[Yleistä]
[Luottamusväli ja luottamustaso]
[Otoksen ja perusjoukon suuruuden merkitys]
[Kalvot]
Tilastollinen päättely
Määrällisen
aineiston analyysissä tehdään usein ero kuvailevan tilastoanalyysin ja
tilastollisen päättelyn välillä. Kuvaileva tilastoanalyysi (descriptive
statistics) pyrkii nimensä mukaan kuvailemaan ja tiivistämään jonkin
määrällisen muuttujan jakaumaa tai useamman määrällisen muuttujan
yhteisvaihtelua pyrkimättä kuitenkaan tekemään tulosten pohjalta yleistyksiä
mihinkään laajempaan perusjoukkoon. Jos kohteena on vain yksi muuttuja voidaan
kuvailuun käyttää esimerkiksi muuttujien »keskilukuja
tai »hajontalukuja.
Useamman muuttujan tapauksessa voidaan käyttää esimerkiksi »korrelaatiokertoimia
kuvaamaan niiden yhteisvaihtelua.
Otantaan
perustuvissa yhteiskuntatieteellisissä tutkimuksissa ei kuitenkaan olla
varsinaisesti kiinnostuneita otoksesta vaan sen perusjoukon ominaisuuksista.
Tällöin tarvitaan tilastollista päättelyä (inferential statistics).
Tilastollisen päättelyn avulla voidaan arvioida kuinka hyvin otoksesta saadut
tulokset pitävät paikkansa perusjoukossa. Kyse on siis siitä, kuinka todennäköisesti
otoksen avulla saadut tulokset voidaan yleistää koko perusjoukkoa koskeviksi
tuloksiksi.
Kuvitellaan
esimerkiksi tilanne, jossa kyselytutkimuksen avulla pyritään kartoittamaan
suomalaisten mielipiteitä siitä, pitäisikö Suomen liittyä Natoon. Otoksessa 40%
naisista ja 50% miehistä vastasi myöntävästi kysymykseen Suomen
Nato-jäsenyydestä. Varsinainen tutkimuksen mielenkiinto ei kuitenkaan ole
otoksessa, vaan pyrkimys on selvittää mahdollisimman luotettavasti, kuinka
suuri osuus perusjoukon (eli kaikki täysikäiset suomalaiset) naisista ja
miehistä kannattaa jäsenyyttä. Tällöin keskeiseksi kysymykseksi nousee, mitä
näiden otostulosten avulla voidaan päätellä yleensä Suomen naisista ja
miehistä. Eroavatko miehet ja naiset perusjoukossa todella mielipiteiltään vai
onko kyse vain satunnaisista otannan mukanaan tuomasta eroista? Tilastollinen
päättely vastaa tällaisiin kysymyksiin.
Luottamusväli
ja luottamustaso
Tilastollisen
päättelyn kaksi keskeistä käsitettä ovat luottamusväli ja luottamustaso. Luottamusväli (confidence interval) kertoo
millä välillä todellinen perusjoukon tunnusluvun arvo on tietyllä
todennäköisyydellä. Käyttäen edelleen Nato-kyselyä esimerkkinä, voidaan kuvitella,
että otoksessa 45% kaikista vastaajista ilmoitti kannattavansa Suomen
Nato-jäsenyyttä. Koska tähän lukuun vaikuttavat monet satunnaiset tekijät, emme
voi suoraan päätellä, että myös perusjoukossa (kaikki täysi-ikäiset
suomalaiset) vastaava osuus on täysin sama. On kuitenkin todennäköistä, että
perusjoukon mielipidettä kuvaava arvo on lähellä otoksesta saatua arvoa. Voimme
esimerkiksi päätellä, että 95 %:n todennäköisyydellä Nato-jäsenyyttä
kannattavien ihmisten osuus perusjoukossa on välillä 40-50 %. Tätä väliä
kutsutaan luottamusväliksi.
Luottamustaso (confidence level) kertoo, millä
todennäköisyydellä perusjoukkoa kuvaava tunnusluku on jollain tietyllä
luottamusvälillä. Esimerkiksi 95 %:n todennäköisyydellä 40-50 % suomalaisista
haluaa Suomen liittyvän Natoon. Luottamustaso on tällöin 95 % todennäköisyys.
Luottamustaso ja
luottamusväli ovat siis täysin toisiinsa sitoutuneita käsitteitä. Tieto
luottamusvälistä ei ole mielekäs, jos ei ole tietoa luottamustasosta ja
päinvastoin. Olennaista on, että luottamustason kasvaessa laajenee myös
luottamusväli. Toisin sanoen tämä tarkoittaa siis sitä, että mitä suuremmalla
varmuudella haluamme tietää, millä välillä jokin perusjoukon tunnusluku
sijaitsee, sitä suurempi on luottamusväli. Jos esimerkiksi haluaisimme tietää,
millä välillä suomalaisten Nato-jäsenyyden kannatus on 99 % luottamustasolla,
luottamusväli olisi suurempi kuin 95 % prosentin luottamustasolla (esimerkiksi
30-60 %). Jos olisimme valmiita tyytymään esimerkiksi 90 % luottamustasoon,
väli voisi olla 43-47 %.
Otantajakauma
Luottamusvälin ja
luottamustason ymmärtämiseksi ja laskemiseksi tarvitaan otantajakauman (sampling
distribution) käsitettä. Otantajakauma on helpointa kuvailla esimerkin avulla.
Kuvitellaan, että edellä esimerkkinä käytetty Nato-kysely on tehty käyttäen
1000 hengen satunnaistotosta (katso »otantamenetelmät). Tämän otoksen vastaajista 45 % kannattaa
Suomen Nato-jäsenyyttä. Koska tiedetään, että otokseen valintaan vaikuttavat
satunnaiset tekijät, on luultavaa, että jos sama tutkimus tehtäisiin uudelleen
käyttäen jälleen 1000 hengen otosta, Nato-jäsenyyden kannatus ei olisi tässä
uudessa otoksessa täsmälleen sama kuin ensimmäisessä otoksessa. Oletetaan, että
tässä toisessa otoksessa Nato-jäsenyyden kannatus olisi 42 %. Jos tutkimus
toistettaisiin vielä kerran saman kokoisella satunnaisotoksella, jäsenyyden
kannatus voisi olla 46 %. Tätä prosessia voitaisiin edelleen toistaa useita
kertoja ja jokaisen uuden otoksen perusteella saataisiin uusi Nato-jäsenyyden
kannatusta kuvaava prosenttiluku. Näistä luvuista voidaan muodostaa uusi
muuttuja, jonka jakaumaa voidaan kutsua Nato-jäsenyyden kannatuksen
otantajakaumaksi.
Määritelmän
muukaan otantajakauma viittaa sellaiseen tunnusluvun jakaumaan, joka saadaan
ottamalla kaikki mahdolliset saman kokoiset otokset perusjoukosta. Jos
kiinnostuksen kohteena oleva muuttuja on Nato-jäsenyyttä kannattavien
suomalaisten osuus kaikista suomalaisista ja otoksen koko on 1000 vastaajaa,
saadaan Nato-kannattajien osuuden otantajakauma ottamalla kaikki mahdolliset
1000 hengen otokset suomalaisista ja kirjaamalla ylös saatu Nato-kannattajien
osuus. Näiden kirjattujen kannattajalukujen jakauma on Nato-jäsenyyden
kannatusta kuvaavan muuttujan otantajakauma. Viidestä miljoonasta suomalaisesta
voidaan ottaa kuitenkin valtava määrä 1000 hengen otoksia. Niinpä otantajakauma
on usein itse asiassa vain teoreettinen jakauma, jota ei empiirisesti yleensä
pystytä määrittämään. Yleinen idea kuitenkin on, että käyttämällä
tilastotieteen menetelmiä otantajakauman keskeiset piirteet pystytään saamaan
selville.
Luottamusvälin laskeminen
Kuvitellaan, että
aiemmin esitetyssä Nato-kysymyksessä on vain kaksi vaihtoehtoa eli vastaajat
ovat joko jäsenyyden kannalla tai sitä vastaan. Vastaajista 45 % kannatti ja 55
% vastusti jäsenyyttä. Nyt tehtävänä on selvittää, millä välillä perusjoukon
Nato-kannatus on tietyllä varmuudella. Kun vaihtoehtoja on vain kaksi, saadaan
tulos käyttämällä seuraavaa kaavaa:
![]()
Kaavassa S
tarkoittaa mielenkiinnon kohteena olevan tunnusluvun keskivirhettä (eli sen
otantajakauman keskihajontaa), p on ’kyllä’ vastanneiden prosenttiosuus, q on
’ei’ vastanneiden prosenttiosuus ja n on otoksen koko. Sijoittamalla luvut
(p=45, q=55, n=1000) kaavaan saadaan keskivirheen arvoksi noin 1,57. Tätä lukua
voidaan käyttää hyväksi määriteltäessä Nato-kannatuksen luottamusväli
perusjoukossa.
Nato-kannatuksen
95 % luottamusväli saadaan kaavasta p ± 1,96*S eli 45 ± 1.96*1,57. Tämä väli on
41,9 %-48,1 %. Eli johtopäätöksenä tutkija voisi todeta, että suomalaisten
Nato-kannatus on 95 % prosentin todennäköisyydellä 41,9 % ja 48,1 % välillä.
Käytännössä tämä tarkoittaa sitä, että jos suomalaisista otettaisiin hyvin
suuri määrä 1000 hengen otoksia, 95 % näistä otoksista Nato-kannatus olisi
edellä mainitulla välillä. Jos luottamustasoksi valitaan 99 %, kasvaa myös
luottamusväli. Tällöin väli saadaan kaavasta p ± 2,58*S eli se olisi 40,9
%-49,1 %. Edelliset kertoimet (1,96 ja 2,58) saadaan normaalijakaumasta. Se,
miten ne on johdettu, selitetään tilastotieteen oppikirjoissa, joten tässä
yhteydessä siihen ei paneuduta syvemmin. Hyvä muistisääntö on, että 95 %
luottamusväli saadaan noin ± 2*keskivirhe, ja 99 % prosentin luottamustasolla
vastaava kerroin on noin 2,5.
Jos kiinnostuksen
kohteena on jonkin muuttujan keskiarvo,
saadaan sen keskivirhe (standard error of the mean) kaavasta:
![]()
Kaavassa S on
keskiarvon keskivirhe, s on otoksesta laskettu muuttujan keskihajonta ja n on
otoskoko. Keskiarvon keskivirhettä käytetään samalla tavalla kuin edellisessä
esimerkissä.
Esimerkkinä
keskiarvon keskivirheen käytöstä voidaan käyttää vuoden 1996 World Values
–kyselyn suomen osa-aineiston (ks. »aineistonkuvaus) kysymystä v123, jossa vastaajia pyydettiin
arvioimaan itseään vasemmisto-oikeisto –mittarilla. Tässä mittarissa oli arvoja
yhdestä kymmeneen, ja pienet luvut kuvastivat vasemmistolaisuutta ja suuret
luvut oikeistolaisuutta. Etukäteen voidaan arvioida, että suomalaisten
keskiarvo mittarilla on jossain sen keskivaiheilla, eli arvon 5,5 lähettyvillä.
Seuraavaksi tutkitaan, eroaako suomalaisten keskiarvo tilastollisesti
merkitsevästi tästä luvusta.
Kyselyn
vastaajista 856 suostui sijoittamaan itsensä vasemmisto-oikeisto
-ulottuvuudelle. Keskiarvo oli 5,61 eli keskimäärin suomalaiset vaikuttaisivat
olevan hiukan keskipisteen ”oikeammalla” puolella. Otoksesta laskettu muuttujan
keskihajonta oli 1,92. Käyttämällä edellä esiteltyä keskiarvon keskivirheen
kaavaa, saadaan keskivirheen arvoksi 0,19 (=1,92/√856). Samoin kuin
edellisessä esimerkissä voidaan 95% luottamusväli suomalaisten keskimääräiselle
sijoittumiselle oikeisto-vasemmisto –ulottuvuudella laskea kaavasta 5,61 ±
1,96*0,19 eli se on 5,24 – 5,98. Koska luku 5,5 sijoittuu tämän luottamusvälin
sisään, johtopäätös on, että suomalaisten keskimääräisen poliittisen
sijoittumisen ei voida sanoa eroavan 95% varmuudella laskennallisesta
keskipisteestä. Lukijan tulkintojen varaan jääköön se, mitä tämä kertoo
ulottuvuuden kyvystä kuvata suomalaista puoluejärjestelmää.
Otoksen ja perusjoukon
suuruuden merkitys
Edellä esitettyä
keskiarvon keskivirheen kaavaa voidaan käyttää hyväksi tarkasteltaessa otoskoon
merkitystä tilastollisessa päättelyssä. Kaavassa on jakajana otoskoon
neliöjuuri. Tämä tarkoittaa sitä, että otoskoon kasvaessa keskivirhe pienenee
ja valitun luottamustason luottamusvälit kapenevat. Toisin sanoen tämä
vahvistaa sinänsä intuitiivisestikin selvän havainnon, että otoskoon kasvaessa
pystytään tekemään tarkempia arvioita kiinnostuksen kohteena olevista
ilmiöistä. Koska kaavassa on jakajana otoskoon neliöjuuri, ei otoskoon kasvulla
ja tarkentuneilla perusjoukon estimaateilla ole kuitenkaan lineaarista
yhteyttä. Neliöjuuren takia täytyy otoskoko nelinkertaistaa, jotta
luottamusväli pystyttäisiin pienentämään puoleen.
Toinen (ja
vaikeammin intuitiivisesti ymmärrettävä) havainto on se, että perusjoukon
koolla ei ole vaikutusta tilastollisten yleistysten tarkkuuteen. Edellä
esitellyssä keskiarvon keskivirheen kaavassa ei ole perusjoukon koko mukana.
Tämä tarkoittaa karkeasti ottaen sitä, että samankokoisilla otoksilla voidaan
arvioida samoja ilmiöitä väestömäärältään erikokoisissa valtioissa jokseenkin
samalla tarkkuudella. Tämä huomioiden ei ole yllättävää, että esimerkiksi
presidenttiehdokkaiden kannatusmittaukset tehdään sekä Suomessa että
Yhdysvalloissa suurin piirtein samanlaisilla otoskoilla (1000-2000 vastaajaa).
Koska molemmissa maissa kyselyiden tilaajat ovat valmiita hyväksymään saman
tarkkuustason valtakunnallisissa tuloksissa, ei Yhdysvalloissa olisi järkevää
lähteä tekemään tutkimuksia paljon suuremmilla otoksilla kuin Suomessa.
Lisätietoja
Suomeksi tilastollista päättelyä on käsitelty mm.
Nummenmaan ym. kirjassa:
·
Nummenmaa, Tapio & Konttinen,
Raimo & Kuusinen, Jorma & Leskinen, Esko (1996): Tutkimusaineiston
analyysi. WSOY, Porvoo.
Tilastollisen päättelyn periaatteet löytyvä useimmista
tilastotieteen perusoppikirjoista. Suomenkielellä katso esimerkiksi:
·
Vasama, Pyry-Matti & Vartia, Yrjö
(1980): Johdatus tilastotieteeseen I. Neljäs korjattu painos. Gaudeamus,
Pori.
Englanninkielellä tilastollisen päättelyn perusteita voi
opiskella esimerkiksi seuraavista kirjoista:
·
Bohrnstedt, George W. & Knoke, David (1988): Statistics for
Social Data Analysis. Toinen pianos. F.E. Peacock Publishers, Itasca.
·
Cohen, Louis & Holliday, Michael (1996): Practical Statistics
for Students. Paul Chapman Publishing, Lontoo.
·
Moore, David S. (1995): The Basic Practice of Statistics. W.H.
Freeman and Company, New York.
Suomenkielellä verkosta löytyy ns. ”Internetix-oppimisympäristöstä” kaksi
tilastotieteen peruskurssia. Molemmat perustuvat Simo Kivelän materiaaliin.
”Tilastot ja todennäköisyys” –kurssi löytyy osoitteesta:
·
http://www.internetix.ofw.fi/opinnot/opintojaksot/5luonnontieteet/matematiikkal/mb3/
Ja ”Tilastotiedettä ja todennäköisyyslaskentaa” –kurssi
osoitteesta:
·
http://www.internetix.ofw.fi/opinnot/opintojaksot/5luonnontieteet/matematiikka/tilastot/index.htm
Englanninkielistä
lisätietoa tilastollisesta päättelystä löytyy mm. Hyperstat Online -palvelusta,
jonka osoite on:
Toinen hyvä
verkkoresurssi on Gene V. Glassiin pitämän ”Intro to Quant Methods” –kurssin
sivut osoitteessa (valitse kohta ”Lesson six: Sampling and Statistical
Inference”):
Kalvot
- Kuvaileva tilastoanalyysi tiivistää
informaatiota muuttujien ominaisuuksista ja niiden välisistä suhteista.
- Ei ole tarkoitus tehdä yleistyksiä
perusjoukosta.
- Tilastollisen päättelyn avulla
voidaan tehdä johtopäätöksiä perusjoukosta.
- Kuinka hyvin otoksen avulla mitatut
tulokset voidaan yleistää koko perusjoukkoa koskeviksi tuloksiksi?
- Luottamusväli kertoo mille välille
perusjoukon tunnusluvun arvo sijoittuu tietyllä todennäköisyydellä.
- Esim. 95% todennäköisyydellä
suomalaisten Nato-kannatus sijoittuu 40-50% välille.
- Luottamustaso kertoo, millä
todennäköisyydellä perusjoukkoa kuvaava tunnusluku on tietyllä
luottamusvälillä.
- Edellisessä esimerkissä 95% on
luottamustaso.
- Luottamusväli tietämiseksi täytyy
tietää luottamustaso ja päinvastoin.
- Luottamusvälin ymmärtämistä helpottaa
otantajakauman käsite.
- Otantajakauma on tunnusluvun jakauma,
joka saadaan ottamalla kaikki määrätyn kokoisen otokset perusjoukosta.
- Esim. otetaan kaikki mahdolliset
1000 hengen otokset suomalaisista ja lasketaan Nato-kannattajien osuus
jokaisesta otoksesta.
- Otantajakauman ominaisuudet voidaan
määritellä laskennallisesti tilastotieteen menetelmin.
- Luottamusvälin laskemiseksi tarvitaan
tieto tunnusluvun keskivirheestä.
- Jos kyse on osuudesta (esim. kuinka
monta prosenttia suomalaisista kannattaa Nato-jäsenyyttä), se saadaan
kaavasta:
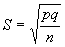
- Kaavassa S=keskivirhe, p=kannattajien
prosenttiosuus, q=vastustajien prosenttiosuus, n=otoskoko.
- Jos kyse on keskiarvosta (esim. mikä
on suomaisten keskipalkka) saadaan keskivirhe kaavasta:
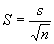
- Kaavassa S=keskivirhe, s=muuttujan
keskihajonta otoksessa, n=otoskoko.
- 95% luottamusväli lasketaan kaavasta:
- otoskeskiarvo ± 1,96 * keskivirhe
- Esim. otoksessa 45% kannattaa Natoa
ja keskivirhe on 1,57.
- Silloin Nato-kannatus on välillä 45% ± 1,96*1,57 eli 41,9%-48,1%.
- Jos halutaan 99% luottamusväli,
käytetään kertoimena 2,58.
- Otoskoon kasvaessa luottamusväli
pienenee eli pystytään tekemään tarkempia arvioita perusjoukosta.
- Luottamusvälin puolittamiseksi
otoskoko täytyy nelinkertaistaa.
- Perusjoukon koko ei vaikuta
tilastollisten yleistysten tarkkuuteen.
- Esim. samaa otoskokoa voidaan
käyttää väestömäärältään eri kokoisissa maissa.