässä:
# muutetaan sama aineisto pitkään muotoon (tidy-muotoon; vrt. OSAn 3 video)migraine_long <- tidyr::pivot_longer(migraine, cols = tidyr::starts_with("Week"),names_to ="week")head(migraine_long)
# aov-funktio haluaa faktori-muuttujia, joten muutetaan ne sellaisiksimigraine_long$Subject <-factor(migraine_long$Subject)migraine_long$week <-factor(migraine_long$week)
Katsotaan sitten lyhyesti kuinka kirjan laskut tehdään R:ssä. Howellin kirja kuvaa neliösummien johtamista, mutta hänen taulunsa 14.3 c-kohdasta nähdään lopputuloksen vastaavuus seuraavaan R-tulosteeseen:
summary(aov(value ~ week +Error(Subject), data = migraine_long))
Error: Subject
Df Sum Sq Mean Sq F value Pr(>F)
Residuals 8 486.7 60.84
Error: Within
Df Sum Sq Mean Sq F value Pr(>F)
week 4 2449.2 612.3 85.04 <2e-16 ***
Residuals 32 230.4 7.2
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Tässä muuttujan “week” tasot siis merkitsevästi poikkeavat toisistaan. Käskyn osa Error(Subject) kertoo, että muuttuja Subject on virhe- tai satunnaistermi ennemmin kuin tavallinen kiinteä vaikutus (fixed effect). Sen tosiseikan mallintaminen, että ihmiset eroavat systemaattisesti toisistaan, poistaa ihmisten välisen vaihtelun residuaalista ja lisää voimaa havaita viikko-muuttujan ero virhevaihtelusta.
Toistomittauksen taustalla olevaa henkilöä on luontevaa ajatella satunnaisvaikutuksena (random effect). Harvoin on perusteltua ajatella, ettei henkilöitä voisi olla enempää tai eri henkilöitä – etteivät he olisi otoksia jostain populaatiosta. Kun toinen muuttuja (viikko) on kiinteävaikutuksinen (fixed effect) ja toinen muuttuja (henkilö) on satunnaisvaikutuksinen (random effect), toistomittausmalli on ns. “sekamalli”, eli “mixed-effects model”. Lisäksi sama henkilö esiintyy nyt useassa “ryhmässä”, eli week-muuttujan kaikilla eri tasoilla, ja samasta henkilöstä tulevat kiinteän vaikutuksen mittaukset (viikot) voivat korreloida keskenään. Matilta ei ehkä rentoutuminen onnistu missään vaiheessa ja Maijalta taas onnistuu luontaisesti heti kättelyssä. Toistomittausmalli voidaan esittää symbolisesti yksinkertaisesti lisäämällä kiinteä viikkovaikutus \(x\) yllä nähtyyn yhtälöön:
Koska week-muuttujan tasoja ei ajatella satunnaisiksi, en esittellyt sitä varianssiterminä, vaan käytin sekamalleille tyypillistä notaatiota. Aiemmin oletimme virhetermin normaalijakautuneeksi, \(\varepsilon_{j[i]} \sim N(0, \sigma_{\varepsilon}^2)\), mitä tutkimme alla tarkemmin vielä. Koska oletimme virheet myös toisistaan riippumattomiksi, nyt kaikkien viikkojen mittausten yhteisvaihtelu tulee ajassa vakiona pysyvien termien \(\tau_{j}\) henkilöiden välisestä vaihtelusta ja on siksi saman suuruista kaikkien viikkojen välillä. Aineiston jakauma muistuttaa siten palloa ennemmin kuin ellipsiä viikkomittausten muodostamassa moniulotteisessa avaruudessa. Tämä oletus tulee siis mallista ja sen hajoaminen aineistossa tarkoittaa, etteivät neliösummien osamäärät enää jakaudu nollahypoteesista ennakoitavan F-jakauman mukaisesti edes nollahypoteesin pätiessä. Tälle voidaan onneksi perinteisenkin varianssianalyysilaskennan piirissä tehdä korjaus. Katsotaan yksi esimerkki siitä, kuinka tämän Howellinkin käsittelemän pallosymmetria-korjauksen voi suorittaa R-ohjelmassa:
# Geiser-Greenhouse-korjaus:# Huomaa, ettei funktio ymmärrä aiempaa Error(Subject)-notaatiota,# vaan haluaa lukea vain Error(Subject/week)-notaation.rstatix::anova_test(migraine_long, value ~ week +Error(Subject/week))
ANOVA Table (type III tests)
$ANOVA
Effect DFn DFd F p p<.05 ges
1 week 4 32 85.042 1.39e-16 * 0.774
$`Mauchly's Test for Sphericity`
Effect W p p<.05
1 week 0.282 0.537
$`Sphericity Corrections`
Effect GGe DF[GG] p[GG] p[GG]<.05 HFe DF[HF] p[HF]
1 week 0.684 2.74, 21.9 5.77e-12 * 1.076 4.3, 34.42 1.39e-16
p[HF]<.05
1 *
# Howell on laskenut kovarianssin eri jakajalla kuin R. Saat saman ao. tavalla:cov(migraine[-1, -1])*(nrow(migraine)-1)/nrow(migraine) # (ei tulosteta tähän)
Vaikka neliösummien laskemiseen perustuvaa varianssianalyysia voidaankin näin korjata aineiston ongelmille, kuten pallojakauma-oletuksen rikkoutumiselle, on se varsin jäykkä menetelmä. Esimerkiksi niiden henkilöiden tietoja ei voitaisi lainkaan käyttää, jotka eivät ole raportoineet migreenimääriään kaikilta viideltä viikolta. Toisaalta sellainen ei olisi mikään ongelma nykyään rutiininomaisesti hyödynnettäville lineaarisille sekamalleille. Tämä vastaa aiempia huomioitamme: kun estimoi mallin, siltä voi kysyä mitä haluaa. Klassisessa varianssianalyysissa taas malli on vain taustalla oleva teoreettinen olio, eikä sitä estimoida kokonaisuudessaan – ainoastaan rakennetaan epäsuoria testejä sen osille. Lähestymistapa oli hyvin käytännöllinen aikana, jolloin emme pystyneet helposti estimoimaan malleja, mutta vaikeammin perusteltavissa nykyisin, kun pystymme. Ainakin opetuskäytön ulkopuolella. Vaikka palaammekin asiaan myöhemmin pidemmin, katsotaan siis jo nyt kuinka yllä annettu symbolinen esitys, eli toistomittaus-varianssianalyysin olennainen idea, voidaan implementoida sekamallissa R:ssä.5
# sovitetaan sekamalli henkilön vakiotasoa kuvaavalla random-efektilläfit <- glmmTMB::glmmTMB(value ~ week + (1|Subject), data = migraine_long)# sovitetaan nollamalli, joka olettaa, ettei rentoutusharjoittelu vaikutafit0 <- glmmTMB::glmmTMB(value ~ (1|Subject), data = migraine_long)# todetaan malleja vertaamalla, että harjoittelu merkittävästi vaikuttaaanova(fit0, fit)
Tässä siis totesimme saman kuin ANOVA-testilläkin, että rentoutus vaikuttaa. Palataan tulosteen AIC- ja BIC-arvoihin myöhemmin, mutta testin kohdalla kohtasimme myös luennolla mainitut log-uskottavuusfunktion arvot (logLik) ja niistä lasketun \(\chi^2\)-testisuureen (Chisq) vapausasteineen (Df, viikkojen lkm miinus yksi), sekä testisuureesta lasketun p-arvon (Pr(>Chisq)). Tämä oli p-arvo nollahypoteesille, ettei viikko-dummyt sisältävä malli (eli vaihtoehtoinen hypoteesi) poikkea niitä sisältämättömästä nollamallista (nollahypoteesi, että viikko-ryhmäkeskiarvot samoja). Siinä missä varianssianalyysitekniikat lisäksi antaisivat meille erilaisia keskineliötermejä, joiden suhteet (F-arvot) riippuvat migreenin aikavakioisten keskitasojen vaihtelusta henkilöiden välillä, \(\sigma_{\tau}^2\), sekamalli antaa suoran estimaatin suureelle \(\sigma_{\tau}^2\) ja sen neliöjuurelle, \(\sigma_{\tau}\), eli yksilöllisten erojen populaatiokeskihajonnalle. Tämä löytyy alla olevan tulosteen riviltä “Subject (Intercept)”, kohdan “Random effects” alta. Sieltä näemme, että myös residuaalivarianssi \(\sigma_{\varepsilon}^2\) on satunnaisvaikutus, ja näin onkin kaikissa malleissamme (ANOVA, regressio, sekamallit, jne.).
Malli on vähän hassusti ottanut kiinteän viikko-vaikutuksen referenssitasoksi viikon 5, eikä glmmTMB-paketti näköjään osaa lukea annettua referenssitasoa vakioksi (Intercept), mutta halutessaan on aina mahdollista tehdä dummy-muuttujat itse ennen mallin sovittamista. Vaikka se onnistuu helposti ohjelmoimallakin, tähänkin tarkoitukseen on olemassa R-paketti, makedummies, jossa on vain yksi funktio nimeltään, makedummies.
4.6 Visualisoinnista
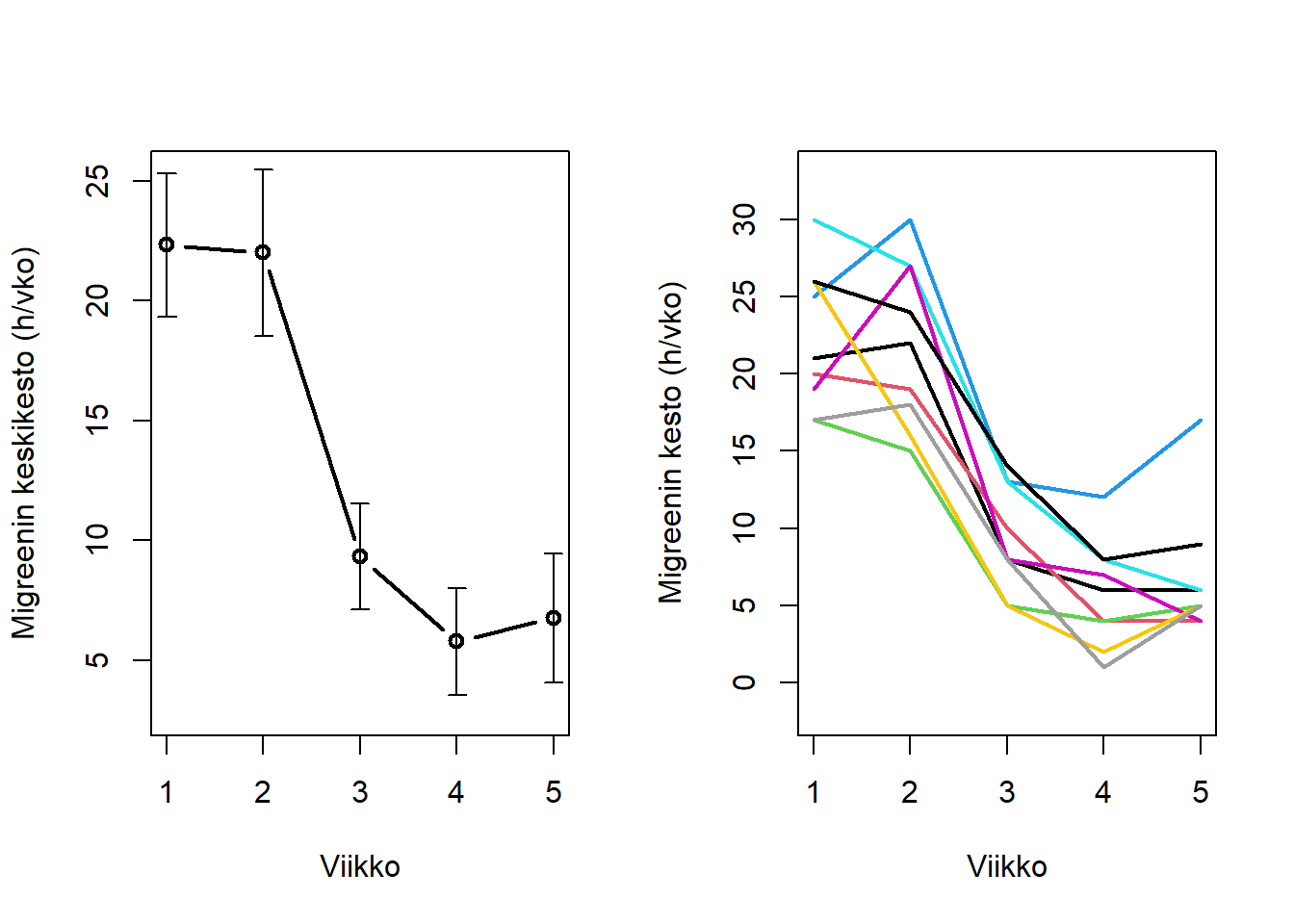
Yllä hyödynnetty aineisto antaa hyvän tilaisuuden tutustua käytännössä R-grafiikkaan, eli viikon R-ohjelmointiteemaan. Tehdään esimerkin vuoksi ns. viivakuvio (line plot) luottamusväleineen, ensin peruspaketteja hyödyntäen ja sitten ggplot2-tyylillä. Piirretään ensin kuvaan ryhmäkeskiarvot ja sitten sen toiseen paneeliin henkilöiden havaitut arvot usealla viivalla, jolloin visualisoimme kouriintuntuvasti myös yksilöllisten erojen tuntuvaa merkitystä kokonaisvaihtelussa.
y <-colMeans(migraine[, -1]) # viikkoryhmäkeskiarvot vektorinax <-1:5# viikot vektorinay_sd <-apply(migraine[, -1], 2, sd) # viikkoryhmäkeskihajonnatpar(mfrow =c(1,2)) # asetetaan kuvaan kaksi paneelia# piirretään y-vektorin arvot vasten x-vektorin arvoja (viiva + pallot; both, b)plot(x, y, lwd =2, type ="b", ylim =c(min(y)-3, max(y)+3),xlab ="Viikko", ylab ="Migreenin keskikesto (h/vko)")# piirretään luottamusväli-viikset samaan kuvaan:arrows(x, y -1.96*y_sd/sqrt(nrow(migraine)), x, y +1.96*y_sd/sqrt(nrow(migraine)), angle =90, code =3, length =0.05)# piirretään kaikkien henkilöiden havaitut aikakulut yhteen kuvaan:plot(x, migraine[1, -1], type ="l", col =1, lwd =2,ylim =c(min(migraine[,-1])-3, max(migraine[,-1])+3),xlab ="Viikko", ylab ="Migreenin kesto (h/vko)")for (i in2:nrow(migraine)) lines(x, migraine[i, -1], col = i, lwd =2)
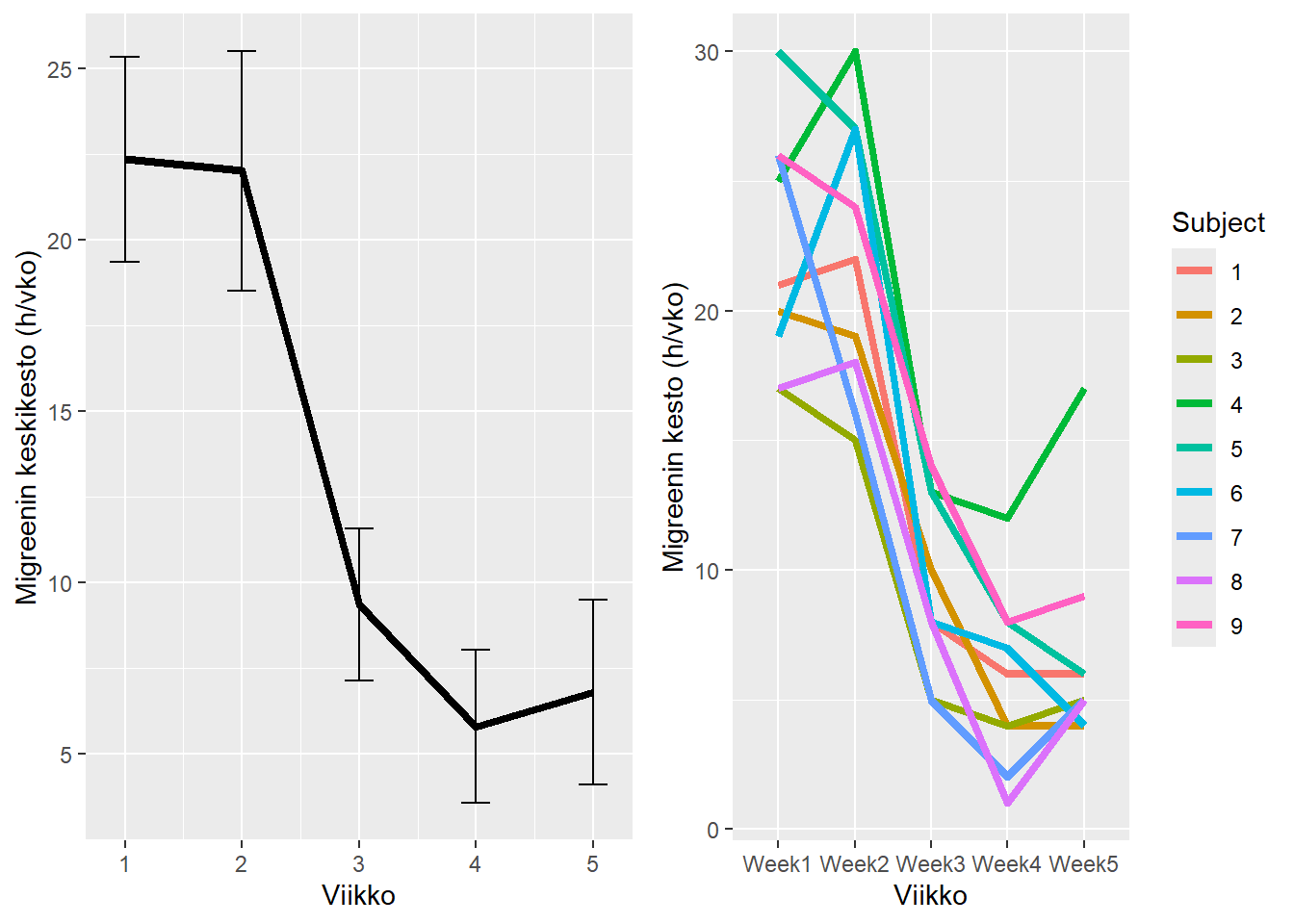
Peruspaketit tarjoavat käyttäjälle melko täydellisen hallinnan sen suhteen mitä kuvaan tulee. Toisaalta hallinta edellyttää käyttäjältä tietoa tai aktiivista googlausta tai muuta avunhakua. Myös ggplot2 paketti tarjoaa paljon hallintaa visualisointiin, mutta omaksuu hieman erilaisen filosofian. Se pyrkii olemaan visualisoinnin ohjelmointikieli, joka noudattaa aiemmin kohtaamaamme tidy-data-periaatetta. Katsotaan vielä tuo tapa saman asian tuottamiseksi:
library(ggplot2) # ladataan paketti# se haluaa data-objekteja, joten tehdään niitä ja putkitetaan kuviin:pdat <-data.frame(x, y, y_lci = y -1.96*y_sd/sqrt(nrow(migraine)),y_uci = y +1.96*y_sd/sqrt(nrow(migraine)))# Luodaan ensimmäinen paneeli muuttujaan:p1 <- pdat |>ggplot(aes(x, y, ymin = y_lci, ymax = y_uci)) +geom_line(linewidth=1.5) +geom_errorbar(width =0.25) +xlab("Viikko") +ylab("Migreenin keskikesto (h/vko)")# Luodaan toinen paneeli muuttujaan:p2 <- migraine_long |>ggplot(aes(x=week, y=value, group = Subject)) +geom_line(aes(colour = Subject), linewidth =1.5) +xlab("Viikko") +ylab("Migreenin kesto (h/vko)")# Piirretään/kautta tulostetaan koko kuva:gridExtra::grid.arrange(p1, p2, ncol =2)
Huomaamme, että ggplot2-paketin syntaksi on melko erilaista kuin R:n perusgrafiikan. Kenties tottumuksen voimasta, itse pidän helpompana muistaa ja usein käytän vektoreille perustuvaa perusgrafiikkaa, mutta moni vaikuttaa pitävän ggplot2:n graafisesta kielestä. Sillä myös saa usein aavistuksen tyylikkäämmän näköisen lopputuloksen, jos jaksaa näpertää, mutta kumpikin tapa halutessa johtaa todella tyylikkäisiin visualisointeihin.
4.6.1 Mallioletusten tarkastelua visualisoiden
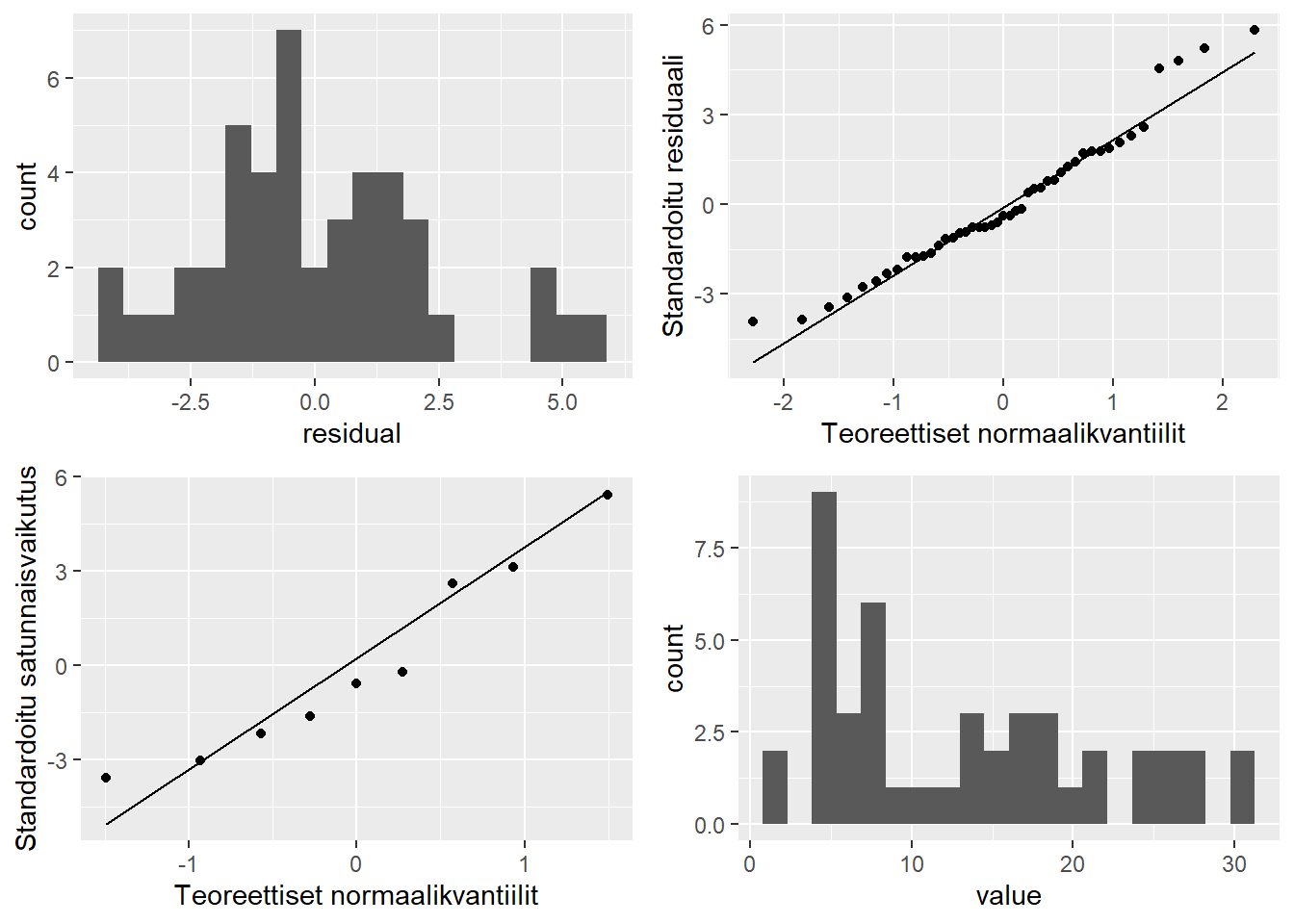
Niin sekamallit kuin varianssianalyysi tekevät varianssihajotelmia koskevia oletuksia. Erityisesti normaalijakautuneisuus aiheuttaa usein kohtuutonta huolta soveltajille. Nimittäin jakauman muotoa testaavat tilastolliset testit ovat paljon herkempiä jakaumapoikkeamille kuin jakaumaoletuksia käyttävät menetelmät, joiden kohdalla on usein kyse lähinnä pienestä lovesta voimafunktioon. Tästä syystä visualisoinnit voivatkin tarjota mielekkään tavan todeta hyvin selvät poikkeamat oletuksista. Katsotaan muutama tällainen ggplot2-pakettia hyödyntäen:
Yllä olevan kuvan ensimmäinen paneeli piirtää tavallisen residuaaliestimaattien (\(\hat{\varepsilon}\)) histogrammin. Jakauma ei vaikuta aivan normaaliselta, vaan pieni joukko korkeitä arvoja erottuu muista. Ilmiö näkyy hyvin myös residuaalien Q-Q-kuvassa (2. paneeli), muttei erityisemmin estimoiduissa henkilökeskiarvoissa, eli satunnaisvaikutuksissa (\(\hat{\tau}\); 3. paneeli).6 Poikkeamien taustalla ei siis ehkä olekaan yksittäinen henkilö vaan ehkäpä jokin migreeniin liittyvä prosessi. Viikoittaisen migreenissä vietetyn ajan jakauma onkin vahvasti vino oikealle (4. paneeli), mikä voisi vihjata kertautuvasta prosessista (pahat tapaukset eksponentiaalisen pahoja). Koska \(\log(ab) = \log(a) + \log(b)\), kertautuvat prosessit saadaan mallinnettua summautuvina (vrt. normaalijakautuneet prosessit), ottamalla sopivasti siirretyistä arvoista logaritmi. Tehdään tämä alla ja tutkitaan regressiodiagnostiikka uudestaan:
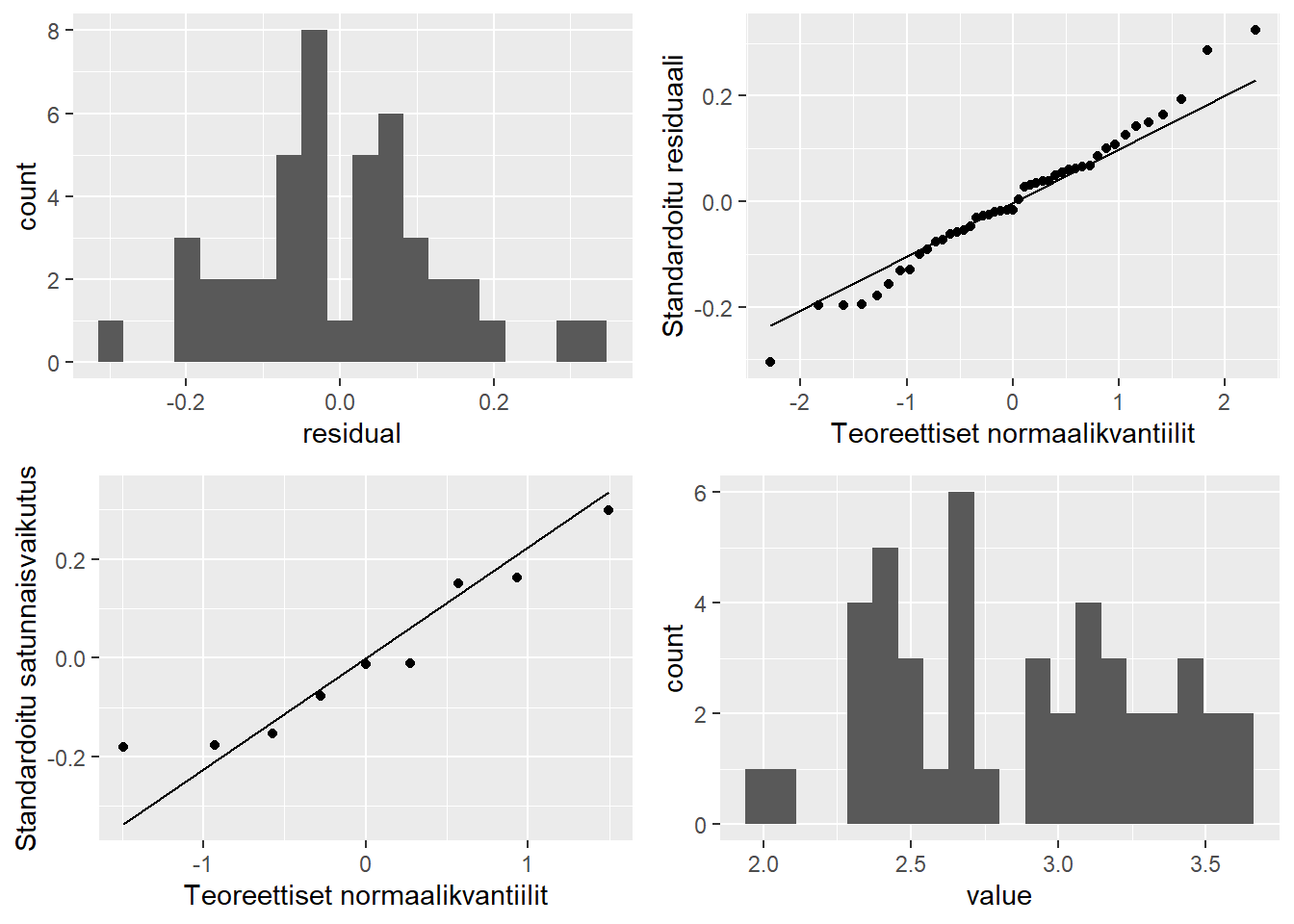
# Tehdään väliaikainen aineisto, jossa vastemuuttuja on logaritmi-muunnettu:dtmp <- migraine_longdtmp$value <-log(dtmp$value +6)# Sovitetaan malli uuteen aineistoon ja piirretään kuva uudestaan:fit <- glmmTMB::glmmTMB(value ~ week + (1|Subject), data = dtmp)ref <- glmmTMB::ranef(fit) # random-efektit (tau)ref <-as.numeric(ref[[1]]$Subject[[1]]) # muutetaan numeeriseksi vektoriksires <-residuals(fit) # tavalliset residuaalit (epsilon)# Tehdään paneelit muuttujiin:p1 <-data.frame(residual = res) |>ggplot(aes(x=residual)) +geom_histogram(bins =20)p2 <-data.frame(residual = res) |>ggplot(aes(sample=residual)) +geom_qq() +geom_qq_line() +xlab("Teoreettiset normaalikvantiilit") +ylab("Standardoitu residuaali")p3 <-data.frame(residual = ref) |>ggplot(aes(sample=residual)) +geom_qq() +geom_qq_line() +xlab("Teoreettiset normaalikvantiilit") +ylab("Standardoitu satunnaisvaikutus")p4 <- dtmp |>ggplot(aes(x=value)) +geom_histogram(bins =20)# Piirretään paneelit muuttujista samaan kuvaan:gridExtra::grid.arrange(p1, p2, p3, p4, ncol =2)
Nyt residuaalit käyttäytyivät ehkä aavistuksen nätimmin ja ainakin selvin vinous jakaumista on poisettu monotonisella (järjestyksen säilyttävällä) logaritmi-muunnoksella. Vaikkei tilanne ole täysin ideaalinen, ei ylitulkita pientä (pseudo)aineistoa. Tutkitaan sen sijaan vielä saammeko tästä huolimatta samat laadulliset johtopäätökset, mikä edelleen vahvistaisi uskoa, että olemme tulkinneet aineistoa ja harjoitusviikon suurta vaikutusta oikein:
# sovitetaan myös nollamalli uuteen aineistoonfit0 <- glmmTMB::glmmTMB(value ~ (1|Subject), data = dtmp)# ja verrataan log-muunnetun aineiston malleja, kuten aiempia:anova(fit0, fit)
Näemme, että aiempi laadullinen tulos (merkitsevyydet ja arvojen suhteet) säilyi varsin hyvin muunnetussa aineistossa.
4.7 Yhteenveto
Lisäpakettien sisältöä voi tuoda R:n montaa reittiä.
Faktoriaalisessa varianssianalyysissa on useampi muuttuja ja mahdollisesti niiden interaktioita, mutta se voidaan käsitellä regressiomallina.
Yleisemminkin varianssianalyysit voidaan käsitellä lineaarisina sekamalleina.
Valittua estimointi- ja testausmenetelmää on hyvä ymmärtää, mutta vielä tärkeämpää on ymmärtää taustalla vaikuttavaa tilastollista mallia.
Jos tilastollisen mallin estimoi, siihen liittyviä kysymyksiä voi tyypillisesti esittää joustavammin ja ymmärrettävämmin, kuin malliaosien epäsuoria testitekniikoita käytettäessä.
Epäsuorat tekniikat voivat johtaa yksinkertaisempiin laskuihin rajatuissa erityistapauksissa, mutta laskut joka tapauksessa tehdään yleensä tietokoneohjelmalla, jolloin epäsuorat tekniikat voivat tuntua käyttäjän kannalta myös vähemmän yksinkertaisilta.
On olemassa useampia R-paketteja grafiikan tuottamiseen, joista erityisesti peruspaketti ja ggplot2 ovat paljon käytettyjä.
4.8 Alaviitteet
Saman tilastollisen mallin tekijöille voi olla useita vaihtoehtoisia estimaattoreita, eli arviointimenetelmiä, mutta kaikkein tärkeintä on tietää mitä yrittää arvioida (eli ymmärtää itse mallia ja sen yhteyttä psykologiaan tai muuhun sovellusalueeseen).↩︎
Muista, että esim. 4.8e-01 tarkoittaa lukua \(0.48\).↩︎
Matemaattisesti “käsittelyvaikutus” ja “hoitovaikutus” ovat sama konsepti, mutta hoitoon liittymättömissä kokeissa “treatment effect” ehkä kääntyy luontevammin käsittely- kuin hoitovaikutukseksi.↩︎
Näiden suhde, \(\frac{\sigma_{\tau}^2}{\sigma_{\tau}^2 + \sigma_{\varepsilon}^2}\), olisi mittauksen reliabiliteetti, tai yleisemmin, intra-class correlation (ICC).↩︎
R-paketeista “lme4” on ollut perinteisesti käytetty “linear mixed-effects” mallinnuspaketti, mutta uudempi glmmTMB-paketti on numeerisesti robustimpi ja sen käyttäjä kohtaa vähemmän optimointialgoritmiin liittyviä virheilmoituksia ja säätötarpeita. Formula-syntaksi on molemmissa paketeissa sama.↩︎
Q-Q-kuva vertaa järjestettyjä arvoja normaalijakaumasta odotettuihin arvoihin ja näimme, että suurimmat residuaaliarvot olivat odotusta suurempia.↩︎