5 OSA 5: Yleistetty regressio ja uskottavuusfunktio
Lue ensin Howellin usean selittäjän regressiota (Multiple regression) käsittelevä kappale. Sen jälkeen voit lukea tätä verkkotekstiä tai tehdä muita viikon kurssisuorituksia. Tässä tektistä käytämme Howellin niukahkosti esittelemää logistista regressiomallia ponnahduslautana yleistettyihin regressiomalleihin tutustumiseen. Lisäksi tutustumme hieman kirjaa syvällisemmin logistiseen regressiomalliin. Howellkin totesi, että “In the past few years the technique of logistic regression has become popular in the psychological literature. (It has been popular in the medical and epidemiological literature for much longer.)”. Kliiniset psykologit usein kohtaavat lääketieteellistä ja epidemiologista kirjallisuutta kokeellisesti orientoituneita psykologeja enemmän. Kliinisen psykologian kannalta logistisen regression menetelmä ei ole hiljattainen kuriositeetti, vaan se on tunnettava ja ymmärrettävä.
Huomaa, että yleistetty lineaarinen regressiomalli (generalized linear regression model) on eri asia kuin seuraavalla viikolla esiteltävä yleinen lineaarinen malli (general linear model). On ehkä vähän historiallinen vahinko, että termit osuivat niin lähelle toisiaan, vaikka viittaavat hyvin eri asiaan. Näin nyt kuitenkin on ja varsinkin termi yleistetty regressio on syytä tuntea, joskaan sitä ei nyt tässä tarvitse vielä kovin syvällisesti ymmärtää. Sana “yleistetty” viittaa tässä mallinnustekniikkaan, joka yleistää tavallisen lineaarisen regression useille erilaisille vastemuuttujille, eli monin eri tavoin jakautuneille riippuville muuttujille. Logistinen regressio, johon tässä esimerkin mielessä tutustutaan, yleistää regressiomallin kaksiluokkaiselle (esim. kyllä/ei) vastemuuttujalle. Muita mahdollisuuksia olisivat esimerkiksi lukumäärämuuttujat (Poisson regressio) ja järjestysluokkamuuttujat (proportional odds regression). Lisäksi on olemassa lukuisia käsitteellisesti likeisiä regressiomalleja (mm. proportional hazards ja tobit regressiot), joiden myöhemmässä ymmärtämisessä yleistetyn regressiomallin logiikan ymmärtäminen auttaa. Syvennetään siis hieman Howellin tekstiä näiltä osin, kuitenkin logistiseen regressiomalliin esimerkkinä nojaten.
5.1 Yleistetty regressio ja logistinen regressio
Yleistetty regressiomalli koostuu kolmesta keskeisestä komponentista:
- Tietty parametrinen jakauma vastemuuttujalle \(Y\).
- Yleistetyista regressiomalleista puhuttaessa jakauman on kuuluttava ns. eksponentiaaliseen jakaumaperheeseen, mutta nämä yksityiskohdat ohitetaan tässä.
- Lineaarinen ennustinfunktio: \(\eta = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \cdots + \beta_p X_p\).
- Tämä vastaa tavallista regressiomallia, mutta jatkuva-arvoinen residuaali puuttuu.
- Linkkifunktio \(g\) siten, että \(E[Y|X] = \mu = g^{-1}(\eta)\). Eli \(g(E[Y|X]) = \eta\)
- Toisin sanoen, funktio \(g^{-1}\) kytkee lineaarisen ennustinfunktion vastemuuttujan selittäjille ehdolliseen odotusarvoon.
Koska Logistisen regression kohdalla vastemuuttuja saa vain arvoja 0 (esim. jokin asia “ei tapahtunut”) ja 1 (asia “tapahtui”), sen odotusarvon ja keskiarvon on siis oltava näiden lukujen välissä, eli aina pätee \(0 \le E[Y|X] \le 1\). Jos käytämme tavallista lineaarista mallia, ei ole takeita, ettei ennustinfunktio \(\eta\) poistuisi tältä väliltä joillekin havaintoyksiköille. Jos sen sijaan asetamme,
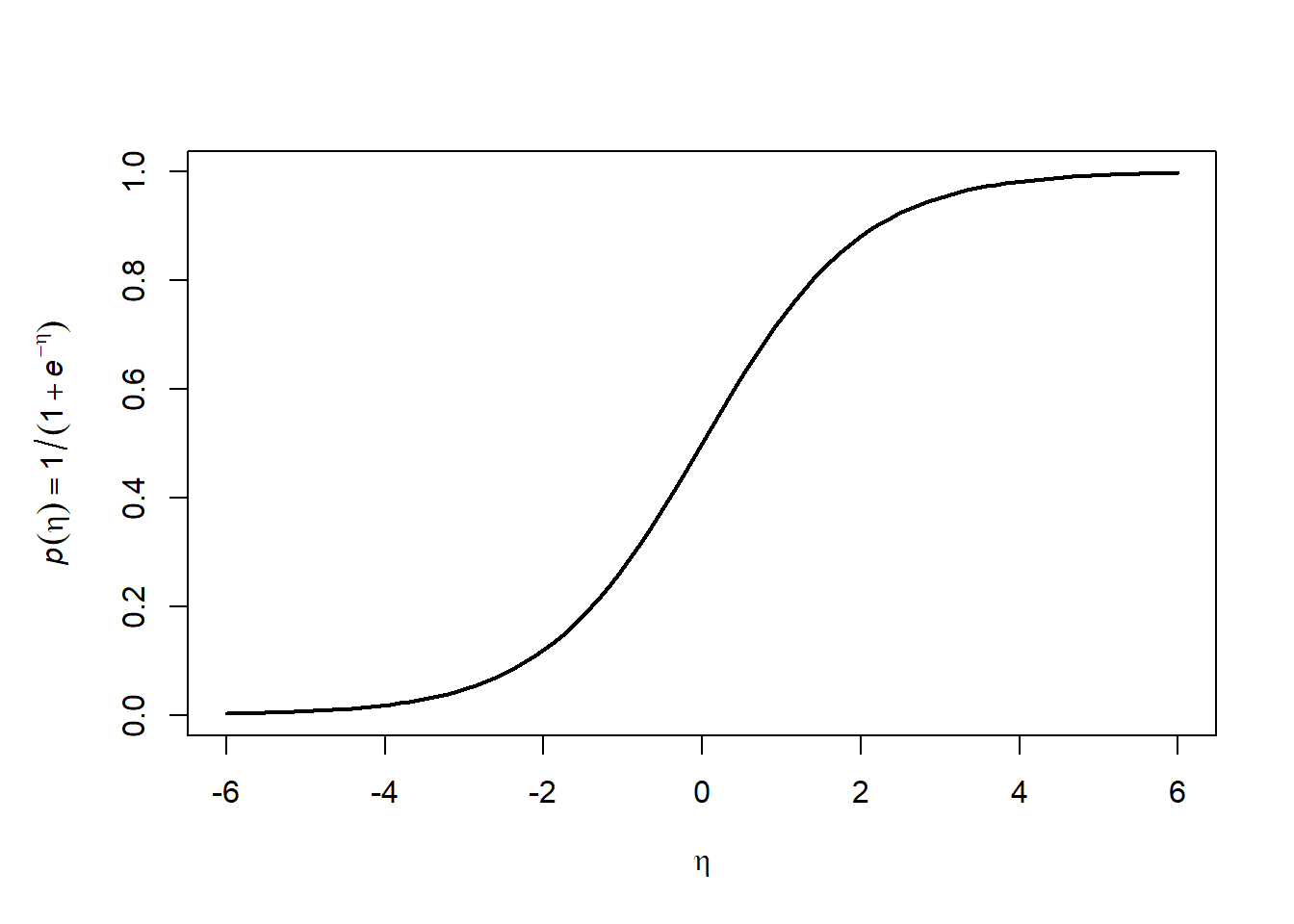
\[ g^{-1}(\eta) = \frac{1}{1 + e^{-\eta}}, \]
pysyy tämä monotonisesti muunnettu ennuste aina halutulla välillä \([0, 1]\). Katsotaan miltä funktio näyttää:
Yllä merkitsimmekin y-akselin nimessä tätä ns. logistista funktiota symbolilla \(p\), koska se kuvaa arvoja välille nollasta yhteen, eli todennäköisyyksiksi. Tämän funktion käänteisfunktio taas kuvaa välin \([0, 1]\) välille \([-\infty, \infty]\) ja on muotoa:
\[ g(p) = \log(\frac{p}{1-p}) \]
Logaritmin sisällä on ns. vetokerroin, eli odds (tapahtuman todennäköisyyden suhde vastatapahtuman todennäköisyyteen). Yllä olevista määritelmistä seuraa, että (tietyt arvot \(X = x\) havaittuamme)
\[ \log(\frac{p}{1-p}) = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \cdots + \beta_p x_p. \]
Korottamalla luonnolliseen eksponenttiin, edellisen nähdään olevan yhtä kuin
\[ \frac{p}{1-p} = e^{\beta_0 + \beta_1 x_1 + \beta_2 x_2 + \cdots + \beta_p x_p}. \]
Toisin sanoen, lineaarisen ennusteen eksponenttifunktio on vetokertoimen ennuste. Tästä käsin on havainnollista tulkita logistisia regressiokertoimia ja katsoa mitä tapahtuu, jos esimerkiksi ensimmäisen selittäjän arvoa kasvatetaan yhdellä yksiköllä, arvoon \(x_1 + 1\). Koska eksponenttifunktio muuttaa summat tuloiksi, saadaan
\[ e^{\beta_0 + \beta_1 (x_1 + 1) + \beta_2 x_2 + \cdots + \beta_p x_p} = e^{\beta_1} e^{\beta_0 + \beta_1 x_1 + \beta_2 x_2 + \cdots + \beta_p x_p}. \]
Kulmakertoimen \(e^{\beta_1}\) tulkinta on siis, että yksi selittävän muuttujan yksikkö keskimäärin muuntuu \(e^{\beta_1}\)-kertaiseksi vetokertoimeksi päätetapahtumalle, jos muut selittävät tekijät pidetään vakiona (adjustoidaan). Toisin sanoan, \(e^{\beta_1}\) on vetosuhde (odds ratio, OR), kun verrataan esimerkiksi henkilöitä, joille \(x_1 = 1\) henkilöihin, joille \(x_1 = 0\).1
Esimerkiksi, jos päätemuuttuja on keuhkosyöpä 80:n ikävuoteen mennessä ja selittävä tekijä \(x_1\) on tupakointi, kulmakerroin voisi olla \(\beta_1 = 3.2\), mikä tarkoittaisi, että tupakoijien keuhkosyövän vetosuhde on \(e^{3.2} \approx 25\) suhteessa tupakoimattomiin. Jos olemme estimoineet lisäksi esimerkiksi vakion \(\beta_0 = - 4.6\), voimme myös ennustaa keuhkosyövän odotusarvon tupakoitsijoille ja tupakoimattomille ottamalla regressioyhtälöstä logistisen funtion, \[ E[Y|X=1] = g^{-1}(-4.6 + 3.2 \times 1) = 1/(1+e^{-(-4.6 + 3.2)}) \approx 0.20 \]
(yo. siis tupakoijille) ja \(g^{-1}(-4.6 + 3.2 \times 0) = 1/(1+e^{4.6}) \approx 0.01\) (tupakoimattomat). Tällöin keuhkosyövän vetosuhde on \(\frac{0.2}{1-0.2}/ \frac{0.01}{1-0.01} \approx 25\) ja siis tupakoijien keuhkosyövän vetokerroin 25-kertainen tupakoimattomiin nähden. Toisinaan raportoidaan myös riskisuhteita (tässä \(0.2/0.01 = 20\)), mutta alun vieraudestaan huolimatta, vetosuhteet osoittautuvat tilastollisen analyysin kannalta mielekkäämmiksi ja vertailukelpoisemmiksi suureiksi (matalan riskin tapahtumille suureet ovat lähellä toisiaan).
Keuhkosyövän saamisen ohella voisimme olla kiinnostuneita monista välineellisemmistäkin “tapahtumiksi” luokitelluista asioista ja niiden todennäköisyyksistä. Voimme mm. ennustaa logistisella regressiolla johonkin tutkimukseen suostumista ja siten mallintaa aineiston valikoitumisen todennäköisyyttä. Tällöin saisimme OSAssa 1 hyödynnetyt käänteistodennäköisyyspainot laskettua logistisen regressiomallin ennusteista. Tällaista ennustetta kutsutaan usein myös propensiteettipisteeksi (propensity score) ja se näyttelee tärkeää roolia erilaisissa syy-seurauspäättelyn menetelmissä.
5.2 Uskottavuusfunktio
Yllä kuvasimme kuinka logistinen regressiomalli antaa meidän laskea ennusteen \(P(Y = y|X=x; \beta)\), eli tietyn kaksiluokkaisen tapahtuman \(\{Y = y\}\) todennäköisyyden, ehdollisena (mahdollisesti vektoriarvoisille) selittäjän arvoille \(X=x\), ja tietysti regressiokerroinestimaatille \(\beta\). Jos meillä on otos riippumattomia havaintoja (\(n\) kpl), esimerkiksi toisistaan riippumattomia poimintoja väestöstä (henkilöitä), todennäköisyys havaita näille päätemuuttujan arvot \(Y_1 = y_1, Y_2 = y_2, \ldots, Y_n = y_n\), saa nyt siis seuraavan ennusteen:
\[ \begin{array}{ll} P(Y_1 = y_1|X_1=x_1; \beta) \times P(Y_2 = y_2|X_1=x_1; \beta) \times \cdots \times P(Y_n = y_n|X_1=x_n; \beta) \\ = \prod_{i=1}^n P(Y_i = y_i|X_i=x_i; \beta) \\ =: \mathcal{L}(\beta; X, Y) \\ =: \mathcal{L}(\beta). \end{array} \]
Eli usean riippumattoman tapahtuman todennäköisyys on yksittäisten tapahtumien (havaintojen) todennäköisyyden tulo, kuten olemme aiemmin oppineet. Kun kiinnitetään tietty aineisto ja ajatellaan tätä tuloa parametrien \(\beta\) funktiona, sitä usein merkitään symbolilla \(\mathcal{L}(\beta; X, Y)\), tai lyhyesti \(\mathcal{L}(\beta)\), ja kutsutaan uskottavuusfunktioksi. Samankaltainen funktio voidaan muodostaa muillekin linkkifunktioille \(g\) ja siis myös muille yleistetyille lineaarisille malleilla, ja yleisemminkin tilastollisille malleille. Mahdollisiin malleihin sisältyy toki tavallinen regressiomalli, joka sekin on vain yksi tämän laajemman näkökulman erityistapaus.
Malli on sitä “uskottavampi”, mitä suuremman todennäköisyyden se antaa havaitulle aineistolle. Jos rajoitamme parametria \(\beta\) jotenkin ja saamme näin nollahypoteesimallin uskottavuuden \(\mathcal{L}_0(\beta)\), voimme verrata kahden (sisäkkäisen) mallin uskottavuuksia ns. uskottavuusosamäärällä:
\[ \mathcal{L}(\beta) / \mathcal{L}_0(\beta). \]
Kun olemme kiinnittäneet parametrin arvot estimoimalla suurimman uskottavuuden pisteisiinsä, tämän termin logaritmi (kertaa kaksi), eli suure \(2(\log(\mathcal{L}(\hat{\beta})) - \log(\mathcal{L}_0(\hat{\beta})))\), on \(\chi^2\)-jakautunut suurilla otoksilla. Sitä voidaan käyttää hyvin monenlaisten erilaisten mallien vertailuun tilastollisessa testissä. Uskottavuusosamäärä-suuretta voidaan siis hyödyntää monenlaisten nollahypoteesien tilastollisessa testaamisessa. Näitä testejä kutsutaan mm. uskottavuusosamäärä-testeiksi (uskottavuusfunktiosta saadaan muitakin testejä).
Tilastollisia malleja myös tyypillisesti estimoidaan maksimoimalla uskottavuusfunktio ja tähän Howellkin viittaa “iteratiivisilla” ratkaisuillaan. Usein ratkaisua ei nimittäin löydy suljetussa analyyttisessa (kaava)muodossa, vaan se joudutaan “etsimään” numeerisesti kokeilemalla. Tämä ei ole summittaista kokeilua, vaan tehtävään löytyy hyvin tehokkaita algoritmeja, jotka logistisen regression kaltaisissa yksinkertaisissa tapauksissa vaivatta löytävät oikean ratkaisun. Käytännössä nämä algoritmit siis etsivät log-uskottavuusfunktion huippukohtaa, joka yleensä on sitä selvempi ja huipukkaampi mitä enemmän aineistoa on käytettävissä. Log-uskottavuusfunktio siis liittyy olennaisella tavalla aineiston mallista tarjoaman informaation määrään. Toisinaan malleja verrataankin esimerkiksi suoraan siitä laskettavan Akaiken informaatiokriteerin (AIC, Akaike Information Criterion) kautta, joka määritellään laskemalla estimoidulle mallille arvo:
\[ 2k - 2 \log(\mathcal{L}(\hat{\beta})), \]
missä \(k\) on mallin parametrien lukumäärä. Tässä siis pienempi AIC-arvo tarkoittaa uskottavampaa mallia, mutta uskottavuusfunktion ollessa vakio, suurempi parametrien määrä heikentää uskottavuutta (kasvattaa kriteeriä). Tilastollisten testien lailla, AIC siis huomioi kuinka aineistosta kiinnitetyt vapausasteet vähentävät sen todistusvoimaa. Informaatiokriteereitä on useita, muttemme mene niihin tämän pidemmin tässä tekstissä. Tarvittaessa näistä asioista löytyy runsaasti lisätietoa, alkaen kattavista Wikipedia-sivuista.
5.3 Regressiomallinnus käytännössä
Yleistetyt regressiomallit ovat erittäin paljon käytetty työkalu päivittäisessä määrällisessä tutkimustoiminnassa. Aiemmasta kurssimateriaalista joku voisi ehkä vielä miettiä, ettei ANOVAa tarvitse nähdä regressiomallina, jos ne ovat sama asia. ANOVA ei kuitenkaan yleisty kaksiluokkaisille muuttujille ja olisi varsin erikoinen malli, jos meillä on tiedossa esim. vain saiko henkilö syöpää vai ei. Edes ANOVAn “ei-parametriset” vaihtoehdot, kuten Kruskall-Wallis-testi, eivät ole erityisen järkeviä tässä tapauksessa. Mutta logistinen regressio on ja se yleistää ANOVAa ja tavallista regressiota koskevat intuitiomme uuteen tarpeeseen. Ja muut yleistetyt regressiomallit vastaavasti moneen muuhun tilanteeseen. Katsotaan tätä nyt lyhyesti käytännössä. Simuloidaan aineistoa lineaariselle mallille ja viedään se kaksiluokkaiseen tilanteeseen:
set.seed(321)
n <- 200 # otoskoko
x <- rnorm(n) # selittäjä
beta0 <- 0.5 # vakio
beta1 <- 0.5 # kulmakerroin
y <- beta0 + beta1*x + rnorm(n) # jatkuva vastemuuttuja
py <- 1/(1 + exp(-(beta0 + beta1*x))) # kaksiluokkaisen vasteen odotusarvo
yobs <- (runif(n) <= py)*1 # kaksiluokkainen vaste
# Piirretään kuvaan
par(mfrow=c(1,3))
plot(x, y) # jatkuvat muuttujat
plot(x, yobs) # jatkuva selittäjä, kaksiluokkainen vaste (alla sama boxplottina)
boxplot(list(x[yobs==0], x[yobs==1]), names = c("Ei Y:tä", "Y sattui"), ylab = "x")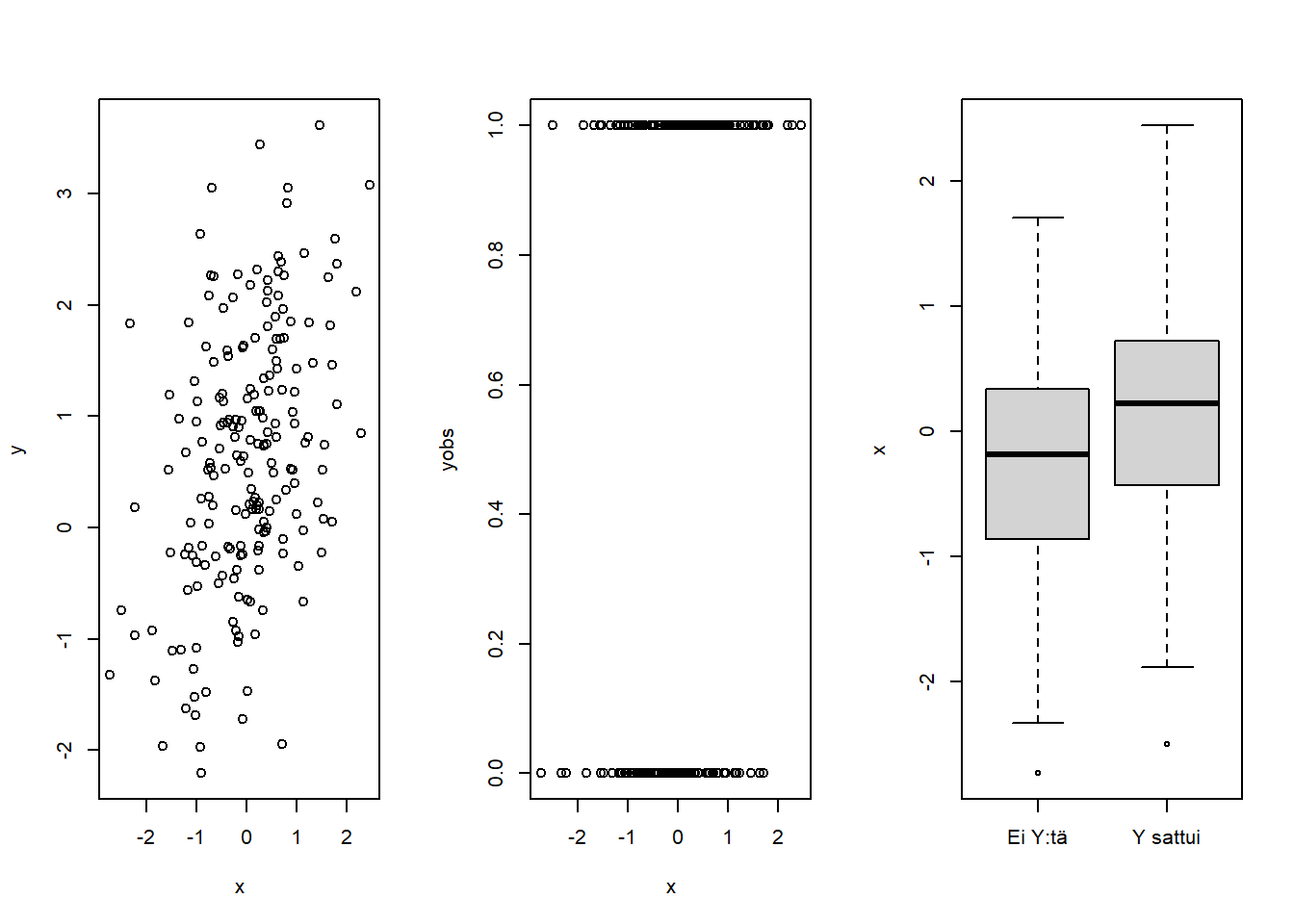
Yllä olevasta kuvasta näemme tavallisen regressiomallinnustilanteen (vasen paneeli) ja voimme verrata tilannetta kaksiluokkaiseen vastemuuttujaan (keskipaneeli). Y-muuttujaa ei jälkimmäisessä tilanteessa selvästikään ole järkevää ajatella jatkuva-arvoisena, saati normaalisti jakautuneena. Voisimme tietysti tarkastella selittävän X-muuttujan jakaumien eroja erilaisen vasteen saaneiden ryhmissä (oikea paneeli), ja tehdä esimerkiksi t-testin. Vaikka tällainen lähestyminen periaatteessa yleistyisikin myös usean selittävän tekijän tapaukseen, se ei tuottaisi regressioennusteita vastemuuttujalle ja niihin liittyvä tärkeä tulkinnallinen näkökulma jäisi puuttumaan.
Katsotaan lopuksi muutama minimaalinen esimerkki siitä, kuinka voimme usean muuttujan tapauksessa suorittaa regressiomallinnuksesta ja ANOVA-kontekstista tuttuja testejä logistisen regressiomallinnuksen tapauksessa. Alla siis luomme aineiston, jossa on kaksi jatkuva-arvoista selittävää muuttujaa ja yksi kaksiluokkainen selitettävä muuttuja. Aiemmasta tiedämme, että selittävät muuttujat voisivat yhtä hyvin olla dummy-koodattuja luokkamuuttujia. Sen jälkeen katsomme esimerkit siitä kuinka testejä voi suorittaa malleja vertaamalla tai lineaaristen hypoteesien kautta:
set.seed(2026)
n <- 300 # otoskoko
x <- rnorm(n) # selittäjä
z <- rnorm(n) # toinen selittäjä
y <- 0.5 + 0.5*x + z
py <- 1/(1 + exp(-y)) # kaksiluokkaisen vasteen odotusarvo
yobs <- (runif(n) <= py)*1 # kaksiluokkainen vaste
# Testataan tarvitaanko toista muuttujaa malleja vertaamalla
fitH0 <- glm(yobs ~ x, family = "binomial") # logistinen regressio (H0)
fitH1 <- glm(yobs ~ x + z, family = "binomial") # H1-malli
anova(fitH0, fitH1, test = "Chisq") # verrataan malleja ja siis hypoteesejaAnalysis of Deviance Table
Model 1: yobs ~ x
Model 2: yobs ~ x + z
Resid. Df Resid. Dev Df Deviance Pr(>Chi)
1 298 375.30
2 297 306.65 1 68.647 < 2.2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1# Testataan kulmakerrointen yhtäsuuruutta malleja vertaamalla
x2 <- x + z
fitH0 <- glm(yobs ~ x2, family = "binomial")
anova(fitH0, fitH1, test = "Chisq")Analysis of Deviance Table
Model 1: yobs ~ x2
Model 2: yobs ~ x + z
Resid. Df Resid. Dev Df Deviance Pr(>Chi)
1 298 312.76
2 297 306.65 1 6.1112 0.01343 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1# Sama yleisemän rajoitetun estimoinnin kautta (restriktor-paketti asennettava)
rajoitteet <- "x == z" # lineaarinen hypoteesi (voi olla useampiakin)
fitH0 <- restriktor::restriktor(fitH1, constraints = rajoitteet)
restriktor::conTest(fitH0, test = "LRT")
Restriktor: restricted hypothesis tests:
classical test: H0: all restrictions are active (==)
vs. HA: at least one equality restriction is violated
F-test statistic p-value
5.9290 0.0155
(all rows are active restrictions under H0, H1 is unrestricted!)
(Intercept) x z op rhs active
1: 0 1 -1 == 0 yes
restricted estimate under H0:
(Intercept) x z
0.57455 0.90361 0.90361
unrestricted estimate:
(Intercept) x z
0.57345 0.62734 1.15342 5.4 Yhteenveto
- Yleistetyt lineaariset regressiomallit yleistävät lineaarisen regressiomallin sellaisillekin selitettäville vastemuuttujille, jotka eivät jakaudu jatkuva-arvoisesti.
- Uskottavuusfunktio kertoo mallin ja sen parametrien arvojen uskottavuudesta saadun aineiston valossa.
- Uskottavuusfunktiosta voidaan johtaa lukuisia tilastollisia testejä ja informaatiokriteereitä. Näitä ovat mm. uskottavuusosamäärätesti (likelihood-ratio test) ja Akaiken informaatiokriteeri (Akaike Information Criterion).
- Logistinen regressiomalli on yleistetty regressiomalli, joka yleistää kurssin aiempien osien mallinnuksen kaksiluokkaisille vastemuuttujille.
- Eksponenttifunktion arvo mallin kulmakertoimista tulkitaan vetosuhteeksi (odds ratio, OR), joka on yleisesti kliinisissä tutkimuksissa raportoitu suure ja siis hyvä ymmärtää perin pohjin.
5.5 Alaviitteet
Jos \(p_1\) on tapahtuman todennäköisyys, kun \(x_1 = 1\), ja \(p_0\) todennäköisyys tilanteessa \(x_0 = 0\), vetosuhde (odds ratio) on siis \((\frac{p_1}{1 - p_1}) / (\frac{p_0}{1 - p_0})\).↩︎