2OSA 2: Yksisuuntainen ANOVA, regressio ja matriisit
Tässä osassa käymme läpi yksisuuntaista varianssianalyysia (analysis of variance, ANOVA), mutta huomaamme jo samoin tein yhteyden lineaariseen regressiomalliin, kuten PSYK-381-kurssilla. Ennen tähän materiaaliin etenemistä, sinun tulisi lukea Howellin kirjan kappale 11 (Simple Analysis of Variance) sekä käydä läpi OSAn 2 videoluennot.
2.1 Esimerkkiaineiston tuominen ja simulointi
Kirjassaan Howellkin paljastaa luoneensa Eysenckin aineiston simuloimalla. Oletettavasti, koska Eysenck raportoi vain keskiarvot ja varianssit. Hän jättää kuitenkin kertomatta kuinka sen teki. Me sen sijaan sekä luomme itse aineiston, että tutkimme hänen aineistoaan tavoitteenamme replikoida Howellin tuloksia R-ohjelmassa. Jottei jokaisen tarvitse näpytellä aineistoja käsin koneelleen, katsomme myöhemmin kuinka kurssin aineistot saa yhdellä käskyllä käyttöönsä. Tässä kohdin on kuitenkin instruktiivista nähdä kuinka R:n voi syöttää pieniä aineistoja käsin (copy-pastella). Katsotaan alla ensin kuinka aineistoa voisi syöttää suoraan datatauluun, mutta tehdään sitten varsinainen työ tavalla, jossa riittää lisätä pilkut leikattujen ja liimattujen lukujen väliin – syöttämällä havainnot matriisi-objektiin ja muuttumalla se datataulu-objektiksi.
# nimetään aineisto kuvaavamminhowell_eysenck_data <- HEdata# poistetaan turhaksi jäänyt vanha aineisto-objekti muististarm(HEdata) # HUOM: "rm" viittaa sanaan "remove"
Kokeillaan myös kuinka aineiston voisi lukea tiedostosta, eli tallennetaan se ensin csv-tyyppiseen tekstitiedostoon, poistetaan aineisto muistista ja tuodaan se sinne uudestaan tiedostosta lataamalla. Ensin on kuitenkin tarpeen tietää missä kansiossa työskentelemme ja vaihtaa haluttuun työskentelykansioon, joka sinulla on eri niminen kuin kirjoittajalla alla. [R-työskentely on usein mielekkäämpää paikallisessa kansiossa kuin verkkokansiossa].
# Katsotaan ensin missä kansiossa työskentelemmegetwd()
[1] "C:/LocalData/rosenstr/opetus/psyk382kirja"
# Siirrytään haluttuun kansioonsetwd("C:/LocalData/rosenstr/opetus/psyk382kirja")# Tallennetaan csv-muotoinen aineisto ko. työkansioonwrite.csv(howell_eysenck_data, file ="howell_eysenck.csv", row.names =FALSE)# Poistetaan data muistista ja todetaan sen poistuminenrm(howell_eysenck_data) # data poistuu muististals() # data ei listaudu muistissa olevien objektien joukossa
[1] "musat"
# Kurkataan aineistoa suoraan tiedostosta (HUOM: oltava oikeassa kansiossa)readLines("howell_eysenck.csv", n =4)
# Tuodaan data takaisin tiedostosta (HUOM: oltava oikeassa kansiossa)howell_eysenck_data <-read.csv("howell_eysenck.csv")# Tarkastellaan aineistoa (vrt. Howellin kirja)howell_eysenck_data
Kurssin videomateriaaleissa näytetään kuinka kansioita voi vaihtaa RStudio:n valikoista suoraan, mikä voi ensin tuntua luentevammalta. Varsin usein tulee kuitenkin vastaan tilanteita, joissa on osattava komentoriviltä tai koodissa ohjeistaa R-sessio oikeaan paikkaan. Yksinkertaiset verkkohaut ja tekoälyavustajat tarvittaessa tuottavat paljon materiaalia tällaisista perusoperaatioista ja tässä riittääkin vähän tutustua asiaan ja ymmärtää keskusmuistin ulkopuolisia (tallennuslevyjen) kansiorakenteita (ks. video asiasta).
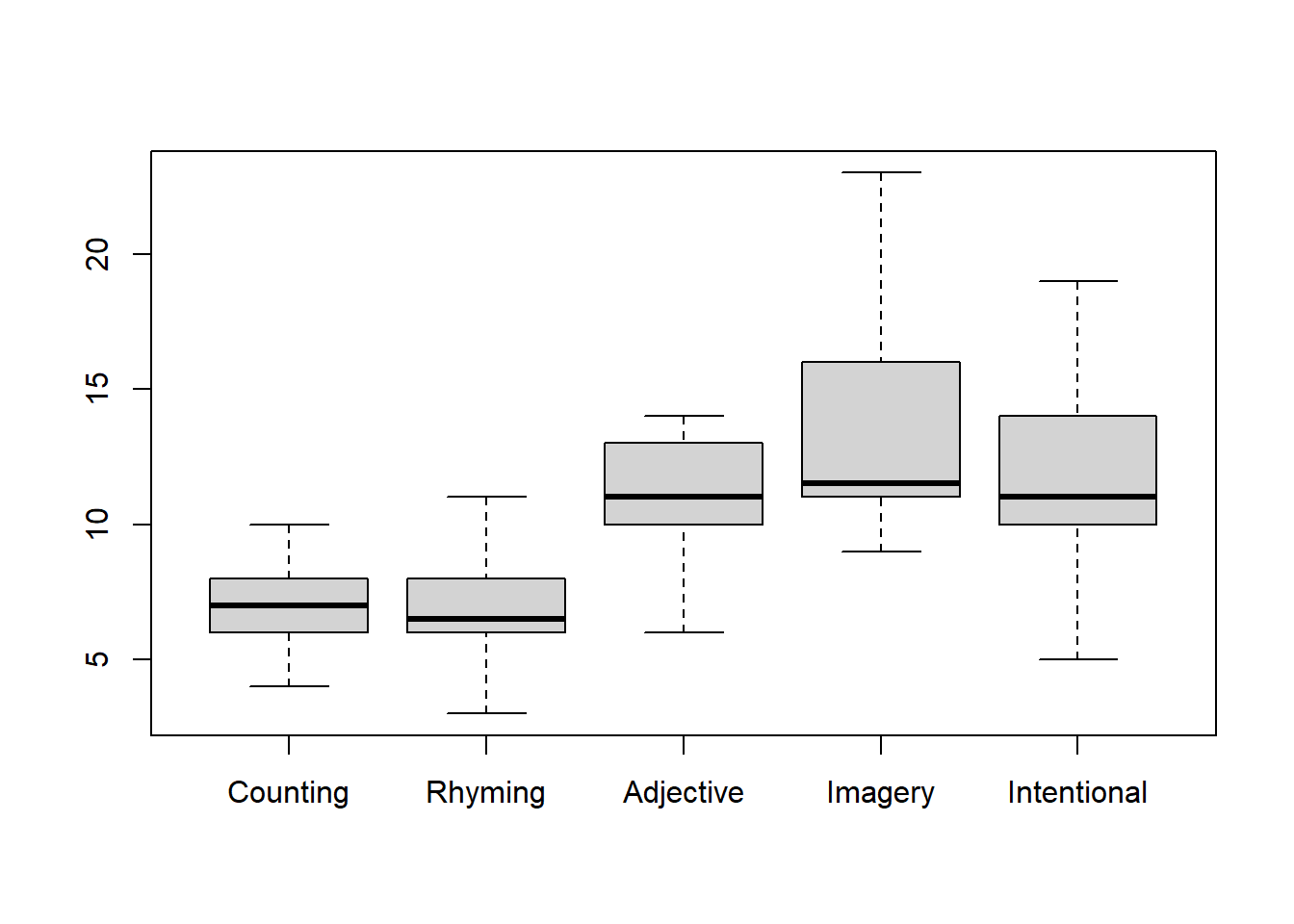
Tarkastellaan seuraavaksi Howellin alkuperäisen aineiston tunnuslukuja, todeten, että samalta näyttää kuin kirjassa:
Erityisesti huomaamme kuinka varianssi yli koko aineiston on suurempi kuin yhdistetty (pooled) ryhmäkohtainen varianssi. Muistammekin, että ANOVA perustuu näiden varianssien F-testiin perustuvalle vertailulle. Ryhmäkohtaisten (within-group) varianssien ohella koko aineiston varianssia lisää mahdolliset ryhmien väliset erot, eli ryhmien välinen varianssi (between-group variance). Nollahypoteesi toisaalta on, että kokonaisvarianssi ja ryhmäkohtaiset varianssit eivät eroaisi, koska ryhmien välistä (niiden keskiarvojen) varianssia ei olisi:
\[
H_0: \mu_1 = \mu_2 = \mu_3 = \mu_4 = \mu_5.
\]
Nyt olemme tuoneet aineiston R-ympäristöön, mutta voimme myös luoda oman aineiston. Tätä varten (ja muutoinkin) on keskeistä ymmärtää ANOVA-menetelmän taustalla oleva aineistoa generoiva tilastollinen malli. Vaikkemme aineistoa näin eksplisiittisesti itse loisikaan, mallin konepellin alla toimiva matemaattinen todellisuus joka tapauksessa vastaa tätä tilastollista mallia. Simulaatio on näin toinen ikkuna samaan todellisuuteen, ja monelle se ehkä tekee abstrakteja yhtälöitä ja symboleja ymmärrettävämmäksi, kun saa pelata luvuilla myös. Tässä tapauksessa Howell ilmaisee aineistoa generoivan mallin seuraavasti:
\[
X_{ij} = \mu + \tau_j + \epsilon_{ij},
\]
missä \(X_{ij}\) on vastemuuttuja, eli muistetut sanat, \(\mu\) keskimääräinen (odotusarvoinen) muistettujen sanojen lkm, \(\tau_j\) ryhmän \(j\) keskiarvon poikkeama kokonaisodotusarvosta ja \(\epsilon_{ij}\) on ryhmän \(j\) henkilön \(i\) muistamien sanojen poikkeama ryhmäkeskiarvosta, eli residuaali ryhmäkeskiarvolla ennustettaessa. Malli olettaa, että \(\epsilon_{ij} \sim N(0, \sigma_{\epsilon})\) kaikilla \(i\) ja \(j\), eli varianssien homogeenisyyden. R taas ilmaisee saman asian ja luo uuden aineiston mallista esimerkiksi seuraavasti:
# parametrit:N <-nrow(howell_eysenck_data)*ncol(howell_eysenck_data) # Havaintojen lkmNpG <- N/ncol(howell_eysenck_data) # Havaintojen määrä per ryhmämu <-mean(unlist(howell_eysenck_data)) # kokonaisodotusarvose <-mean(sapply(howell_eysenck_data, var)) # sigma epsilontau0 <-rep(0, 5) # nollahypoteesi - ei ryhmäerojatau1 <-sapply(howell_eysenck_data, mean) - mu # havaitun kokoiset ryhmäerot# nollahypoteesin mukainen simuloitu aineistoset.seed(2026)dat0 <-data.frame(x = mu +rnorm(n = N, mean =0, sd =sqrt(se)) +rep(tau0, each = NpG),group =rep(names(howell_eysenck_data), each = NpG))# havaittuja ryhmäkeskiarvoja mukaileva simuloitu aineistoset.seed(2026)dat1 <-data.frame(x = mu +rnorm(n = N, mean =0, sd =sqrt(se)) +rep(tau1, each = NpG),group =rep(names(howell_eysenck_data), each = NpG))# tarkastellaan aineistoahead(dat1)
x group
1 8.6191352 Counting
2 3.6419476 Counting
3 7.4330581 Counting
4 6.7364145 Counting
5 4.9266186 Counting
6 -0.8255358 Counting
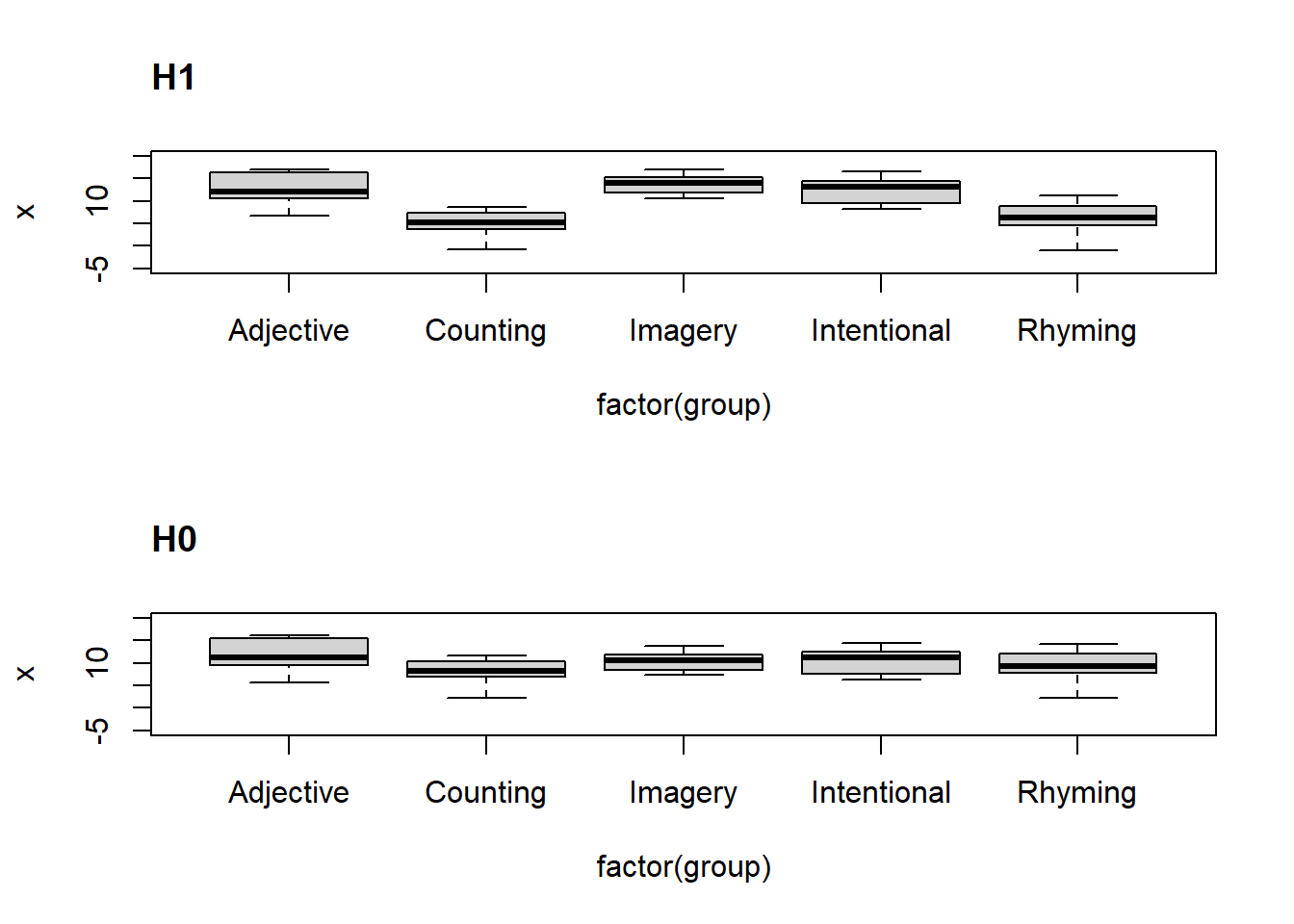
# kuvaillaan aineistojapar(mfrow=c(2,1))boxplot(x ~factor(group), data = dat1, ylim =c(-5,20))title("H1", adj=0)boxplot(x ~factor(group), data = dat0, ylim =c(-5,20))title("H0", adj=0)
Yllä näemme, että havaituilla ryhmäeroilla luodun aineiston lisäksi myös nollahypoteesia vastaavassa simulaatiossa näkyy satunnaisotannasta johtuvia ryhmäeroja. Tilastollisessa päättelyssä tarkoituksenamme onkin laskea kuinka harvoin pelkkä satunnaisotanta aiheuttaisi havaitun kokoisia ryhmäeroja. Tarkka lukija on ehkä myös havainnut, että luomamme aineisto on eri tavoin järjestetty verrattuna Howellin printtiystävällisempään esitystapaan. Sen sijaan, että esittäisimme ryhmäkohtaiset muistitestitulokset omilla sarakkeillaan, olemme yllä koonneet kaikki tulokset yhteen (x) sarakkeeseen ja viereisessä (group) sarakkeessa indeksöineet ryhmän, johon havainto kuuluu. Olemme siis muodostaneet ryhmä-statuksesta muuttujan. Tällainen “pitkämuotoinen” aineisto on tyypillisesti R:n mallinnusfunktioiden suosima esitystapa, koska ne seurailevat lineaarisen mallin logiikkaa, missä havaintoja ennustetaan muuttajilla. Näemme tätä kohta käytännössä, mutta muutetaan ensin myös Howellin aineisto haluttuun muotoon. Harjoitustehtävissä pääset tekemään sen ns. for-luuppia ja indeksöintiä hyödyntäen, mutta alla käytämme valmista työkalua tidyr-paketista (asentuu kurssin psyktools-paketin mukana, mutta voit asentaa itsekin; ks. alun videot). Sen jälkeen sovitamme lineaarisen ANOVA-mallin yllä esiteltyihin aineistoihin.
# katso rivien ja sarakkaiden määrät alkuperäisessa aineistossadim(howell_eysenck_data)
[1] 10 5
# pivotoi pitkään muotoondat_he <- tidyr::pivot_longer(howell_eysenck_data, cols = tidyr::everything(),names_to ="group", values_to ="x")# katso rivien ja sarakkeiden määrä pivotoidussa aineistossadim(dat_he)
[1] 50 2
# vertaa simuloituun aineistoondim(dat1)
[1] 50 2
# sovitetaan ANOVA-mallitfit0 <-aov(x ~factor(group), data = dat0)fit1 <-aov(x ~factor(group), data = dat1)fit_he <-aov(x ~factor(group), data = dat_he)
Pivotoinnin lisäksi yllä esiintyi aov-funktion syötteenä jokseenkin mystinen osuus x ~ factor(group). Tämä on R:n ns. formula-notaatio (kaava-notaatio). Voisit oppia siitä lisää tutkimalla komentoa ?formula, mutta suosittelen, että jatkat lukemista ja kohtaamme asian alla vaiheittain. Kaava-notaatio kriittisin tavoin määrittelee sovitettavan mallin, kun taas data-argumentti ottaa vastaan aineiston, johon se on tarkoitus sovittaa.
2.2 ANOVA-laskut, simulointi ja otantateoriaa
Yllä sovitimme malleja, mutta R ei automaattisesti tulosta mitään, kuten jotkut tilasto-ohjelmat tekevät. Sen sijaan, käyttäjä tarkastelee ratkaisun haluttuja osia aktiivisena toimijana. Pyydetään siis käyttäjäsummaus Howellin aineistoa koskevasta malliestimaatista:
# tuloksia Howellin aineistossa:summary(fit_he)
Df Sum Sq Mean Sq F value Pr(>F)
factor(group) 4 351.5 87.88 9.085 1.82e-05 ***
Residuals 45 435.3 9.67
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
# vertailun vuoksi, vastaava p-arvo itse laskien:MSw <-mean(sapply(howell_eysenck_data, var))MSb <-var(sapply(howell_eysenck_data, mean))*10F_testisuure <- MSb/MSw1-pf(F_testisuure, df1 =4, df2 =45)
[1] 1.81549e-05
Kun yllä syötimme malliobjektin summary-funktioon, näimme hyvin samankaltaisen tulosteen kuin Howellin kirjassa (s. 325, taulu 11.3, kirjan 7. editiossa). R tulostaa lisäksi myös p-arvon, eli todennäköisyyden saada suurempi tai yhtä suuri F-testisuurearvo nollahypoteesin pätiessä. Näimme myös kuinka F-testisuure muodostui jakamalla “keskiarvojen varianssi varianssien keskiarvolla” (vapausasteet huomioiden) ja kuinka p-arvo lasketaan suoraan jakaumasta. R antaa p-arvon ns. tieteellistä notaatiota käyttäen. Esimerkiksi merkintä 1.8e-05 tarkoittaa matemaattista merkintää \(1.8 \times 10^{-5} = \frac{1.8}{10^{5}} = \frac{1.8}{100000}\). Tieteellinen notaatio on järkevä tapa esittää hyvin pieniä tai hyvin suuria lukuja ja se on tunnettava ja hallittava tilastotiedettä sovellettaessa – käytännössä “e” kertoo montako nollaa lisätään ja miinus-merkin esiintyminen e:n jälkeen viittaa jakamiseen. Katsotaan nyt Howellin simulaatiotuloksia vastaava tilanne itse simuloimallemme aineistolle:
# Nollamallisummary(fit0)
Df Sum Sq Mean Sq F value Pr(>F)
factor(group) 4 68.9 17.229 2.027 0.107
Residuals 45 382.6 8.501
Df Sum Sq Mean Sq F value Pr(>F)
factor(group) 4 625.7 156.4 18.4 5.07e-09 ***
Residuals 45 382.6 8.5
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Odotetusti, nollamallista johdettu aineisto ei testissä tilastollisesti merkitsevästi poikennut nollamallin ennusteesta, vaikka varmaa se ei ollutkaan (mieti miksi?). Havaittuihin ryhmäkeskiarvoihin perustuva malli taas poikkeaa tilastollisesti merkitsevästi nollamallista. Probabilistinen ero heijastelee eroa havaituissa efektikoissa, joita voi R:ssä laskea esimerkiksi näin:
For one-way between subjects designs, partial eta squared is equivalent
to eta squared. Returning eta squared.
# Effect Size for ANOVA
Parameter | Eta2 | 95% CI
-----------------------------------
factor(group) | 0.15 | [0.00, 1.00]
- One-sided CIs: upper bound fixed at [1.00].
# Nollamalli, omega-squared kaksisuuntaisen testin CIeffectsize::omega_squared(fit0, alternative ="two.sided")
For one-way between subjects designs, partial omega squared is
equivalent to omega squared. Returning omega squared.
# Effect Size for ANOVA
Parameter | Omega2 | 95% CI
-------------------------------------
factor(group) | 0.08 | [0.00, 0.20]
# Havaittuihin ryhmäkeskiarvoihin perustunut mallieffectsize::omega_squared(fit1, alternative ="two.sided")
For one-way between subjects designs, partial omega squared is
equivalent to omega squared. Returning omega squared.
# Effect Size for ANOVA
Parameter | Omega2 | 95% CI
-------------------------------------
factor(group) | 0.58 | [0.36, 0.70]
Kun yllä harjoitimme otantaa (eli “sämpläsimme”) tilastollisen ANOVA-mallin olettamista jakaumista, teimme jotain paljon enemmän kuin vain nollamalliin keskimäärin sopivien lukujen “keksimistä”. Toteutimme digitaalisesti realisaation mallin olettamasta populaatio-otantajakaumasta. Tekemällä lisää vastaavia otantoja, voimme halutessamma similoida testisuureen koko otantajakauman (tässä tapauksessa F-jakauman). Arvioin tarkkuus toki riippuu simuloitujen otantojen määrästä, minkä vuoksi menetelmää kutsutaan Monte Carlo arvioksi. “Monte Carlo” viittaa satunnaisuuteen kuuluisan uhkapelikaupungin kautta, sekä tilastotieteen yhteydessä siis toistuvaan satunnaisotantaan numeerisen tuloksen tuottamiseksi. Teoriassa tulos olisi siis myös analyyttisesti (kaavoin) toteutettavissa, mutta käytännössä se voi joskus olla vaikeaa tai mahdotonta. Tässä tapauksessamme analyyttinen tulos (F-jakauma) on jo olemassa ja R:n implementoitu, mutta simulaatio voi auttaa ymmärtämään mistä F-jakaumassa ja päättelyssä yleisemmin on kyse. Rakennetaan simulaatio toistamalla nollamallille yllä suorittamiamme laskuja haluttu määrä for-luupin avulla:
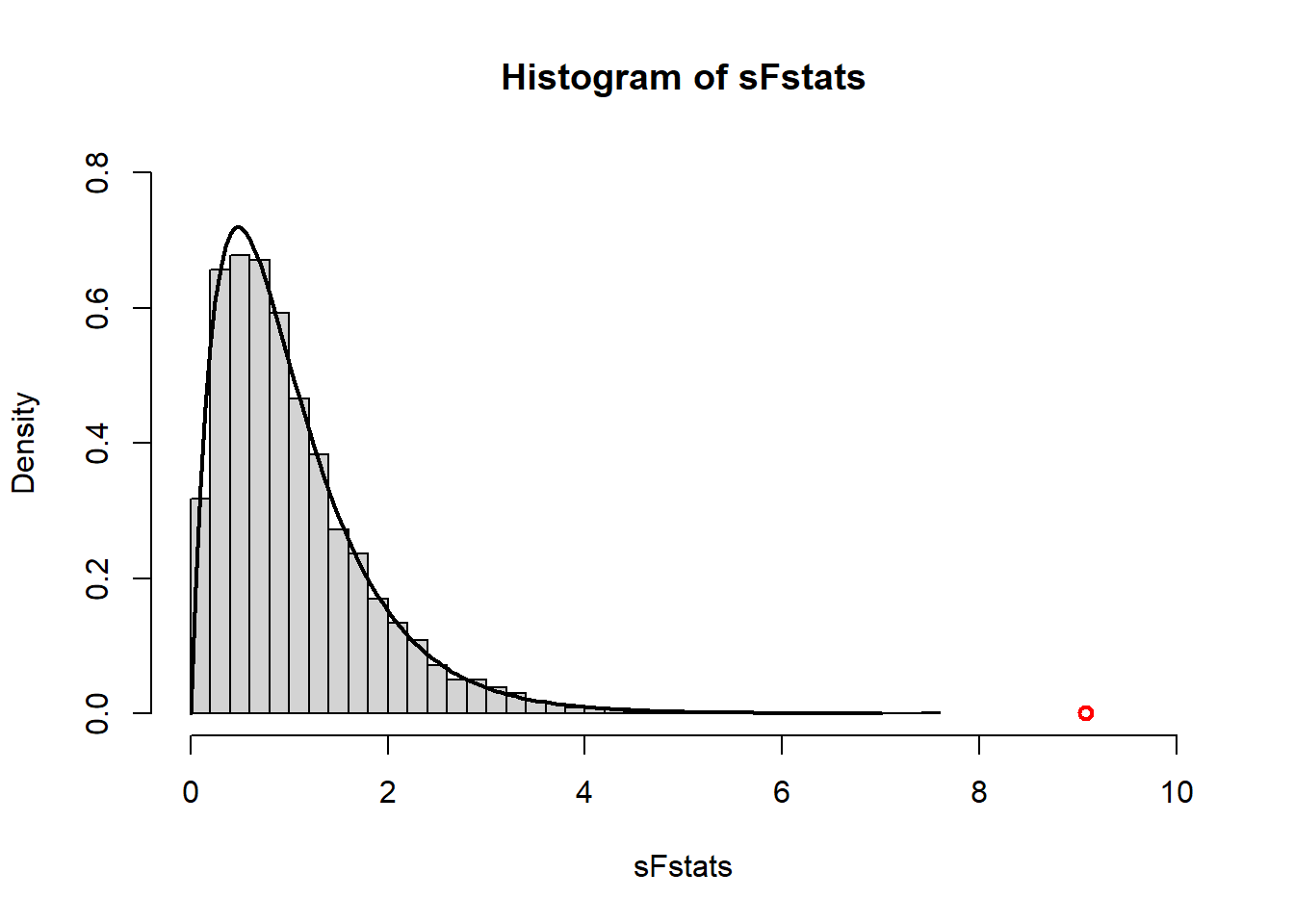
# Aiemmat parametriasetukset uudestaan:N <-nrow(howell_eysenck_data)*ncol(howell_eysenck_data) # Havaintojen lkmNpG <- N/ncol(howell_eysenck_data) # Havaintojen määrä per ryhmä (10)Ng <- N/NpG # ryhmien määrä (5)mu <-mean(unlist(howell_eysenck_data)) # kokonaisodotusarvose <-mean(sapply(howell_eysenck_data, var)) # sigma epsilontau0 <-rep(0, 5) # nollahypoteesi - ei ryhmäeroja# For-luuppi nollahypoteesille:set.seed(2026)Nr <-5000# toistojen lkmsFstats <-rep(0, Nr) # alustetaan vektori F-suureille per toistofor (i in1:Nr){ # toistetaan Nr kertaa# aiempi aineiston luonti dati <-data.frame(x = mu +rnorm(n = N, mean =0, sd =sqrt(se)) +rep(tau0, each = NpG),group =rep(names(howell_eysenck_data), each = NpG))# pivotoidaan alkuperäiseen muotoon ja lasketaan F-arvo dati <-data.frame(matrix(dati$x, NpG, N/NpG)) MSwi <-mean(sapply(dati, var)) # Mean-squares within groups MSbi <-var(sapply(dati, mean))*NpG # Mean-squares between sFstats[i] <- MSbi/MSwi # asetetaan F-suurevektoriin} # luuppi loppuu tähän# Piirretään histogrammi simulaatioista...hist(sFstats, probability =TRUE, breaks =30, xlim =c(0, 10), ylim =c(0,0.8))# ...ja sen päälle teoreettinen F-jakauma, ...lines(seq(0,7,0.05), df(seq(0,7,0.05), df1 = Ng -1, df2 = N - Ng), lwd =2)# ...sekä alkuperäinen Howellin aineiston F-arvopoints(MSb/MSw, 0, col ="red", lwd =2)
# Monte Carlo p-arvo:1-mean(sFstats <= MSb/MSw)
[1] 0
# Alkuperäinen otantateoreettinen p-arvo:1-pf(MSb/MSw, df1 =4, df2 =45)
[1] 1.81549e-05
Simuloimastamme kuvasta näemme useita asioita. Ensinnäkin, simulaatio (histogrammi) vastaa hyvin tarkasti teoreettista F-jakaumaa (viiva). Toiseksi, Howellin aineiston F-arvo (punainen ympyrä) on hyvin kaukana nollahypoteesin ennustamasta teoreettisesta jakaumasta, eli tilastollisesti hyvin merkitsevä. Kolmanneksi, toteutimme tässä otantateorian perusideaa, eli toistettua otantaa samasta jakaumasta – emme tehneet sitä äärettömän montaa kertaa, mutta riittävästi yleiskuvan saamiseksi siitä mitä tapahtuisi jatkossakin. Simuloimalla tuotettu Monte Carlo -arvio ei täysin vastaa teoreettista p-arvoa, mutta se on ymmärrettävää, koska teoreettisen ennusteen mukaan vain hyvin harva arvo ylittää havaitun F-arvon 9.0847691. Monte carlo arvio laskee toistoja, joille simuloitu arvo ylittää havaitun ja vertaa näitä kaikkien toistojen määrään. Teimme vain 5000 toistoa ja haettu tapahtuma on hyvin harvinainen, joten emme voi olettaa aina näkevämme yhtäkään tällaista tapahtumaa. Mieti kuinka suuri toistojen määrä tarvittaisiin, jotta voisimme odottaa havaitsevamme nollasta poikkeavan Monte Carlo arvion Howellin aineistolle. Voit myös kokeilla muuttaa Nr arvoa yllä varmentaaksesi arviosi, kunhan muistat sen pätevän keskimäärin [voit joutua kokeilemaan useamman kerran].
2.3 ANOVA lineaarisena mallina
Aiemmalla kurssilla näimme, että ANOVA-malli on lineaarinen regressiomalli ja näin R sitä taustalla käsittelee. Tähän taustatodellisuuteen voi kurkata malliobjektia tarkastelemalla, joka on kahta tyyppiä yhtaikaa, sekä “aov” (analysis of variance) että “lm” (linear model). Voimme myös verrata yllä olevaa ANOVA-tulostetta tavallisen lineaarimallin summary-tulosteeseen:
# regressiomallinnusfunktion (lm) tulossummaus:summary(lm(x ~factor(group), data = dat_he))
Call:
lm(formula = x ~ factor(group), data = dat_he)
Residuals:
Min 1Q Median 3Q Max
-7.00 -1.85 -0.45 2.00 9.60
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 11.0000 0.9835 11.184 1.39e-14 ***
factor(group)Counting -4.0000 1.3909 -2.876 0.00614 **
factor(group)Imagery 2.4000 1.3909 1.725 0.09130 .
factor(group)Intentional 1.0000 1.3909 0.719 0.47589
factor(group)Rhyming -4.1000 1.3909 -2.948 0.00506 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 3.11 on 45 degrees of freedom
Multiple R-squared: 0.4468, Adjusted R-squared: 0.3976
F-statistic: 9.085 on 4 and 45 DF, p-value: 1.815e-05
Näemme, että aov-objektissa piilee regressiomallin kulmakertoimet ja regressiomallin F-testi antaa tismalleen samat tulokset kuin ANOVA, vapausasteita myöten. Tämä kaikki johtuu siitä, että mallit ovat pohjimmiltaan samat. Jopa \(\eta^2\)-efektikoko tässä tapauksessa vastaa tismalleen lineaarisen mallin vastemuuttujassa selittämää varianssia (yo. \(R^2\), eli “Multiple R-squared” -arvo) ja \(\omega^2\)-efektikoko on hyvin lähelle yllä nähtyä ns. adjustoitua R-squared -arvoa:
effectsize::eta_squared(fit_he)$Eta2
For one-way between subjects designs, partial eta squared is equivalent
to eta squared. Returning eta squared.
[1] 0.4467604
effectsize::omega_squared(fit_he)$Omega2
For one-way between subjects designs, partial omega squared is
equivalent to omega squared. Returning omega squared.
[1] 0.3927549
Estimaatit eroavat siinä pyrkivätkö ne arvioimaan selitettyä varianssia aineistossa (\(\eta^2\) ja \(R^2\); nämä samat) vaiko populaatiossa (\(\omega^2\) ja adjustoitu \(R^2\); kummassakin edelleen harhaa, jälkimmäisessä enemmän, mutta myös yleistyvämpi luku). Keskustelemme luennolla aineistoon efektikoosta ja aineistoon ylisovittamisesta, mutta jatketaan tässä ymmärtämään ANOVAa lineaarisena mallina.
Alla vertaamme aov-käskylle antamaamme aineistoa ns. ennustajamuuttujamatriisiin, jota R on taustalla käyttänyt muistettujen sanojen lukumäärää mallintamaan:
# Aineiston 6 ensimmäistä riviä:head(dat_he)
# A tibble: 6 × 2
group x
<chr> <int>
1 Counting 9
2 Rhyming 7
3 Adjective 11
4 Imagery 12
5 Intentional 10
6 Counting 8
# katsotaan ennustajia ja kutsutaan niitä tyypillisesti X-matriisiksiX <-model.matrix(fit_he)# Ennustajamatriisin 6 ensimmäistä riviä:head(X)
Näemme, että faktoritaso “Adjective” puuttuu ennustajamatriisista, koska sitä edustaa vakio (Intercept). Muiden muuttujien arvo on yksi silloin, kun aineiston kyseisen rivin group-muuttujan arvo vastaa ennustajamatriisin muuttujanimen ilmoittamaa tasoa, ja muulloin se on nolla. Jokainen group-muuttujan arvo on kuitenkin pääteltävissä ennustajamatriisista. R:n formula-notaatio on siis luonut aiemmalla kurssilla kohtaamamme matemaattisen edustuksen:
missä oikein muistettujen sanojen lukumäärä \(Y\) mallinnetaan 0/1-arvoja saavien “dummy-muuttujien”, eli hoitokontrastien (treatment contrasts) avulla. Howell on kirjassaan käyttänyt symbolia \(X\) merkitsemään vastemuuttujaa, mutta yleisemmin sitä käytetään ennustajien, eli tässä ryhmittelevän muuttujan, merkitsemiseen. Tästä syystä nimesin vastemuuttujan yllä \(Y\)-symbolilla. Nyt matriisitulolle yleisesti pätee \([XY]_{ij} = [\sum_k X_{ik} Y_{kj}]_{ij}\), eli tulomatriisin \(i\)-rivin ja \(j\)-sarakkeen indeksöimä alkio on \(i\):n rivivektorin \(X_{i \cdot}\) ja \(j\):n sarakevektorin \(Y_{\cdot j}\) alkioiden summa (eli pistetulo). Koska ennustetaan vain yhtä muuttujaa (yhtä \(Y\) saraketta), R mallintaa (ennustaa) havaittua vastemuuttujaa \(y\) seuraavasti:
Tehdään nyt ylemmän rivin matriisilasku R:ssä, varmistetaan sen yhtäsuuruus alemman rivin painotettuun vektorisummaan, sekä tarkistetaan kummankin vastaavan alkuperäisen R-malliobjektin ennusteita:
Voimme ennustaa vain viisi arvoa, koska ennustematriisissa on vain 5 lineaarisesti riippumatonta riviä, mutta ennusteet vastaavat toisiaan yli laskutavan sekä vastaavat arvoiltaan lähes tismalleen alkuperäisiä Howellin aineiston ryhmäkeskiarvoja. Jos huomioimme vapausasteet, myös malliresiduaalien varianssi vastaa within-group vaihtelua ja malliennusteiden varianssi between-group vaihtelua:
Tässä kohdin lukijaa saattaa jo ihmetyttää miksi teemme samaa asiaa monella eri tavalla, eli miksi R haluaa vääntää ANOVA-laskutkin lineaariseksi regressiomalliksi. Kyllähän sellaiseen yleisestikin pedagogista arvoa liittyy, mutta taustalla vaikuttaa historia. ANOVA-mallin perinteiset laskut olivat aikoinaan suosittuja, koska ne olivat tehtävissä käsin ja tietokoneet edustivat vähintäänkin harvinaista osaamista. Yksinkertaisemmat summalaskut tuntuvat monelle myös symbolista käsittelyä, ja varsinkin matriisilaskentaa, lähestyttävämmiltä, mikä ehkä osaltaan selittää niiden pysyvää pedagogista suosiota. Toisaalta, symbolisen matriisilaskennan (ja R:n formula-notaation) yleistyvyys on aivan eri luokkaa kuin summalaskennan. Sama käyttämämme formula-notaatiosyöte tyyppiä y ~ factor(x) kävisi perus-paketin aov-funktion lisäksi syötteeksi lukuisiin eri R-paketteihin, jotka tekevät aivan muita asioita kuin varianssianalyysia, mutta joita yhdistää ennustemallintaminen jossain mielessä. Regressiomallinnus on myös luonteva tapa ymmärtää ANOVA:n laajennuksia, kuten myöhemmin kohtaamaamme ANCOVA:a ja käänteistodennäköisyyspainotusta.
2.4 Tilastollinen voima varianssianalyysissa
Oletetaan, että haluaisimme mahdollisimman pienellä vaivalla varmistaa, että Howellin tulokset pätevät myös tämän päivän psykologian opiskelijoilla. Ettei, esim. sosiaalisen median “aivomätä” ole hävittänyt muistia tukevien kokeellisten konditioiden merkitystä. Montako opiskelijaa meidän tulisi tutkia? Kysymykseen vastataan hyödyntämällä tilastollisen voiman käsitettä. Yllä (olennaisesti) simuloimme aineistoa nollahypoteesia vastaavasta F-jakaumasta, mutta voimalaskentaa varten tarvitsemme efektikoon ja sille ehdollisen vaihtoehtoista hypoteesia vastaavan jakauman. ANOVAn tapauksessa se on ns. epäkeskinen F-jakauma (non-central F-distribution). Aloitetaan efektikoosta.
Yllä laskimme \(\eta^2\)-efektikoon ja tulkitsemme sen koeryhmäjako-muuttujan selittämäksi osuudeksi vastemuuttujan kokonaisvaihtelusta. Sana “osuus” tässä viittaa siihen, että vastemuuttujan (muistettujen sanojen) kokonaisvaihtelun määrä aineistossa on normalisoitu arvoon 1. Näin ollen, selittämättä jäävän varianssin osuus on \(1 - \eta^2\). Kun tulkitsemme koeryhmäjaon kokeen “signaaliksi” ja muun yksilöiden välisen vaihtelun “kohinaksi”, ns. Cohenin \(f^2\) efektikoko mittaa signaali-kohinasuhdetta
\[
f^2 = \frac{\eta^2}{1 - \eta^2}.
\]
Yllä jo näimmekin, että sama luku saadaan lineaarisen mallin kautta, laskemalla \(f^2 = R^2/(1 - R^2)\). Muistamme, että ANOVAssa \(\eta^2 = \sigma_{\tau}^2/(\sigma_{\tau}^2 + \sigma_{\epsilon}^2)\), eli teoreettisen ryhmävaihtelun suhde kokonaisvaihteluun, jolloin \(1 - \eta^2 = \sigma_{\epsilon}^2/(\sigma_{\tau}^2 + \sigma_{\epsilon}^2)\), eli \(f^2 = \sigma_{\tau}^2/\sigma_{\epsilon}^2\) todella voidaan tulkita signaalin ja kohinan suhteena. ANOVAssa teoreettisen kiinnostuksen kohteena oleva suure voidaan siis ilmaista muodossa:
\[
\frac{\sigma_{\epsilon}^2 + \sigma_{\tau}^2}{\sigma_{\epsilon}^2} = 1 + f^2,
\] missä efektikoko voidaan tulkita testisuureen poikkeamaksi ykkösestä, eli sen odotusarvon “epäkeskisyydeksi” suhteessa nollahypoteesin odotusarvoon, joka on tasan 1 (koska \(\sigma_{\tau}^2=0\), kun \(H_0\) on voimassa).
ANOVAn käytännön laskuissa \(SS_{treat} = n_k \sum (\bar{X}_{j \cdot} - \bar{X}_{\cdot \cdot})^2\), missä termi \(\sum (\bar{X}_{j \cdot} - \bar{X}_{\cdot \cdot})^2\) sisältää \(k - 1\) (ryhmien lkm - 1) lineaarisesti riippumatonta neliöheilahdusta, joita kerrotaan ryhmäkoolla \(n_k\). Käytännössä siis summataan \(k - 1\) epäkeskistä neliöheilahdusta, joita skaalataan arvolla \(n_k\), jolloin balansoidussa tapauksessa alkuperäinen arvo kertautuu suhteessa \(n_k(k - 1) = n_k k - k = n - k\), missä \(n\) on koko aineiston koko. Tästä syystä niin sanotun vaihtoehtoisen hypoteesin epäkeskisyysparametrin \(\lambda\) suhde standardoituun absoluuttiseen efektikokoon \(f^2\) on
R vaikuttaisi hyödyntävän jälkimmäistä arviota, joka pätee hyvin suurilla ja melko suurilla arvoilla \(n\). Toisinaan kirjallisuudessa ilmoitetaan myös \(f = \sqrt{f^2}\) ANOVAn kohdalla, kuten Howellkin tekee. Tarkistakaamme nopeasti, että tämä todella vastaa Howellinkin antamaa, eri reittiä laskettua, epäkeskisyysparametrin arvoa esimerkkiaineistomme tapauksessa:
Nyt voimme laskea tilastollisen voiman, eli todennäköisyyden havaita Eysenckin löydöksen kokoinen kokoinen ilmiö uudessa otannassa frekventistisellä ANOVA-testillä, jos keräisimme vain viisi havaintoa per ryhmä alkuperäisen kymmenen sijaan:
# Nollahypoteesin 5% merkitsevyystaso, kun NpG=5, eli n = 25Fcrit_05 <-qf(1-0.05, df1 =5-1, df2 =5*5-5)# Todennäköisyys, että vaihtoehtoinen hypoteesi antaa suuremman arvon1-pf(Fcrit_05, ncp =25*f2, df1 =5-1, df2 =5*5-5)
[1] 0.9102749
Onneksi R-ohjelmassa on myös valmiita työkaluja helpompaan ja turvallisempaan voiman laskemiseen, vaikka näidenkin kanssa on syytä olla tarkkana ohjeistuksen suhteen. Lue siis huolella mikä parametri tarkoittaa mitä tarkalleen. Tutustutaan alla näihin työkaluihin tarkastamalla, että ne todella antavat saman tuloksen kuin yllä:
# Voimalasku pwr-paketin "anova-kielellä"pwr::pwr.anova.test(k =5, n =5, f =sqrt(f2)) # HUOM! n tässä per ryhmä
Balanced one-way analysis of variance power calculation
k = 5
n = 5
f = 0.8986295
sig.level = 0.05
power = 0.9102749
NOTE: n is number in each group
# Sama voimalasku lineaarisen mallin ja yleisen F-testin "kielellä"pwr::pwr.f2.test(u =5-1, v =25-5, f2 = f2)
Multiple regression power calculation
u = 4
v = 20
f2 = 0.807535
sig.level = 0.05
power = 0.9102749
Olemme siis osoittaneet, että viisi havaintoa per kokeellinen ryhmä riittäisi havaitsemaan Eysenckin tutkimuksen kokoluokan efektin yli 91:n prosentin todennäköisyydellä, eli tilastollisella voimalla ~0.91. Yllä käytetty pwr-paketti on erityisen kätevä kokeiden suunnittelussa, sillä se mahdollistaa myös tietyn voiman edellyttämän otoskoon laskemisen suoraan. Esimerkiksi, jos edellytämme voimaa 0.99, eli sallimme vain yhden sadasta kokeesta “epäonnistua”, vaatimuksen edellyttämä otoskoko lasketaan seuraavasti (tässä erityistapauksessa):
# 0.95 voiman antava otoskoko selviää määrittämällä voimaparametri n:n sijaanpwr::pwr.anova.test(k =5, power =0.99, f =sqrt(f2))
Balanced one-way analysis of variance power calculation
k = 5
n = 7.288522
f = 0.8986295
sig.level = 0.05
power = 0.99
NOTE: n is number in each group
Tuloksesta näemme, että Eysenckin efektikoko on niin poikkeuksellisen voimakas, että vain 7-8 havaintoa per koeryhmä, eli otoskoko 40, riittää havaitsemaan hyvin suurella varmuudella (99%) poikkeaako kyseisestä populaatiosta poimittu aineisto nollahypoteesista.
2.4.1 Tilastollisen voiman merkitys tulosten tulkinnassa
Tähän asiaan voi palata myöhemminkin kurssilla, mutta voiman kohdalla on yleisesti hyvä ymmärtää sen merkitys myös koesuunnittelun ulkopuolella. Kun \(\beta\) on tyypin 2 virheen todennäköisyys, tilastollinen voima, \(1 - \beta\) on olennaisesti yhteydessä siihen kuinka tehdyn kokeen tulisi vaikuttaa uskomuksiimme. Nimittäin \(1 - \beta = P(S|T)\), eli todennäköisyys, jolla testi on merkitsevä (tapahtuma \(S\), eli significant), kun vaihtoehtoinen hypoteesi on totta (tapahtuma \(T\)) [muista myös, että tyypin 1 virhe on \(\alpha = P(S|F)\), eli löydöksen tn., kun vaihtoehtoinen hypoteesi on epätosi/FALSE].
Nyt voiman ja tehdyn kokeen evidenssiarvon suhde on seuraava. Jos koetta edeltävä prioriuskomuksemme on, että vaihtoehtoinen hypoteesi voisi olla totta noin todennköisyydellä \(P(T)\) (jolloin nollahypoteesin tn. on \(P(F) = 1 - P(T)\)) ja tilastollinen testi tuottaa merkitsevän tuloksen (tapahtuma \(S\) sattuu), niin Bayes-kaavan nojalla posterioritodennäköisyys vaihtoehtoiselle hypoteesille on
\[
\begin{array}{rl}
P(T|S) &= \frac{P(S|T)P(T)}{P(S|T)P(T) + P(S|F)P(F)} \\
&= \frac{(1 - \beta)P(T)}{(1 - \beta)P(T) + \alpha P(F)} \\
&= \frac{(1 - \beta)P(T)}{(1 - \beta)P(T) + \alpha P(F)} \times \frac{\frac{1}{P(F)}}{\frac{1}{P(F)}} \\
&= \frac{(1 - \beta)R}{(1 - \beta)R + \alpha},
\end{array}
\] missä \(R = P(T)/P(F)\) on tutkimusta edeltä vetosuhde vaihtoehtoiselle vs. nollahypoteesille. Esimerkiksi, jos olemme alun perin vain 20-80 suhteessa vaihtoehtoisen hypoteesin kannalla ja kuulemme matalavoimaisen (esim. \(1 - \beta = 0.2\)) kokeen hylänneen nollahypoteesin, subjektiivisen uskomuksemme vaihtoehtoisen hypoteesin todennäköisyydestä tulisi edelleen olla vain:
voima <-0.2# tutkimuksen oletettu (huono) tilastollinen voimaR <-20/80# pre-tutkimus vetosuhde 20-80merkitsevyystaso <-0.05# tyypillinen tilastollisen testin merkitsevyystaso# post-tutkimus uskomus H1:n todennäköisyydestävoima*R/(voima*R + merkitsevyystaso)
[1] 0.5
Toisin sanoen, vaikka tilastollinen testi sattui hylkäämään nollahypoteesin, se on siitä huolimatta yhtä mahdollinen kuin vaihtoehtoinenkin hypoteesi. Tämä johtuu siitä, että vaikka \(P(S|F) = 0.05\) on pieni, myös \(P(S|T) = 0.2\) on varsin pieni, eli kumpikaan mahdollisista todellisuuksista ei anna järin suurta todennäköisyyttä tilastollisesti merkitsevälle löydökselle. Kun sitten ehdollistamme tapahtumalle, että merkitsevä löydös tuli, löydös voi lähes yhtä hyvin tulla kummastakin todellisuudesta. Jos pitäisimme vaihtoehtoista hypoteesia yhtä uskottavana kuin nollahypoteesi (\(R = 1\)), koe nostaisi sen todennäköisemmäksi kuin nollahypoteesin (voima/(voima + merkitsevyystaso) = 0.8). Koe ei kuitenkaan välttämättä riitä muuttamaan alkujaan yllättävämpää tulosta todennäköiseksi todellisuuden tulkinnaksi, vaikka näin tutkimuksissa usein väitetäänkin.
Tilastollisen voiman käsite ei siis liity vain koesuunnitteluun, kuten joskus väitetään, vaan kriittisesti myös jo julkaistujen tulosten tulkintaan. Tässä on kuitenkin tärkeää olla nojaamatta voima-arviotaan saman tutkimuksen havaittuun efektikokoon, jota tulkitsee; se on otoksen kohinainen realisoitunut arvo, eikä estimoitava populaatioarvo. Yllä selvittämäämme \(P(T|S)\)-suuretta kutsutaan tutkimuksen posteriori-prediktiiviseksi arvoksi (PPV; posterior predictive value), eikä sitä tyypillisesti voi laskea yhden kokeen aineistosta, tai ylipäätään kovin tarkasti. PPV:n selvittäminen edellyttää yhden aineiston ylittäviä arvioita. Arviot voivat silti olla hyvinkin informatiivisia. PPV:n avulla voimme nähdä, että (1) heikkolaatuisin kokein testatut epäuskottavat teoriat ovat edelleen epäuskottavia ja, että (2) epäuskottavan tai yllättävän hypoteesin todistaminen edellyttää suurempaa tilastollista voimaa kuin konservatiivisemman hypoteesin.
Balansoitu 1-suuntainen ANOVA on tavallinen lineaarinen regressiomalli
Efektikoko (signaali-kohina-suhde) vaikuttaa tilastolliseen voimaan, eli merkitsevän löydöksen todennäköisyyteen
Myös otoskoko vaikuttaa tilastolliseen voimaan
Tutkimuksen tilastollinen voima ja tutkimusta edeltävät uskomukset vaikuttavat tutkimuksen posteriori-prediktiiviseen arvoon (PPV), eli vaihtoehtoisen hypoteesin posterioritodennäköisyyteen ehdolla, että tutkimuksesta saatiin tilastollisesti merkitsevä löydös
Posterioritodennäköisyys viittaa tutkimuksen jälkeiseen uskomukseen, mitä ei voi laskea ilman tutkimusta edeltävää prioritodennäköisyyttä (eli laskeminen edellyttä ns. Bayes-päättelyä)
Merkitsevä tilastollinen testi kertoo, että aineisto on epäuskottava nollahypoteesin pätiessä, mutta vasta PPV kertoo onko vaihtoehtoinen hypoteesi uskottava nollahypoteesi hylättäessä.