TILASTOLLISEN KUVAUKSEN PERUSTEET
(OSA 2)
5.2 Ristiintaulukoinnin käyttökelpoisuudesta pienissä tutkimuksissa
HUOM 1: Sivun sisällön tekemissä olen käyttänyt hyväksi Metsämuuronen, J. (2000). Metodologia - sarjaa. HUOM 2: En ole löytänyt kaikkia tilastollisia merkkejä tähän ohjelmaan, joten muutamat laskelmiin liittyvät kaaviot täytyy tarvittaessa etsiä alan menetelmäkirjallisuudesta. Esim. x pontenssiin 2 olen merkinnyt seuraavasti x'2
1. Yksiulotteisen aineiston tunnusluvut
Tilastollisen kuvauksen perusteet OSA 1 esitteli frekvenssijakauman ja graaffisen kuvaamisen. Yksi mahdollisuus on esittää myös frekvenssien esiintyminen prosentteina. Prosenttisia frekvenssejä voidaan pitää jakauman eräänlaisina tunnuslukuina, koska ne antavat tietoa muuttujan jakauman sijainnista ja useimmin esiintyvistä arvoista. Jakauman ominaisuuksien kuvaaminen prosenttijakauman avulla edellyttää kuitenkin kaikkien luokkien esittämistä. Usein on tarkoituksenmukaista tiivistää olemassaolevaa tietoa edelleen niin, että yhdellä ainoalla luvulla voidaan ilmaista jotain olennasita jakaumasta. Tällaista aineistosta laskettua lukua kutsutaan tunnusluvuksi.
Tunnusluku = aineistosta laskettu luku, jolla voidaan ilmaista jotain olennaista jakaumasta.
Tunnusluvut on mahdollista jakaa eri tyyppeihin, sen mukaan mistä jakauman ominaisuudesta ne esittävät tietoa: a) jakauman sijaintia (lukusuoralla) kuvaavat keskiluvut ja b) havaintoarvojen vaihtelua kuvaavat hajontaluvut.
Keskilukuja ovat moodi, mediaani ja aritmeettinen keskiarvo
Hajontalukuja ovat vaihteluvälin pituus, keskihajonta ja kvartiiliväli.
1.1 Esimerkkiaineisto
Tutustumme aineistoon, jonka perusteella on aikaisemmin suoritettu todellinen koe. Jako koe ja kontrolliryhmään on tehty Breuer-Weuffen testillä lasten ollessa esikouluiässä (koeryhmän oppilailla oli kahdessa tai useammassa osiossa miinustulos ja kontrolliryhmällä oli 0 virhettä) Taulukko 1.
Tarkastellaan taulukkoa. Ensinnäkin tällaista taulukkoa kutsutaan matriisiksi. Matriisillle on tunnusomaista, että siihen on koottu tiiviiseen muotoon numeerinen informaatio kyseisestä ilmiöstä. Matriisi muodostuu riveistä ja sarakkeista. Yhdellä rivillä on on yhden ja saman henkilön arvot. Yhdessä sarakkeessa on puolestaan yhden muuttujan saamat arvot kultakin vastaajalta. Matriisiin ylimmällä rivillä ei ole sarakkeita vaan ylimmällä rivillä ovat muuttujine nimet.
HUOM. Minun aineistossa nimien kohdalle olen kirjoittanut vain KOE- ja KONTROLLIRYMÄ lasten nimien suojaksi. Jako koe- ja kontrolliryhmään tapahtuu esimerkiksi ryhmätunnuksen (RT 1 tai 2) avulla.
Ensimmäisenä vasemmalta oikealle mentäessä (olen lihavoinut ne muuttujat, joita käytetään tämän sivun esimerkeissä) NO=numero, RT=ryhmätunnus, sukup=sukupuoli, s-kuu=syntymäkuukausi, akmkM=akateeminen minäkäsitys keskiarvo, 2.astekt=2.asteen koulutustoive.
Muistettavaa: tutkijan on syytä kirjoittaa ylös, joko kyselylomaketta laatiessaan itselleen ylös mitä ilmiötä kyseinen kysymys on ajateltu mittaavan tai viimeistään käytettävään tietokoneohjelmaan. Mikä tutkimusta tehdessä on selvää voi olla parin kuukauden päästä tutkimustuloksia koodatessa jo hieman epäselvää. Esim.omassa taulukossani ak=akteeminen, mk=minäkäsitys, M=mean eli keskiarvo (k.a.)
Raakamatriisissa on kaikki empiirinen tieto jokaisesta kohderyhmän yksilöstä. Tämä tieto tulee kuitenkin vielä usein tiivistää, jotta aineiston käsittely olisi mahdollista.
2. Frekvenssit ja prosentit
Frekvenssit
Tarkastellessamme esimerkkitutkimuksen lasten ikää huomaamme, että ikäjakauma (syntymäkuukausi) on saanut luonnollisesti useita eri arvoja (tammikuusta - joulukuuhun). On ehkä hyvä tarkastella syntymäkuukauden vaikutusta ryhmittelyyn, koska esikouluikäisten kehitykselliset erot voivat voivat olla yhteydessä syntymäkuukauteen, joka parhaimmillaan voi aiheuttaa lähestulkoon vuoden mittaisen kehityksellisen eron samassa esikouluryhmässä. Yksi tapa on tarkastella ikäjakaumaa suoraan syntymäkuukausien (=ikä) esiintymisen määrän eli frekvenssien (f) suhteen.
Syntymäkuukausien (kuukaudet voitaisiin tietysti ilmoittaa myös numeroina) frekvenssit taulukoituna Taulukon 1 perusteella:
Syntymäkuukausi ja frekvenssi:
Taulukko 2. Syntymäkuukausien frekvenssit (f) Taulukko 3. Syntymäkuukausien uudeelleen kookattu luokkafrekvenssi (lf) Tammikuu Kuukaudet 1-4 6 Helimikuu Kuukaudet 5-8 7 Maaliskuu Kuukaudet 9-12 5 Huhtikuu Toukokuu Kesäkuu Heinäkuu Elokuu Syyskuu Lokakuu Marraskuu Joulukuu
Nyt kun ikäjakauma on suhteellisen suuri voi aineistoa hieman tiivistää esimerkiksi ensimmäisenä vuosikolmanneksena syntyneet, 2.:na vuosikolmanneksena syntyneet, ja 3.:na vuosikolmanneksena syntyneet, jolloin saadaan aikaan frekvenssiluokkia. Ks. Taulukko 3.
Nyt saatu luokkafrekvenssi (lf) osoittaa, kuinka monta otoksesta kuuluu kuhinkin luokkaan.
Alkuperäisen aineiston informaatio on redusoitu (reduce) eli pelkistetty koeryhmän osalta kolmeen lukuun. Frekvenssiaineistoon liittyviä termejä luokan ylä- ja alarajan lisäksi ovat luokkakeskus, kumulatiivinen (eli keräytyvä) frekvenssi sekä frekvenssitaulukoihin usein liitettävät prosentit (Uudelleen luokittelu (2 -> 1, 3 ->1, 4 ->1 jne.) tapahtuu esimerkiksi SPSS-ohjelmassa työkalut rivin Transform -> Recode --> Into different variables -valikkojen kautta.(Into different variables tekee uuden luokkasarakkeen datamariisin jatkoksi).Prosentit
Prosenttien laskeminen on keskeinen toiminto kaikessa taulukoinnissa. Prosenttien lisäksi käytetään selventämiseksi usein myös termiä numerus eli lyhyemmin "n" tai "N". Numerus on koehenkilöiden yhteenlaskettu summa. Pientä n-kirjainta käytetään normaalisti osa-aineistosta, kuten tässä tapauksessa koe-ryhmästä (n=9) ja N-kirjainta puolestaan koko populaation määrästä (N=18).
3. Keskiluvut (keskiarvo, moodi, mediaani)
Keskiluvuilla tarkoitetaan sellaisia lukuja, joilla pyritään ilmaisemaan aineiston informaation yhdellä ainoalla luvulla eli keskiluvulla. Diskreettisten (luokittelu- ja järjestysasteikot) muuttujien ollessa kyseessä keskiluvut kuvaavat tyypillisintä ja yleisintä suuruutta ja jatkuvien (välimatka- ja suhdeasteikko) muuttujien tapauksessa havaintojen keskimääräistä sijaintia lukusuoralla.
Keskiluvut lyhesti määriteltynä:
Yleisin tunnettu keskiluku on aritmeettinen keskiarvo (merkitään x, M, k.a., A). Keskiarvo lasketaan summaamalla kaikki havaintoarvot yhteen ja jakamalla saatu summa havaintojen kokonaismäärällä (n).
Keskiarvo syntymäkuukausista (Taulukko 2)on (1+2+2+3+4+4+5+5+6+7+7+7+8+9+9+9+10+12)/18 = 110/18 = 6,1.
Joissakin tapauksissa keskiarvo on melko epätarkka tunnusluku aineistolle. Esimerkiksi, jos täytyy laske seuraavien henkilöiden ikien keskiarvo (12, 15, 20, 23 ja 80) huomataan, että (k.a = 30) ei kuvaa oikein hyvin kyseistä ryhmää.
Moodi (Mo) soveltuu kaikille asteikoille. Yleensä moodia käytetään käytetään luokitteluasteikkoisen muuttujan keskilukuna. Yksinkertaisesti Moodi on se tai ne havaintoarvot, jo(i)ta on eniten. Mikäli halutaan tietää, minkä muuttujan arvon frekvenssi on suurin, puhutaan moodista (Mo). Aineistossamme (Taulukko 2) ei yhtä selvää moodiluokkaa ollut vaan moodeja olivat 7 (heinäkuu) ja 9 (syyskuu). Aineiston moodiluokaksi, joka on syntynyt summamuuttujien muodossa (kts. Taulukko 3.) voidaan sen sijaan nimetä "Kuukaudet 5-8" eli 2. vuosineljänneksenä syntyneet.
Mediaani (Md) ei voida määritellä luokitteluasteoikon muuttujalle, mutta muuten se sitä voidaan käyttää kaikissa asteikkotyypeissä. Mediaani on suuruusjärjestyksessä olevan aineiston keskimmäisin arvo eli jakaa aineiston kahteen osaan. Näin mediaanin yläpuolelle ja alapuolelle jää 50% havainnoista. Kun havaintojen kokonaislukumäärä (n) on pariton, mediaani on keskimmäinen havaintoarvo. Kun havaintoja on parillinen määrä, mediaani on kaksi keskimmäistä lukua.
Luokitellussa aineistossa mediaani on ns. mediaaniluokka tai tämän luokan luokkakeskus, jos se on mahdollista laskea.
4. Hajontaluvut
Tärkeimmät ja käytetyimmät hajontaluvut ovat varianssi (s'2) ja tästä johdettu hajonta (s), jotka kuvaavat arvojen vaihtelua lasketun keskiarvon ympärillä. Yksinkertaisella esimerkillä voidaan osoittaa varianssin merkitys keskiarvon tarkkuuden mittana. Oletetaan kaksi erilaista aineistoa, joilla on sama keskiarvo. Esimerkeissä keskiarvo on merkitty vaa'an keskellä olevaksi kohdaksi (nolla). Kyseisiä aineistoja voidaan kuvata tilanteina 1 ja 2.
Esimerkki 1 Esimerkki 2
Esimerkissä 1 varianssi on pieni koska havainnot (6kpl) keskittyvät arvon 0 läheisyyteen. Esimerkissä 2 (sama keskiarvo) varianssi on taas selvästi suurempi koska havainnot ovat "kaukana" keskiarvosta. Varianssi (s'2) lasketaan vähentämällä keskiarvo (k.a) kustakin arvosta (xi), korottamalla saadut luvut toiseen potenssiin
('2 ), summaamalla kaikki keskipoikkeamat yhteen ja jakamalla (n-1):llä.Esimerissä käytetään edelleen syntymäkuukausi-arvoja. Aineistosta lasketun ikä-muuttujan (alkuperäisen syntymäkuukauden) varianssi lasketaan seuraavasti. a) taulukoidaan kaikki saadut arvot, b) lasketaan toiseen sarakkeeseen xi - k.a. Keskiarvo oli jo laskettu eli se oli 6.11, c) viimeisessä sarakkeessa korototetaan edellisessä sarakkeessa saatu tulos '2.
(HUOM: å viimeisellä rivillä tarkoittaa rivin summaa).
a b c xi xi-k.a. (xi - k.a)'2 1 -5.11 27.04 2 -4.11 16.89 2 -4.11 16.89 3 -3.11 9.67 4 -2.11 4.45 4 -2.11 4.45 5 -1.11 1.23 5 -1.11 1.23 6 0.11 0.01 7 0.89 0.79 7 0.89 0.79 7 0.89 0.79 8 1.89 3.57 9 2.89 8.35 9 2.89 8.35 9 2.89 8.35 10 3.89 15.13 12 5.89 34.69 å=110 å=162.67 Eli varianssi saadaan seuraavasti: 162.67/(18-1)= 9.56
Ikä muuttujan varianssi on siis 9.56. On luonnollista, että kuukauden olessa kyseessä on hajonta myös suuri eli luvuissa on suuria poikkeamia keskiarvosta. Toisin sanoen keskiarvo itsessään on osittain harhaanjohtava suure, joka vaatii rinnalleen hajontamitan (yleensä varianssin tai keskihajonnan) kuvaavaan poikkeamia tästä keskiarvosta.
Keskihajonta. Varianssin neliöjuuri on nimeltään keskihajonta (standard deviation = S.D.). Keskihajonnalla on merkittävä osuus normaalijakauman pistemäärien todennäköisyystarkasteluissa. Tässä tapauksessa keskihajonta on nelilöjuuri luvusta 9.56 eli 3.08. Esimerkiksi, oppilaiden koulukeskiarvoja vertaillessa varianssi on yleensä n. 0.5 - 1.00 ja keskihajonta 0.70 - 1.00. Hajontaluvut ovat siis riippuvaisia tutkittavasta kohteesa.
SPSS-tilasto-ohjelmalla k.a, varianssi ja keskihajonta saadaan selville esim. Analyze -> Descriptive statitistics --> Descriptives (tässä kohtaa oikea variaabelin eli muuttujan valinta) ---> Options ----> (Mean, variance, S.D).
Muita hajontalukuja ovat esim. vaihteluväli, joka ketoo pienimmäin ja suurimman arovn välin (vähemmän käytetty).

5. Ristiintaulukointi (Cross tabulation)
Ristiintaulukoinnin rakentaminen. Taulukoidaan aineistosta (Taulukko 1) kaksi muuttujaa yhtä aikaa. Esimerkkitapauksessa muuttujiksi valitaan Ryhmätunnus (RT) ja Ikä (aluksi voi laatia vaikka paperille taulukon pohjan)
Taulukko 4. Ristiintaulukointi syntymäkuukauden suhteen RT\S-KUU Kuukaudet 1-4 Kuukaudet 5-8 Kuukaudet 9-12 Yhteensä (n) KOER. 3 4 2 9 KONTR. 3 3 3 9 Yhteensä (n) 6 7 5 18 Tämän jälkeen lasketaan kunkin solun frekvenssi ja merkitään taulukkoon. Jatkoanalyysien kannalta oleellista on tietää kunkin rivin ja sarakkeen yhteenlaskettu frekvenssi. Näitä ristiintaulukon reunoille tulevia lukuja kutsutaan yhteisesti reunajakaumaksi. Lisäksi on hyödyllistä laskea kunkin solun prosenttuaaline osuus kaikista ryhmän havainnoista. Merkitään taulukkoon frekvenssit, reunajakaumat, rivi- (Row Percent) ja sarakeprosentit (Column Percent). Kts. Taulukko 5.
Ristiintaulukon etuihin kuuluu mm. se, että voidaan havainnollisesti nähdä mahdolliset yhteydet kahden muuttujan välillä. Käsitellyssä tapauksessa huomataan jo tässä vaiheessa, että iän ja ryhmän välisessä yhteydessä ei ole juurikaan eroja. Eli ryhmäjaottelun pohjana olleet erot Breur-Weuffen tuloksessa eivät näytä olevan lapsen syntymäkuukausista johtuvia (Huom. joissakin tutkimuksissa on saatu merkitseviä yhteyksiä tässä suhteessa).
Joskus yhteyksien huomaaminen voi olla vaikeaa ja tutkija voi yrittää nähdä jotain sellaista, mitä ei ehkä olekaan. Ristiintaulukointi voi auttaa löytämään mielenkiintoiset yhteydet muuttujien välillä.
Diktonominen ristiintaulukointi (di = kaksi)
Diktonomisen (eli vain kaksi arvoa saavien) muuttujien tarkastelu, erilaisuuden ja yhtäläisyyksien tarkastelu, on ristiintaulukoinnin avulla havainnollista. Esimerkkeinä ovat luokat, jotka muodostavat (tai joista voidaan muodostaa) kaksi vastakkaista luokkaa mm. sukupuoli, koeryhmät, osallistuminen - ei osallistuminen, tyytyväisyys - tyytymättömyys, positiivinen - negatiivinen. Diktonominen ristiintaulukointi (esim. luokanopettajat - erityisopettajat / tyytyväisyys - tyytymättömyys) on yksi yksinkertaisimmista menetelmistä mitata tai havainnollistaa yhteyttä kahden eri muuttujan välillä.
Myös parittomia Likert-scale-tyyppisistä (Valitse olitko kurssin antiin: tyytyväinen 1 2 3 4 tyytymätön) vastauksista voidaan muodostaa tiivistävällä kaksi luokkaa. Esim. rekoodamalla saadut arvot 1 ja 2 -> 1 osoittamaan tyytyväisyyttä ja 3 ja 4 -> 2 osoittamaan tyytymättömyyttä).
5.1 Ristiintaulukon analysointi (khiin neliö)
Ristiintaulukointi on ehkä helpoin tapa pyrkiä havaitsemaan mitattavissa olevaan yhteyttä kahden eri muuttujan välillä. Mikäli halutaan saada tarkkaa (tilastollista) tietoa mahdollisista ryhmien välisistä eroista voidaan ristiintaulukointiin liittää Khiin neliön (x2) -testi.
Khiin neliön testi kahden muuttujan välistä riippumattomuutta (Independence). Jokaisessa taulukon solussa tulee olla vähintään yksi alkio. x2 -testiä varten tutkijan tulee tietää reunajakaumat. Reunajakaumien perusteella lasketaan kullekin solulle ns. odotettu frekvenssi (E) eli expected frequency. Odotettu frekvenssi tarkoittaa reunajakaumien perusteella laskettavaa frekvenssiä siinä tapauksessa, että muuttujat olisvat tilastollisessa mielessä riippumattomat toisistaan.
E lasketaan seuraavanlaisesti
E = (solun rivin summa) * (solun sarkkeen summa) (kaikkien havaintojen summa) Tässä vaiheessa otetaan käyttöön uusi muuttuja mahdollisten ryhmien välisten erojen tarkasteluun. Tarkastellaan "todellista havaintomatriisia eräästä tutkimuksesta" eli koe ja kontrolliryhmän 2. asteen koulutustoiveita ristiintaulukoinnin ja khiin neliön avulla.
Seuraavassa laskutoimitus suoritetaan vaihe vaiheelta ilman tilastollisten ohjelmien käyttöä.
Ensimmäiseksi täytyy taulukkoon lisätä reunajakaumat:
Taulukko 6. Koe ja kontrolliryhmän toisen asteen koulutustoiveet
RT\2.asteen kt 1=lukio 2=ammatik. 3=en osaa sanoa n KOER. 1' 4''' 4'''''' 9 KONTR. 7'' 1'''' 1''''''' 9 n 8 5 5 18 Toiseksi jokaiselle solulle täytyy laskea Expected Frequency (E). Huom. solun paikallistamiseksi olen merkinnyt soluihin '-merkkejä, jotta aivoituksiani voidaan seurata. Eli solun ' E saadaan laskemalla 8*9/18 = 4.0, solun '' E on 8*9/18=4, solun ''' E on '5*9/18 =2.5, solun '''' E on 5*9/18=2.5, solun ''''' on 5*9/18=2.5, ja solun '''''' E on 5*9/18=2.5
Khiin neliön testisuure lasketaan seuraavasta kaavasta:
x2= å (O-E)'2 E å -merkki tarkoittaa summaa (summamerkki puuttuu). Koko lauseke tarkoittaa, että ensin laksetaan kunkin solun saama arvo (O-E) potenssiin '2, jaettuna E:ellä, minkä jälkeen summataan kaikki yhteen.
Kolmanneksi Khiin neliön testisuureen laskemiseksi laskimella tarvitaan samaan taulukkoon sekä lasketut E-arvot että saatu havaintojen määrä eli observed frequences (O), joka meillä on jo edellisessä taulukossa.
Taulukko 6. Koe ja kontrolliryhmän toisen asteen koulutustoiveet = Kontingenssitaulukko (O ja E mukana)
RT\2.asteen kt 1=lukio 2=ammatik. 3=en osaa sanoa n KOER. O=1
E=4
O=4
E=2.5
O=4
E=2.5
9 KONTR. O=7
E=4
O=1
E=2.5
O=1
E=2.5
9 n 8 5 5 18 Eli lasku menee seuravasti (laskut esitetty samassa järjestyksessä kuin em. E -laskelmissa).:
x2 = (1-4)'2 + (7-4)'2 + (4-2.5)'2 + (1-2.5)'2 + (4-2.5)'2 + (1-2.5)'2 4 4 2.5 2.5 2.5 2.5
x2 = (-3)'2 + (3)'2 + (1.5)'2 + (-1.5)'2 + (1.5)'2 + (-1.5)'2 4 4 2.5 2.5 2.5 2.5
x2 = 9 + 9 + 2.25 + 2.25 + 2.25 + 2.25 4 4 2.5 2.5 2.5 2.5
x2 = 2.02 + 2.02 + 0.9 + 0.9 + 0.9 + 0.9 x2 =
7.64
Neljänneksi: jotta saatua lukua voitaisiin arvioida täytyy vielä laskea testisuureelle vapausasteet: df (degrees of freedon), jotka saadaan seuraavast kaavasta.
Vapausasteiden laskeminen x2 -testissä:
df = (rivin solujen lukumäärä - 1) * (sarakkeiden solujen lukumäärä - 1)
eli tässä esimerkissä
df= (3-1) * (2-1) = 2 * 1 = 2
Eli vapausasteeksi (df) saatiin 2.
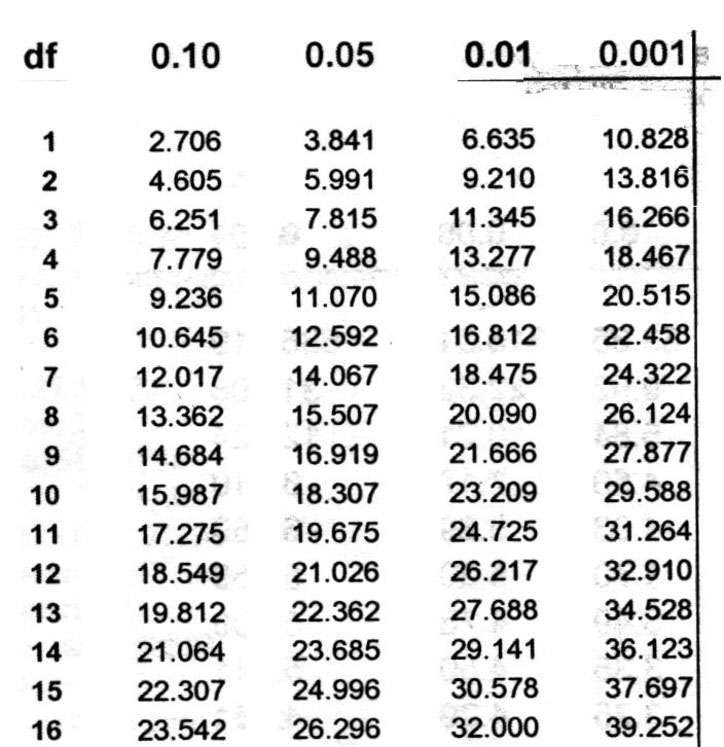
Lopuksi: Nyt tarvitaan lisäksi khiin neliön taulukkoa tuloksen mahdollisen merkitsevyyden selvittämiseksi Yleensä erilaisia taulukoita (t-, x2-, F-) löytyy yleensä useista tilastotieteen menetelmäkirjoista. Nyt voidaan kuitenkin käydä vilkaisemassa tuota mukaan oheen liitettyä x2-taulukkon osaa.
Vapausasteen (x2-taulukon vasemmassa laidassa) df 2 -kohdalta katsottuna voidaan huomata, että saatu luku on suurempi kuin 0.05 merkitsevyys-tasolle astettu arvo 5.991, mutta toisaalta pienempi kuin 0.01 merkitsevyys-tasolle asetettu arvo 9.210. Tulos tarkoittaa sitä, (jos väitetään, että muuttujat riippuvat toisistaa eli "koe ja kontrolliryhmän 2. asteen koulutustoiveet olisivat erilaisia") että virhepäätelmän taso on 5%. Tulos alittaa yleisen kasvatustieteissä käytettävän/hyväksyttävän virhetason (p < 0.05).
Tuloksen suhteen tilastollisesta "hyväksyttävästä" merkitsevyydestä ryhmien välillä voidaan siis puhua. Voidaan sanoa, että tulos on merkitsevä tasolla p. < 0.05. Hyvät pisteet Breuer-Weuffen -testissä esikouluiässä ovat tilastollisesti merkitsevästi yhteydessä toisen asteen koulutustoiveisiin, niin, että ne oppilaat, joilla on ollut useita miinuspisteitä näyttävät "toivovan" pääsyä toisen asteen ammatilliseen koulutukseen, kun taas oppilaat, jotka menestyivät hyvin em. testissä näyttävät "toivovan" lukiosijoittumista.
{kind=link}
5.2 Ristiintaulukoinnin käyttökelpoisuudesta pienissä tutkimuksissa
Ristiintaulukoinnin käyttö omassa työssä ei siis välttämättä vaadi tilastollisten tietojenkäsittelyohjelmien hallintaa. Otoskoko on kuitenkin suositelvaa olla yli 20. Esimerkiksi, -- yleisopetuksen luokkakoko (N=20), jossa tehdään jako tyttöihin ja poikiin ja astenteellinen kysymys "Miten suhtautudut vammaisten lasten sijoittamiseen yleiseen luokkaopetukseen?"
kielteisesti 1 2 3 4 myönteisesti -- voi riittää määrällisesti tilastollisesti merkitsevän ristiintaulukoinnin tekemiseen. Huom. myös ei-merkitsevät löydökset ovat tärkeitä tuloksia.Esimerkki Metsämuurosen kirjasta. Tutkimuksessa tutkittiin koe ja kontrolliryhmän välisiä eroja heidän "tyytyväisyyteensä tehdä aloitteita työpaikalla". Aineisto jakautui seuraavasti:
EI-tyyt. Tyytyv. yht. 2 13 6 9 yht. Tarkastelkaa onko kyseisen kahden muuttujan välillä tilastollista riippuvuutta.
Lisää tietoa ristiintaulukoinnista ja muista esillä olleista käsitteistä: Metsämuuronen, J. Metodologia - sarja. 2000.