^
voi^mma
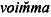 )
)>
kyl>ymä
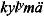 )
)\
kal\a
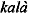 )
){2. redusoituminen
l\a{iva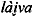 )
)}
l\a}eva
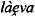 )
)~
ka~ah
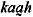 )
)+
tule+
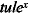 )
)_
siell_oli
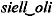 )
)<(
vaa<(an
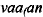 )
)#
ke#kä
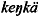 )
)£
p££
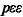 )
)&
siih&
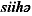 )
)å
tuålta
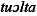 )
)%
sy%tiin
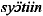 )
)§
sy§än
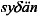 )
)$
me$$ä
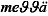 )
)¤
syä¤mään
 )
)23.5.2002 - versio 1.0
Juha Kuokkala
Kieliteknologian proseminaari 2001-2002
Käsillä olevan työn tarkoituksena on selvittää mahdollisuuksia suomen murteiden muoto-opin arkiston digitoitavan aineiston koodaamiseen XML-muotoiseksi ja aineistohaun toteuttamista tästä XML-korpuksesta. Tähän dokumenttiin on koottu tiiviissä muodossa työn edellyttämiä taustatietoja, erinäisiä toteutukseen liittyviä vaihtoehtoja ja ongelmia sekä lopuksi yleisellä tasolla kuvattu toteuttamani hakusysteemin ja sen käyttöliittymän toiminta. Toistaiseksi olen tehnyt tätä kiinnostuspohjalta puhtaasti vapaaehtoistyönä, mutta mahdollista on, että tulevaisuudessa saattaisin myös jonkin aikaa jatkaa järjestelmän kehitystä Akatemian digitointiprojektiin (ks. luku 2.2.) palkattuna.
Helsingin yliopiston suomen kielen laitoksen yhteydessä toimivan Muoto-opin arkiston tarkoitus on tarjota tutkijoille systemaattisesti järjestettyä kieliopillista aineistoa suomen murteista. Käytännössä aineisto koostuu A6-kokoisille paperilipuille kirjoitetuista lause-esimerkeistä. Nämä on järjestetty toisaalta pitäjittäin, toisaalta 897 signumia käsittävän morfologisen koodituksen mukaan (ks. T. Itkonen 1969, 1975, 1978).
Arkisto on perustettu 1967, ja nykyisin se sisältää aineistoa noin joka kolmannesta Suomen pitäjänmurteesta. Arkistolippuja on noin 500 000 ja lause-esimerkkejä näissä arviolta 2 miljoonaa. Uusin aineisto on tallennettu myös suoraan tietokonemuotoisena. Vuoden 2001 lopulla konemuotoisena oli noin 33 000 tietuetta, tällä hetkellä (huhtikuussa 2002) digitointihankkeen alettua jo noin 65 000 tietuetta eli n. 3 % koko aineistosta.
Loppuvuodesta 2001 käynnistyi Suomen Akatemian rahoittama tutkimushanke, jonka tavoitteena on luoda Suomen murteiden morfologinen digitaaliarkisto (Electronic Morphology Archives for Finnish Dialects). Tämä tarkoittaa siis käytännössä paperilipuilla olevan arkistotiedon siirtämistä digitaaliseen (teksti-) muotoon niin, että se olisi internetin kautta tutkijoiden helposti saatavilla joka puolella maailmaa. Hanke on kolmivuotinen, ja sitä tekemään on palkattu kaksi täysipäiväistä tutkijaa. Hankkeen vastuullinen johtaja on Muoto-opin arkiston amanuenssi Kaisu Juusela.
Digitointihankkeessa on yhteistyökumppanina CSC - Tieteellinen laskenta Oy:n Kielipankki (http://www.csc.fi/kielipankki/), joka on ainakin sitoutunut ottamaan aineistot myöhemmässä vaiheessa huollettavakseen. Tähän mennessä CSC:n suunnasta ei ole juuri löytynyt resursseja yhteistyöhön, vaan Muoto-opin arkiston projektiryhmä on edennyt asiassa itsenäisesti: Päivi Nieminen on keskittynyt näppäilemään arkistolippujen tietoja konemuotoon, Mika Kukkola on lisäksi pähkäillyt teknisten kysymysten kimpussa. Tällä hetkellä tiedot on tallennettu FileMaker-tietokantaan ("perinteinen" relaatiotietokanta), ja koekäytössä on ollut myös kyseisen ohjelman palvelinominaisuudella toteutettu WWW-hakuliittymä. Kuitenkin taustalla on kummitellut ajatus, että aineiston lopullinen tallennusmuoto olisi XML-pohjainen.
XML (extensible markup language) on rakenteinen kuvauskieli,
joka muistuttaa HTML:ää ja SGML:ää.
Itse asiassa XML on kehitetty SGML:n "parannetuksi painokseksi" mm.
säännönmukaisuutta ja helppokäyttöisyyttä silmälläpitäen.
SGML:n tapaan XML-standardi (W3C XML 2000) määrittää vain yleiset puitteet dokumenttien
kuvaukseen, esim. että ne rakentuvat elementeistä, joiden alku ja loppu merkitään
tunnisteilla (engl. tag) kuten
<p> </p> , mutta ei ota kantaa elementtien merkityksiin.
Näin kutakin sovellusta varten voidaan määrittää ja ottaa käyttöön siihen sopiva
elementtirakenne. Muodollisesti XML-dokumentin rakenne voidaan määritellä
alkuaan SGML:ään kehitetyn dokumenttityyppimäärittelyn (DTD, document type definition) avulla.
Vaihtoehtoinen tapa on XML-skeema (XML schema), joka mahdollistaa
tarkemman määrittelyn datatyyppien suhteen.
Yksi XML:n lähtöajatuksista oli helpottaa erityyppisen rakenteisen tiedon välitystä verkkoympäristössä. Sen perustavanlaatuisia vahvuuksia on tekstimuotoisen koodauksen ohjelmistoriippumattomuus, skaalautuvuus sekä sovellettavuus mitä erilaisimpiin tehtäviin. XML:n käyttö onkin kasvanut huimasti paitsi tiedon tallennus-, niin ennen kaikkea siirtoformaattina. (w3.org/XML.)
Erilaisiin sovelluksiin räätälöityjä XML-dokumenttityyppejä on siirrettävyyden saavuttamiseksi tietenkin pyritty standardisoimaan. Kieliteknologian sovelluksia lähimpänä on ehkä TEI (Text Encoding Initiative, ks. TEI Consortium 2001), joka pyrkii määrittämään ennen kaikkea kirjallisuuden ja kielentutkimuksen näkökulmasta yleiskäyttöisen ja yhtenäisen tavan tallentaa erilaisia tekstejä XML-muodossa.
Varsinaisen XML-standardin ympärille on myös kehittynyt suuri joukko täydentäviä määrityksiä ja tekniikoita (puhutaan ns. XML-perheestä). Seuraavassa luvussa on esimerkiksi lueteltu tietokantamaisiin toimintoihin liittyviä laajennuksia, ja tässä yhteydessä kannattaa mainita myös XSL (extensible stylesheet language), XML-sivujen ulkoasun muotoilussa käytettävä kieli, sekä tämän laajempi versio XSLT, jolla voi toteuttaa monenlaista XML-dokumenttien rakenteen uudelleenmuotoilua.
XML-dokumenttia voi sinänsä pitää eräänlaisena tietokantana, jolla on tiettyjä etuja tavallisiin tietokantoihin nähden: tekstimuotoisen merkkauksen ansiosta se on siirrettävä ja rakenteeltaan itseselitteinen, ja rakenne voi muodostaa puumaisen hierarkian. Toisaalta puutteet ovat myös selviä: tallennuksen ja tiedonhaun tehokkuus, monen käyttäjän järjestelmät ja tiedon eheys jne. XML-tiedosto sellaisenaan sopii parhaiten pienehköjen datamäärien ja vähälukuisten käyttäjien tietokannaksi. (Bourret 2001).
XML:n ympärille on kuitenkin kehitetty varsin paljon standardeja ja sovelluksia, jotka tarjoavat tietokantamaisia toimintoja, kuten kyselykieliä (XQuery, XPath, XQL, XML-QL, QUILT) ja ohjelmointirajapintoja (SAX, DOM, JDOM). XML:ään erikoistuneita tietokantatuotteitakin löytyy maailmalta jo pilvin pimein (ks. esim. Bourret 2002). Näitä voidaan luokitella
XML:n käyttötarkoituksen mukaan tietokantasovellukset voidaan karkeasti jakaa kahteen prototyyppiseen ryhmään: datakeskeisiin ja dokumenttikeskeisiin. Datakeskeiset sovellukset käsittelevät tyypillisesti määrämuotoisia tietueita, kuten esimerkiksi tavarantilauksia, ja niissä olennaista on datasisältö, ei niinkään dokumentin rakenne. Datakeskeiset sovellukset käyttävät usein XML:ää pelkästään tiedon siirtomuotona. Dokumenttikeskeiset sovellukset taas käsittelevät muodoltaan epäsäännöllisempää dataa, kuten WWW-sivuja ja vastaavia ihmisen luettavia dokumentteja. Tällöin dokumenttien rakenne ja tiedon järjestys on myös tärkeää. Tyypillisesti dokumenttikeskeisissä sovelluksissa XML on tiedon varsinainen esitysmuoto eikä pelkästään siirtoformaatti. Datakeskeisiin sovelluksiin käyvät parhaiten ylläolevan tuotejaotuksen tyypit (a) ja (b), dokumenttikeskeisiin taas (c), (d) ja (e).
Nämä Ronald Bourret'n (2001, 2002) esittämät jaotukset ovat tietenkin yksinkertaistuksia sikäli, että käytännössä jokin tietty sovellus voi palvella monia erilaisia tehtäviä, eikä sekään ole kiveen hakattu sääntö, että natiivi-XML-tietokannat olisivat vain dokumenttikeskeisiä sovelluksia varten. Esimerkiksi juuri Muoto-opin arkisto on sinänsä erittäin selvästi datakeskeinen, mutta jos aineiston tallennusmuotona käytetään XML:ää, on sen käsittelyssä luontevaa ja tehokasta käyttää natiivi-XML-tietokantaa.
Muoto-opin arkiston aineiston siirtäminen FileMaker-tietokannasta XML-muotoon ei sinänsä tuottane juuri ongelmia; aineisto on yhdessä yksinkertaisessa taulukossa, eikä sisällä sisäisiä viittauksia. Taulukon saa ohjelmasta ulos tekstitiedostona, josta pienellä (Perl- tms.) skriptillä saa äkkiä muokattua halutun muotoisen XML-tiedoston. Lähinnä pitäisikin päättää, minkä muotoinen XML-esitys halutaan, ts. kuinka aineisto koodataan. Tämä koskee ensinnäkin XML-dokumentin rakennetta (tunnisteita) ja toisaalta kielennäytteissä esiintyvien erikoismerkkien esittämistä.
Kukin murrenäytetietue sisältää itse näytetekstin lisäksi seuraavia tietoja (suluissa englanninkielinen XML-koodauksen pohjana oleva nimi):
Pakolliset: murrealue (area) pitäjä (parish) Yleensä esiintyvät: signumi(t) (signum(s)) informantti (informant) Joskus esiintyvät: kerääjä (collector) sijainti (location) -- viittaus esim. lähdeteoksen sivulle kommentti (comment)
Alla on esimerkinomainen XML-dokumentti, jonka kaksi kielennäytettä on koodattu niin, että jokaiselle lisätietokentälle on oma elementti. Jälkimmäiseen on näytteeksi tekstiin merkattu yhden signumin viittaama sana <marked>-elementillä.
<?xml version='1.0' encoding="ISO-8859-1"?> <archive> <entry> <area>3</area> <parish>Isojoki</parish> <informant>JH</informant> <signum>271 704</signum> <text>tarttis olla aina jotain [tuloa]</text> </entry> <entry> <area>3</area> <parish>Isojoki</parish> <informant>JH</informant> <signum>271, 704</signum> <text><marked signum="704">tarttis</marked> olla aina jotain [tuloa]</text> </entry> </archive>
Lisätietojen esittäminen attribuutteina mahdollistaisi kompaktimman esitysmuodon:
<?xml version='1.0' encoding="ISO-8859-1"?> <archive> <entry area="3" parish="Isojoki" informant="JH" signum="271 704" > tarttis olla aina jotain [tuloa] </entry> <entry area="3" parish="Isojoki" informant="JH" signum="271 704" > <marked signum="704">tarttis</marked> olla aina jotain [tuloa] </entry> </archive>
Merkkaustunnisteiden nimiäkin voi tietysti tilansäästön nimissä lyhentää vaikka yksikirjaimisiksi asti, mutta haittana on tällöin luettavuuden huononeminen. Tosin itse XML-muotoista dataa ei lopullisessa sovelluksessa pitäisi käyttäjän joutua näkemään (jos ei tahdo), mutta elementtien ja attribuuttien nimiin saatetaan joutua viittaamaan esim. monimutkaisempia kyselyjä muodostettaessa. Keskitien ratkaisu voisi olla n. 3 kirjaimen pituiset lyhenteet:
<?xml version='1.0' encoding="ISO-8859-1"?> <archive> <entry ar="3" par="Isojoki" inf="JH" sig="271 704" > tarttis olla aina jotain [tuloa] </entry> <entry ar="3" par="Isojoki" inf="JH" sig="271 704" > <ma sig="704">tarttis</ma> olla aina jotain [tuloa] </entry> </archive>
Tietokantaan voisi myös saada enemmän rakenteisuutta kokoamalla kunkin pitäjän näytteet oman pitäjä-elementin sisälle, ja vastaavasti pitäjittäiset lohkot murrealueittain. Tällöin yksittäisten näytteiden pitäjä- ja murrealue-kentät voisi redundantteina jättää pois. Tämä säästäisi jonkin verran muistitilaa, mutta hakujen suorittamisen suhteen hyöty jää kyseenalaiseksi: indeksointia käytettäessä halutut tietueet löydetään joka tapauksessa varsin tehokkaasti, ja XML-rakennetasojen lisääntyminen saattaa tekniikasta riippuen päinvastoin hidastaa hakuprosessia. Yllä esitetyissä malleissa kukin tietue on itseriittoinen kokonaisuus, mutta jos pitäjätiedot siirretään muualle, ne pitää hakutuloksien esittämistä varten erikseen etsiä.
Toisaalta aineiston jakaminen useaan eri XML-dokumenttiin saattaisi olla järkevää mm. päivitettävyyden kannalta, jolloin luonteva jako olisi yksi dokumentti (tiedosto) per pitäjä. Tällöin kunkin dokumentin juurielementti voisi sisältää pitäjätiedon. Eikäpä pitäjätietojen poistaminen yksittäisistä näytteistäkään ole välttämätöntä, vaikka ne esiintyisivät myös ylemmän tason elementeissä.
Omaa, luvussa 6 esiteltyä hakusovellustani testaillessa olen päätynyt käyttämään seuraavan näytteen tapaista koodausta, jossa jokaisen pitäjän näytteet ovat eri XML-tiedostoina:
<?xml version='1.0' encoding="ISO-8859-1"?> <archive parish="Isojoki" area="3"> <entry area="3" parish="Isojoki" informant="JH" signum="271 704" > tarttis olla aina jotain [tuloa] </entry> <entry area="3" parish="Isojoki" informant="JH" signum="271 704" > <ma signum="704">tarttis</ma> olla aina jotain [tuloa] </entry> </archive>
Vastaava dokumenttityyppimäärittely ma.dtd näyttää tältä:
<!ELEMENT archive (entry*)> <!ELEMENT entry (#PCDATA|ma)*> <!ELEMENT ma (#PCDATA)> <!ATTLIST archive area (1|2|3|4|5|6|7) #IMPLIED> <!ATTLIST archive parish CDATA #IMPLIED> <!ATTLIST entry area (1|2|3|4|5|6|7) #REQUIRED> <!ATTLIST entry parish CDATA #REQUIRED> <!ATTLIST entry informant CDATA #IMPLIED> <!ATTLIST entry signum CDATA #IMPLIED> <!ATTLIST entry collector CDATA #IMPLIED> <!ATTLIST entry location CDATA #IMPLIED> <!ATTLIST entry comment CDATA #IMPLIED>
(Murrealuekoodeina on tässä vielä pelkät numerot 1–7; sittemmin koodit ovat muuttuneet, kun alamurrealueet on otettu mukaan.)
Edellä esitetyissä rakennemalleissa koko tekstinäyte on sijoitettu
yhtenä kokonaisuutena entry-elementin sisään.
Periaatteessa mahdollistahan olisi myös koodata jokainen sana
(ja välimerkki) omaksi elementikseen, kuten useissa SGML-muotoisissa
kielikorpuksissa on tehty. Tässä tapauksessa vain en näe koodauksesta
koituvan mitään erityistä hyötyä, koska sanoihin ei liitetä monista
SGML-korpuksista tuttuja sanaluokka- tai lauseenjäsentietoja.
Signumitietojenkin koodaaminen yksittäisiin sanoihin näyttää tällä
hetkellä työläytensä takia epävarmalta.
Aineiston ylläpidettävyyttä on myös mietittävä. Kun se kerran on muunnettu XML-muotoon, onko mahdollisesti tarvetta muokata sitä jälkeenpäin, esim. lisätä tietueita tai signum-koodeja? Tehdäänkö muutokset alkuperäiseen FileMaker-aineistoon, joka konvertoidaan uudelleen XML:ksi, vai muokataanko suoraan XML-tiedosto(j)a? Jälkimmäinen vaikuttaa ainoalta vaihtehdolta, jos käytetään näytteiden sisäisiä signum-tunnisteita, joita ei kovin järkevästi FileMaker-tietokannassa voi esittää (ellei raakoina XML-tageina). XML-aineiston muokkaukseen pitäisi tällöin olla jokin työkalu, joka näyttäisi datan ihmiselle järkevässä muodossa ja jolla tarvittavat toimenpiteet kävisivät helposti. Selvitettävä on siis vielä, millaisia XML-editoreja on, ja kävisikö jokin tähän tarkoitukseen suoraan tai muokattuna (jos kyseessä on open source -ohjelma). Pienimuotoinen muokkailu vielä onnistuu XML-koodia suoraan käsitellen, mutta vähänkin isompien aineistomäärien lisääminen jo vaatii kätevämpiä välineitä.
Paperilippujen murreaineisto on kirjattu tavalliseen latinalaiseen kirjaimistoon perustuvalla suomalais-ugrilaisella tarkekirjoituksella (SUT, FUT = finno-ugric transcription; ks. esim. Sovijärvi & Peltola 1977, Iivonen & Sovijärvi & Aulanko 1990). FileMaker-tietokannassa kielennäytteet on tallennettu Windows-merkistön mukaisena tekstinä, jossa merkistöstä puuttuvat foneettisen transkription vaatimat erikoismerkit ja tarkkeet on esitetty allaolevan taulukon mukaisilla korvausmerkeillä. Käytännössä kaikki käytetyt merkit ovat myös 7-bittisen ASCII-merkistön mukaisia lukuunottamatta merkkejä ä, ö, å, ¤ (valuuttamerkki), £ (punnan merkki) ja § (pykälän merkki). Koska nämä kaikki kuuluvat yleisesti käytössä olevaan 8-bittiseen Latin 1 (eli ISO-8859-1) -merkistöön (jonka muunnelma Windows-merkistö on), voidaan koodaus säilyttää jokseenkin sellaisenaan, kun XML-dokumentin merkkikoodaukseksi määritellään ISO-8859-1. Merkistöistä tarkemmin esim. Korpela 2002.
Sinänsä voitaisiin käyttää Unicode-koodausta, kuten UTF-8 tai UTF-16, mutta tämä saattaisi aiheuttaa yhteensopivuusongelmia, kun nykyisistä ohjelmista monetkaan eivät moisia vielä ymmärrä. UTF-koodaus veisi sitä paitsi hieman enemmän muistitilaa 7-bittisen ASCIIn yläpuolisten merkkien osalta. ISO-8859-1 on kuitenkin periaatteessa Unicoden osajoukko, joten koodausristiriitoja ei pitäisi tulla, vaikka tulevaisuudessa Unicodeen laajemmin siirryttäisiinkin. Ja jos kehitys on suotuisa, jossain vaiheessa saattaisi jopa tulla mahdolliseksi siirtyä erikoismerkkien esityksessä näiden oikeisiin Unicode-koodeihin. FU-transkription saattaminen Unicode-standardiin on kuitenkin vielä kesken (ks. ehdotus Everson, Ruppel & Trosterud 2002), ohjelmistojen tuesta puhumattakaan.
^ |
vajaalyhyt | voi^mma |
() |
||||
> |
rivinylisyys (ylilyhyt) | kyl>ymä |
() |
||||
\ |
gravis | kal\a |
() |
||||
{ |
1. avoimemmuus 2. redusoituminen |
l\a{iva |
() |
||||
} |
suppeammuus | l\a}eva |
() |
||||
~ |
nasaalistuminen | ka~ah |
() |
||||
+ |
loppukahdennus | tule+ |
() |
||||
_ |
sandhi | siell_oli |
() |
||||
<( |
tavun raja | vaa<(an |
() |
||||
# |
äng-äänne | ke#kä |
() |
||||
£ |
avoin e | p££ |
() |
||||
& |
redusoitunut keskivokaali | siih& |
() |
||||
å |
avoin o | tuålta |
() |
||||
% |
avoin ö | sy%tiin |
() |
||||
§ |
soinnillinen dentaalispirantti | sy§än |
() |
||||
$ |
soinniton dentaalispirantti | me$$ä |
() |
||||
¤ |
labiaalistuminen | syä¤mään |
() |
Ylläolevien lisäksi näytteissä käytetään tavallisia ASCII-aakkosmerkkejä (a–z) sekä kaari- ja hakasulkeita erottamassa epäselviä kohtia ja huomautuksia.
Ongelmallisia merkkejä ovat "&"-merkki, joka on XML:ssä varattu merkkientiteettien esittämiseen, sekä tavunrajamerkissä esiintyvä "<", joka XML:ssä osoittaa merkinnän (markup) alkua. Korvaaviksi korvausmerkeiksi sopisivat seuraavat, ennestään käyttämättömät erikoismerkit:
| |
tavun raja | vaa|an |
() |
||||
@ |
redusoitunut keskivokaali | siih@ |
() |
Lisäksi hieman mietitystä on aiheuttanut apostrofin eli heittomerkin (') käyttö.
Paitsi että kyseinen merkki XML:n erikoismerkkinä saattaa jossain tilanteessa
aiheuttaa ongelmia, on merkin semantiikka murrenäytteiden koodauksessa
kahtalainen: sitä on käytetty sekä edeltävän konsonantin liudennuksen
(se ol' semmon'ej juoppo) että laryngaaliklusiilin merkkinä
(tämmöne' 'ensi' 'oli).
Esiintymisympäristön perusteella on tosin yksiselitteisesti erotettavissa,
kummasta on kulloinkin kyse (konsonantin jäljessä liudennus ja muulloin
laryngaaliklusiili), mutta hakuehtojen yksiselitteistämiseksi saattaisi
olla syytä koodata nämä eri merkeillä.
XML-muotoon siirretyn arkiston käytettävyyden kannalta on ensisijaisen tärkeää, että aineistosta pystytään tekemään hakuja. Hakuohjelman pitäisi olla toisaalta mahdollisimman helppokäyttöinen, toisaalta mielellään monipuolisia hakumahdollisuuksia tarjoava sekä laskennallisesti tehokas, koska aineiston määrä on melko suuri (2 milj. esimerkkilausetta vastaa noin 200 megatavua raakadataa). Yksinkertainen grep-tyyppinen haku, joka käy joka kerta koko aineiston läpi, kuluttaa tällaisella aineistolla kohtuuttoman paljon prosessoriaikaa, joten jonkinlainen indeksointisysteemi on välttämätön.
Alustavassa kartoituksessa vastaan tuli ainakin seuraavia harkinnan arvoisia vaihtoehtoja:
Tällä hetkellä aineistolle on jo olemassa FileMakerin palvelinominaisuudella
toteutettu haku. Tällä voi hakea kriteereinä
(1) pitäjä (ja/tai murrealuekoodi),
(2) signum(it),
(3) teksti (sisältäen kokonaiset ja osittaiset sanat ja fraasit),
joko yhdessä tai erikseen.
Mitä parannusta XML/Perl-toteutus voisi tuoda?
Saatavilla olevia XML-tietokantaohjelmia tutkiessa osoittautui lupaavaksi vapaan lähdekoodin periaatteella (open source) levitettävä eXist (Meier 2002, http://exist.sourceforge.net/). Ohjelma on vielä ns. beta-vaiheessa (uusin versio 0.7.1) mutta vaikutti varsin toimivalta ja monipuoliselta. Mukana tulevan kirjastoluettelo-esimerkkisovelluksen pohjalta sain kohtuullisen nopeasti kehitettyä alustavan www-hakusovelluksen murrearkistoa varten. Seuraavassa esittelen lyhyesti ensinnäkin itse XML-tietokantaa pyörittävää eXist-ohjelmaa sekä sen ympärille kasattua hakujärjestelmää kokonaisuudessaan.
eXist on periaatteessa "natiivi" XML-tietokantaohjelma; se käyttää dokumenttien tallennukseen ja indeksointiin omia tietorakenteitaan, joista laajojenkin XML-fragmenttien saanti onnistuu nopeasti. (Myös ulkopuolisen tietokanta-"backendin" käyttö on mahdollista.) Ohjelma on toteutettu kokonaan javalla, joten sen käyttö onnistuu kaikissa laitteistoissa, joihin on asennettu Java 2 -ympäristö (sama pätee myös seuraavassa luvussa esiteltyihin muihin hakujärjestelmän komponentteihin). Itse käytin testailussani Helsingin yliopiston yleisen kielitieteen laitoksen Linux-palvelinta mars.ling.helsinki.fi.
Tietokannasta voidaan hakea tietenkin kokonaisia dokumentteja, mutta etenkin arkistolippusovellukselle on tarpeellista pystyä hakemaan haluttuja dokumentin osia (jokaisen lause-esimerkin tallettaminen omana dokumenttinaan ei olisi järkevää). eXist mahdollistaakin varsin tarkkaan suunnatun XML-elementtien haun haluttaessa joko elementtihierarkian, attribuuttiarvojen tai sisältyvän tekstin perusteella. Haku on myös nopea, koska kaikista näistä on dokumentteja ladattaessa rakennettu hakusanaindeksit ja myös tieto rakennehierarkiasta tallennetaan objektien tunnisteet sisältävänä puuna. Hakulausekkeissa käytetään XPath-syntaksia (ks. W3C XPath 1999), jota on laajennettu joillakin sanahakua tukevilla ominaisuuksilla. (Tällaisia ovat operaattorit &= ja |= , jotka käsittelevät seuraavaa argumenttia hakusanojen listana, sekä mahdollisuus käyttää hakusanamerkkijonossa säännöllisen lausekkeen (regular expression) syntaksia.)
Esimerkkejä XPath-lausekkeista:
document('Salla.xml')//entry- Hakee dokumentista
Salla.xmlkaikkientry-elementit.
document(*)/archive/entry[@parish = 'Salla']- Hakee kaikista dokumenteista juurielementti
archive:n lapsina olevatentry-elementit, joidenparish-attribuutin arvo on 'Salla'.
document(*)//entry[@signum &= '111 222']- Hakee kaikista dokumenteista
entry-elementit, joidensignum-attribuutin arvo sisältää sanat '111' ja '222'.
document(*)//entry[. &= 'lehmä']- Hakee kaikista dokumenteista
entry-elementit, joiden tekstiosa sisältää sanan 'lehmä'.
Käyttäjälle tai asiakasohjelmille eXist tarjoaa moninaisia liittymämahdollisuuksia. Yksinkertaisin on komentorivikäyttöliittymä, jota on kätevää käyttää ainakin harvempaan tapahtuvassa ylläpidossa, siis XML-dokumenttien tallentamisessa ja päivittämisessä tietokantaan. Toisaalta eXist on mahdollista yhdistää omaan java-ohjelmaan ja käyttää tietokantatoimintoja standardoidun XML:DB-sovellusrajapinnan kautta (www.xmldb.org). Tämän lisäksi on, tietokantapalvelinkomponentin ollessa muistiin ladattuna, mahdollisuus käyttää TCP/IP-kutsuja joko HTTP- tai XML-RPC-protokollalla (RPC = remote procedure call, ks. www.xml-rpc.org). Nämä käyttöliittymät sellaisinaan eivät vielä ole riittäviä käyttäjäystävälliseksi hakupalveluksi, sillä niitä varten kyselylauseke on koodattava URL:ksi tai XML-muotoiseksi kyselydokumentiksi, ja palvelin lähettää vastaukseksi yksinkertaisesti pyydetyn pätkän XML-koodia. Seuraavassa luvussa esitellään pääpiirteissään eXistin esimerkkisovelluksista muokatun XML-RPC:tä käyttävän WWW-hakuliittymän toiminta.
Hakuliittymän rakennetta on luonnosteltu kuvassa 1. Varsinaisen eXist-tietokantapalvelimen lisäksi käytössä on WWW-palvelinohjelma, Jakarta Tomcat 4.0.1 (http://jakarta.apache.org/tomcat/), sekä tämän kyljessä XML-dokumenttien muunnoksista huolehtiva Cocoon 2 -servletti (http://xml.apache.org/cocoon/). Molemmat ovat Apache Software Foundationin ilmaisena levitettäviä, Javalla toteutettuja ohjelmia.
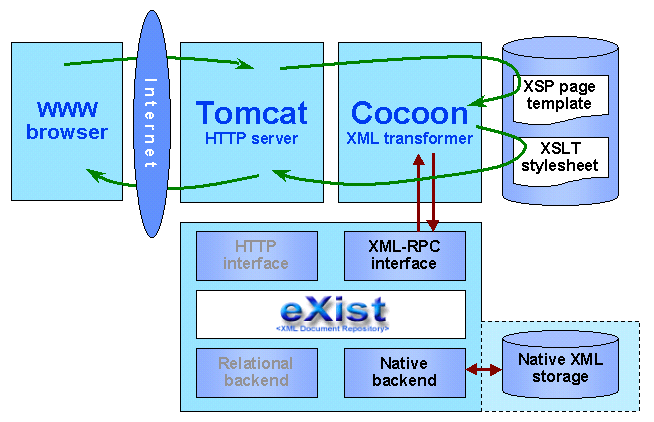
Hakukäyttöliittymän olennaiset osat ovat palvelinkoneella hakemistossa
exist (jakarta-tomcat-4.0.1/webapps/exist),
jonka sisältöä käsittelemään on Tomcatin asetuksissa määrätty Cocoon-servletti.
Hakemisto sisältää XML-tiedostoja, kuten
index.xml ja ma_form.xml,
jotka Cocoon muuntaa HTML-muotoon käyttämällä XSL-muotoilusivua
doc2html-2.xsl.
(Muotoilusivuihin ja muuhun hakemiston sisällön esittämiseen liittyvät
Cocoon-asetukset ovat tiedostossa sitemap.xmap.)
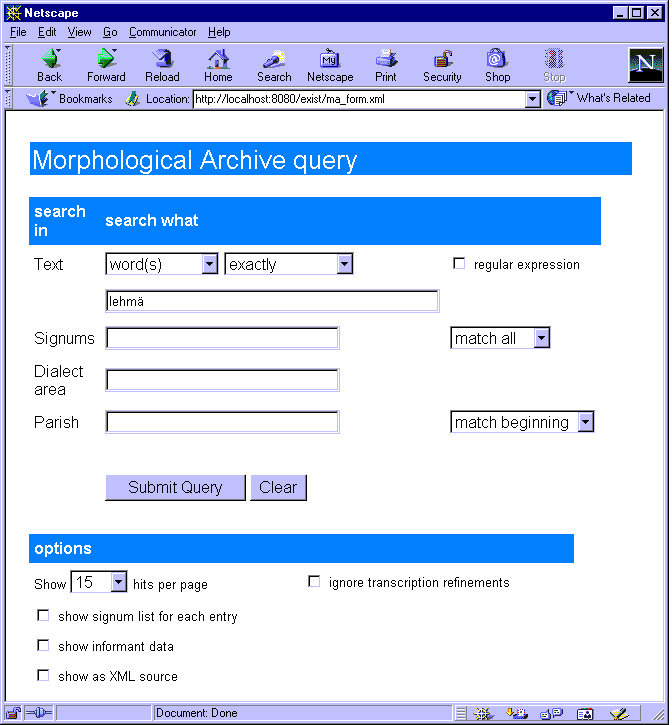
Hakuprosessi alkaa, kun käyttäjä täyttää WWW-selaimessaan hakulomakkeen
(ma_form.xml, normaali HTML-lomake) ja lähettää sen palvelimelle.
Lomakkeessa on määritelty seuraavaksi toiminnoksi XML-palvelinsivu
ma_query.xsp, jota Tomcat-palvelin siten pyytää Cocoonilta
lomakkeessa annetuilla parametriarvoilla.
Tämä sivu on kyselyn tulossivun XML-muotoinen pohja, joka sisältää
Java-kielisiä osioita mm. parametrien käsittelyä varten sekä
eXistin tietokantapalvelimelle lähetettävän XML-RPC-kutsun, jonka
tulos (XML-koodia) sijoitetaan kyseiseen kohtaan sivua.
Lopuksi Cocoon muuntaa saadun XML-sivun HTML-muotoon erityisellä
XSL-muotoiluohjeella (ma_style.xsl),
joka, paitsi sisällyttää itseensä yleisen HTML-muunnosreseptin
(doc2html-2.xsl), myös
ohjaa tietokantakyselystä saatujen XML-elementtien muotoilun
siistiksi HTML-taulukoksi.
Käyttäjä voi hakea arkiston tietueita kriteereinään
Tekstihaussa käytettävissä on sanahaku (nopeampi) sekä sanojen rajat mahdollisesti ylittävä fraasihaku. Sanoja voi hakea sekä täsmällisen muodon että alun, lopun tai keskikohdan perusteella. Lisäksi on mahdollista käyttää ns. säännöllisiä lausekkeita (regular expression) sanahahmojen määrittelemiseen. Toteutin myös näppärän option, jolla voi jättää näyteteksteissä esiintyvät tarkkeet huomiotta, eli hakusana "oma" löytää myös esim. muodon "om\a". (Teknisesti ohjelma lisää hakusanojen jokaisen kirjaimen väliin nolla tai enemmän tarkkeita mahdollistavan säännöllisen lausekkeen.)
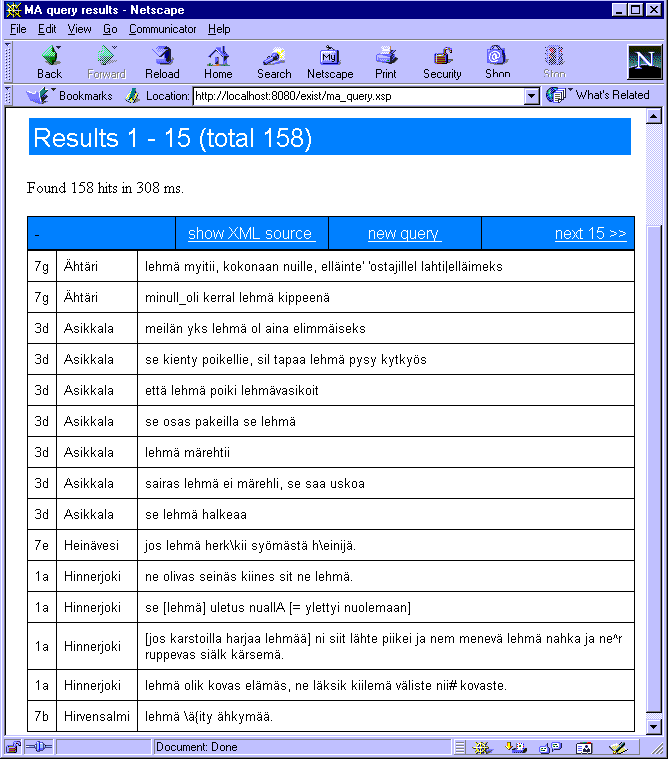
Testasin eXist-tietokantasysteemiä kolmella erikokoisella otoksella Muoto-opin arkiston aineistosta. (Aineiston muuntamiseksi tabuloidusta taulukosta XML-muotoon tein pienen Perl-ohjelman.) Otosten koot olivat noin 2 000, 20 000 ja 60 000 tietuetta, ja pienemmät aineistot olivat isompien osajoukkoja. Taulukossa 2 on aineiston syöttövaiheessa koottuja lukuja. Siitä havaitaan, että sekä tallennukseen kuluva aika että syntyvän tietokantadatan määrä riippuvat lineaarisesti tallennettavan XML-datan määrästä. eXistin data-hakemiston kooksi tulee noin 3,5 kertaa alkuperäisen XML-tiedostojen koko (vaikkakin eXistin dokumentaatio väittää suhteen olevan noin 2:1), ja tallennukseen kuluu aikaa noin minuutti tuhatta tietuetta kohden (koneella mars.ling.helsinki.fi). Tämä vastaisi 2 miljoonan tietueen aineistolle vajaan puolentoista vuorokauden tallennusaikaa. Aika riippuu tietenkin käytettävän prosessorin nopeudesta, joten tehokkaammalla koneella tehtävä sujuisi nopeamminkin.
| Tietueiden määrä | 2 000 (1 947) |
20 000 (19 479) |
60 000 (58 893) |
| XML-koodia (MB) | 0,3 | 3,0 | 8,3 |
| eXist-dataa (MB) | 1,1 | 10,3 | 27,3 |
| tietokantaan- tallennusaika |
2 min | 22 min | 67 min |
Kun aineisto oli syötetty eXist-tietokantaan, vertailin aineiston koon vaikutusta 11 erilaisen kyselyn hakuaikoihin. Tulokset näkyvät taulukosta 3. Tein kyselyitä ensinnäkin kahdella hakusanalla: harvaan esiintyvällä sanalla "lehmä" ja usein esiintyvällä sanalla "se". Näistä kokeilin vielä variantit "täsmälleen annettu sana" (EXACT), "alkaa" (BEG), "sisältää" (CONT) ja "loppuu" (END). Lisäksi kokeilin yhdistelmähakua "signum 117 ja murrealue 7" sekä tähän lisättynä vielä "tuommos"-alkuinen hakusana. Lopuksi testasin vielä fraasihakua "n k", joka siis hakee ne näytteet, joissa sananalkuista k:ta edeltää sananloppuinen n (eikä siis assimiloitunut velaarinasaali #). Taulukossa sarake A näyttää välittömästi eXistin uudelleenkäynnistyksen jälkeen mitatun hakuajan, jossa ohjelman muistipuskurit ovat tyhjät. Sarakkeessa B taas on hakuaika mitattuna tilanteessa, jossa on vastikään suoritettu samankaltaisen kysely ja eXist löytää tietoja suoraan muistipuskuristaan tarvitsematta hakea kaikkea levytiedostosta. Aika-arvot ovat millisekunneissa, ja ne ovat 3–4 erillisen mittauksen keskiarvoja.
| Tietueiden määrä | 2 000 (1 947) | 20 000 (19 479) | 60 000 (58 893) | ||||||
| osumia | A (ms) | B (ms) | osumia | A (ms) | B (ms) | osumia | A (ms) | B (ms) | |
| lehmä EXACT | 1 | 336 | 27 | 51 | 540 | 90 | 158 | 1355 | 237 |
| BEG | 19 | 414 | 72 | 189 | 840 | 264 | 630 | 1326 | 659 |
| CONT | 19 | 1448 | 887 | 192 | 5723 | 5022 | 637 | 17059 | 17089 |
| END | 1 | 1247 | 893 | 52 | 5586 | 4845 | 161 | 16989 | 13735 |
| se EXACT | 476 | 402 | 60 | 4712 | 743 | 264 | 12829 | 1480 | 669 |
| BEG | 715 | 1488 | 533 | 7198 | 3597 | 3032 | 18835 | 7146 | 6130 |
| CONT | 917 | 2519 | 2142 | 9157 | 15715 | 13293 | 24587 | 40749 | 31346 |
| END | 501 | 1454 | 1056 | 4960 | 6502 | 5733 | 13430 | 15107 | 14279 |
| sig 117 & area 7. | 35 | 716 | 258 | 327 | 2220 | 1370 | 327 | 3588 | 2652 |
| sig 177 & area 7. & BEG tuommos |
2 | 569 | 228 | 13 | 1833 | 1031 | 13 | 3001 | 1961 |
| PHRASE "n k" | 108 | 724 | 239 | 1279 | 2622 | 1805 | 2665 | 6282 | 5334 |
Odotetusti aikaavievimpiä ovat "sisältää"- ja "loppuu"- hakusanakyselyt, joita varten eXistiä ei ole optimoitu. Suuremmilla aineistoilla näiden hakujen vaatima aika kasvaa lineaarisesti aineiston määrän mukaan ja venyy jopa useisiin kymmeniin sekunteihin. Muut hakuajat kasvavat aineiston kymmenkertaistuessa 2000 -> 20000 keskimäärin noin kaksinkertaisiksi ja aineiston kolminkertaistuessa 20000 -> 60000 samoin. Tällä tahdilla saattaisivat miljoona-aineiston hakuajat laskennallisesti kasvaa lyhimmilläänkin jopa minuutteihin. Tämä on kuitenkin vain sivistynyttä arvailua; oikea testaus miljoonaluokan aineistolla antaisi luotettavampia tuloksia. Luultavasti muistipuskurien kokoa suurentamalla olisi mahdollista jonkin verran nopeuttaa suurempien aineistojen hakuja, varsinkin tilanteessa, jossa useampi käyttäjä tekee samanaikaisesti erilaisia hakuja. Tällöin myös levytiedoston lukeminen pullonkaulana menettää merkitystään, ja nopeus riippuu suoremmin prosessorin tehokkuudesta.
Kokeilin myöhemmin vielä 60000-aineistolla,
mitä vaikutusta olisi muistipuskurien koon kasvattamisella niin suureksi,
että periaatteessa koko tietokannan pitäisi mahtua muistiin,
sekä lisäksi työtiedostojen siirtämistä verkon yli käytettävältä
levypalvelimelta koneen omalla levyllä sijaitsevaan
/tmp-hakemistoon.
Tulokset näkyvät taulukosta 4, jonka ensimmäiset kaksi saraketta
ovat samat kuin taulukon 3 viimeiset.
Muistinkäytön lisääminen nopeuttaa selvästi pienehköjä tulosjoukkoja tuottavia yksinkertaisia sanahakuja (maksimissaan 40 %), mutta suurempien hakujen aikoihin sillä ei näytä olevan suurta vaikutusta. Työtiedostojen siirtäminen paikalliselle levylle ei tässä testissä vaikuttanut hakuaikoihin muuta kuin BEGINS-sanahaussa, jonka ajat putosivat laajempia tuloksia tuottavissa hauissa yllättäen alle puoleen!
| Tietueiden määrä | 60 000 (58 893) | 600 000 (588 930) | ||||||
| - | laaj. muistilla | + paik. levyllä | = | |||||
| A (ms) | B (ms) | A (ms) | B (ms) | A (ms) | B (ms) | A (ms) | B (ms) | |
| lehmä EXACT | 1355 | 237 | 821 | 171 | 814 | 180 | 6202 | 1089 |
| BEG | 1326 | 659 | 1197 | 452 | 1058 | 367 | 6425 | 2007 |
| CONT | 17059 | 17089 | 13147 | 11679 | 12986 | 11487 | 20754 | 14909 |
| END | 16989 | 13735 | 12820 | 11538 | 12853 | 11815 | 17357 | 13318 |
| se EXACT | 1480 | 669 | 1462 | 699 | 1462 | 682 | 13297 | 6819 |
| BEG | 7146 | 6130 | 7636 | 5789 | 3105 | 1821 | 21774 | 14735 |
| CONT | 40749 | 31346 | 32483 | 31047 | 33513 | 33101 | 57985 | 46015 |
| END | 15107 | 14279 | 15356 | 13713 | 14328 | 12624 | 28324 | 22415 |
| sig 117 & area 7. | 3588 | 2652 | 3574 | 2504 | 3435 | 2303 | 39252 | 29524 |
| sig 177 & area 7. & BEG tuommos |
3001 | 1961 | 2993 | 2028 | 1422 | 831 | 28930 | 20247 |
| PHRASE "n k" | 6282 | 5334 | 6248 | 5207 | 6241 | 5226 | 65011 | 60012 |
Kokeilin vielä lopuksi, mitä tapahtuisi, jos keinotekoisesti kymmenkertaistaisin aineiston kopioimalla jokaisen tietueen kymmeneksi. Raakaa XML-koodia tuli 83 MB, tämän indeksointiin kului yhteensä 244 min (yllättävän vähän!) ja tuloksena oli 206 MB eXistin tietokantadataa. Kyselyajat näkyvät taulukon 4 oikeanpuolimmaisista sarakkeista.
Monistettu aineisto ei ehkä anna aivan oikeaa kuvaa tietokannan käyttäytymisestä 600 000 tietueen aineistolla (esim. 60 000-aineistoon verraten sananmuotojen määrä ei kasva lainkaan ja toisaalta hakutulosten määrä kasvaa enemmän kuin normaaliaineistosta voisi olettaa), mutta ainakin se antaa suuntaa. Selvä trendi on, että nopeimmat haut (tarkat ja sananalkuhaut) hidastuvat eniten aineiston kasvaessa, mutta hakuaikojen kasvu on rajallista, siten että työläämpienkin hakujen ajat pysyvät vielä tällä aineistolla ja laitteistolla siedettävinä (kymmenissä sekunneissa).
Huomautettakoon vielä, että testien "signum ja murrealue" -kyselyssä
käytetty säännöllinen lauseke näyttää hidastavan hakua huomattavasti;
kun korvasin murrealue-ehdon "7." luettelolla
"7a 7b 7c 7d 7e 7f 7g 7h", hakuaika pieneni kolmannekseen.
Muuten on selvästi nähtävissä, että hakuajat ovat riippuvaisia
hakutulosten laajuudesta; esim. "se"-alkuisten sanojen haku, joita on
n. 188 000, kestää yli 15 sekuntia, kun taas vaikkapa
"hirnu"-alkuiset sanat, joita on 20, löytyvät reilussa sekunnissa.
Vaikka eXistin pohjalle rakennettu hakujärjestelmä vaikuttaa tällaisenaankin jokseenkin käyttökelpoiselta, löytyy siitä toki parannettavaakin. Ainakin seuraavat asiat pitäisi julkiseen käyttöön tarkoitettuun sovellukseen korjata:
Muita hyödyllisiä ominaisuuksia olisivat:
Välttämätöntä ei myöskään ole säilyttää hakusysteemin kokoonpanoa juuri tällaisena. Itse eXist-tietokanta on järjestelmän ytimenä sikäli itsenäinen, että sen voi periaatteessa helposti virittää yhteistyöhön muidenkin Internet-palvelinohjelmistojen kanssa kuin Tomcatin.
Bourret, Ronald 2001: XML and Databases. -- http://www.rpbourret.com/xml/XMLAndDatabases.htm [Luettu 15.1.2002]
Bourret, Ronald 2002: XML Database Products. -- http://www.rpbourret.com/xml/XMLDatabaseProds.htm [Luettu 2.4.2002]
Everson, Michael & Ruppel, Klaas & Trosterud, Trond 2002: Uralic Phonetic Alphabet characters for the UCS. -- http://std.dkuug.dk/jtc1/sc2/wg2/docs/n2419.pdf [Luettu 31.3.2002]
Graves, Mark 2002: Designing XML Databases. Prentice-Hall, Upper Saddle River, NJ.
Holzner, Steven 2001: Inside XML. Suomentanut Mari Nelimarkka. IT Press / Edita, Jyväskylä.
Iivonen, Antti & Sovijärvi, Antti & Aulanko, Reijo 1990: Foneettisen kirjoituksen kehitys ja nykytila: Kansainvälinen foneettinen aakkosto (IPA), suomalais-ugrilainen tarkekirjoitus (SUT). Helsingin yliopiston fonetiikan laitoksen monisteita 16.
Itkonen, Terho 1969: Muoto-opin keruuopas. Suomalaisen Kirjallisuuden Seura, Helsinki.
Itkonen, Terho ym. 1975: Muoto-opin keruuoppaan 1. lisävihko. Helsingin yliopiston suomen kielen laitos.
Itkonen, Terho ym. 1978: Muoto-opin keruuoppaan 2. lisävihko. Helsingin yliopiston suomen kielen laitos ja Kotimaisten kielten tutkimuskeskus, Helsinki.
Korpela, Jukka 2002: Characters and encodings [laajan sivuston hakemistosivu]. -- http://www.cs.tut.fi/%7Ejkorpela/chars/
Meier, Wolfgang M. 2002: eXist: Open Source XML Database. -- http://exist.sourceforge.net/
Ruini, Henri 2000: Englanti - suomi -sanasto, v. 0.7 [XML-sanasto]. -- http://www.cs.Helsinki.FI/u/ruini/structure/xml/sanasto.html
Sovijärvi, Antti & Peltola, Reino (toim.) 1977: Suomalais-ugrilainen tarkekirjoitus. Helsingin yliopiston fonetiikan laitoksen julkaisuja 9.
TEI Consortium 2001: Text Encoding Initiative. -- http://www.tei-c.org/
W3.org/XML -- http://www.w3.org/XML/
W3C XML 2000: Extensible Markup Language (XML) 1.0 (Second Edition). W3C Recommendation 6 October 2000. -- http://www.w3.org/TR/REC-xml
W3C XPath 1999: XML Path Language (XPath) Version 1.0. W3C Recommendation 16 November 1999. -- http://www.w3.org/TR/xpath
XML:DB Initiative for XML Databases. -- http://www.xmldb.org/
XML-RPC.org -- http://www.xml-rpc.org/